
Heim >Datenbank >MySQL-Tutorial >Komplexe Abfrage der MySQL-Abfrageanweisung
Komplexe Abfrage der MySQL-Abfrageanweisung
- 赶牛上岸Original
- 2018-03-06 15:37:129198Durchsuche
MySQL ist ein relationales Datenbankverwaltungssystem. Eine relationale Datenbank speichert Daten in verschiedenen Tabellen, anstatt alle Daten in einem großen Lager abzulegen, was die Geschwindigkeit und Flexibilität erhöht. In MySQL gibt es häufig viele komplexe Abfragen. Um allen Zeit zu sparen, hat der Editor einige häufig verwendete komplexe Abfragen zusammengefasst.
Komplexe MySQL-Abfrage
1. Gruppenabfrage:
1. Schlüsselwort: GROUP VON
2. Verwendung: GRUPPE Die BY-Anweisung wird verwendet, um die Zusammenfassungsfunktion (z. B. SUM) zu kombinieren, um die Ergebnismenge nach einer oder mehreren Spalten zu gruppieren. Die Zusammenfassungsfunktion muss häufig hinzugefügt werden GROUP BY-Anweisung.
Die folgenden zwei Tabellen sind angegeben, eine ist emp und die andere ist dept werden wir die folgenden Abfragen für diese beiden Tabellen durchführen, wie unten gezeigt:
Erste Tabelle: empTabelle
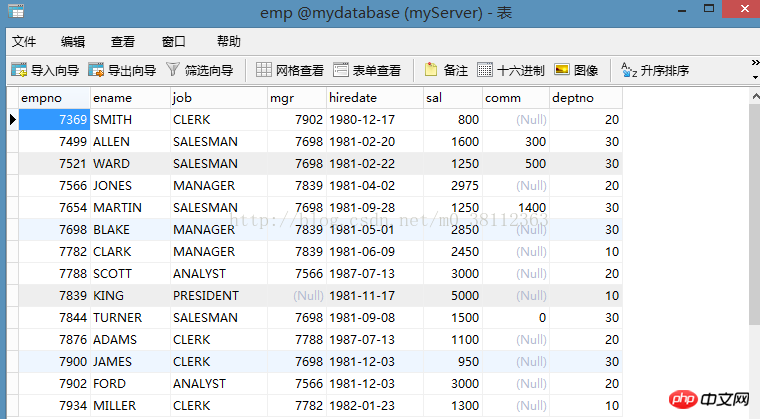
Zweites Blatt: AbteilungTabelle
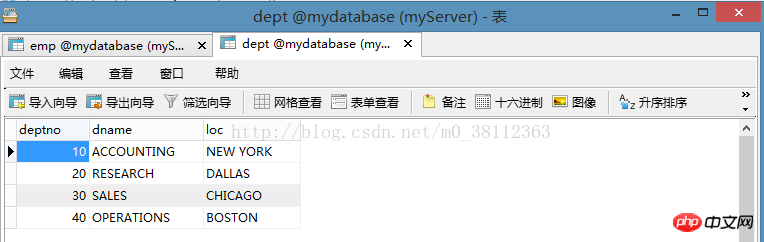
Jetzt fragen wir das Gesamtgehalt jeder Abteilung in emp ab, die Aussage lautet wie folgt:
SELECT deptno,SUM(sal)FROM emp GROUP VON Abteilungsnr.;
Die Ergebnisse sind wie folgt:
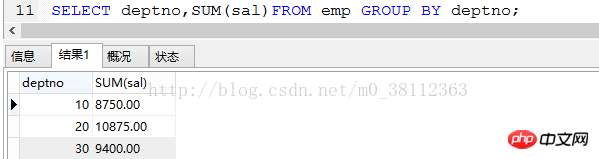
Hinweis: Hier fragen wir das Gesamtgehalt (sal) jeder Abteilung ab, daher sollte es nach der Abteilungsnummer (deptno), also Summe, gruppiert werden () wird für die Summe verwendet;
3. mit:
Where und habend fällen beide bedingte Urteile. Bevor wir einführen, werfen wir einen Blick auf den Unterschied zwischen wo und habend
Die Funktion von where besteht darin, die Zeilen zu entfernen, die die Where-Bedingung nicht erfüllen, bevor die Abfrageergebnisse gruppiert werden, d. h. die Daten werden vor dem Gruppieren gefiltert > Die Bedingung darf die Aggregatfunktion nicht enthalten. Verwenden Sie daher die Where-Bedingung. Zeigen Sie bestimmte Zeilen an.
have wird verwendet, um die Gruppen zu filtern, die die Bedingungen erfüllen, das heißt, die Daten nach der Gruppierung zu filtern. Bedingungen enthalten häufig Aggregatfunktionen , verwenden Bedingungen zeigen bestimmte Gruppen an, oder Sie können mithilfe mehrerer Gruppierungskriterien gruppieren.
Zum Beispiel: Wir wollen in der emp-Tabelle die Abteilungsnummern abfragen, deren Gesamtgehalt größer als 10.000 ist. Die Aussage lautet wie folgt:
AUSWÄHLEN deptno,SUM(sal)FROM emp GROUP BY deptno HAVING SUM(sal)>10000;
Die Ergebnisse sind wie folgt:

Auf diese Weise ist es Es wurde festgestellt, dass das Gesamtgehalt größer als 10.000 ist. Die Abteilungsnummer beträgt 20 (zum besseren Verständnis wird auch das Gesamtgehalt angezeigt).
2. Tabellenabfrage verbinden:
Gemäß zwei Die Beziehung zwischen Spalten in einer oder mehreren Tabellen, Abfragedaten aus diesen Tabellen
1 ):
Syntax: Feldname 1, Feldname 2 aus Tabelle 1 auswählen [INNER] Tabelle 2 beitreten EIN table1.Field name=table2.Field name;
Hinweis: Inner Joins werden aus den Ergebnissen gelöscht. Alle Zeilen, die keine übereinstimmenden Zeilen in anderen verbundenen Tabellen haben, können nur nach Informationen abgefragt werden, die den verbundenen Tabellen gehören, sodass innere Verknüpfungen möglicherweise Informationen verlieren und innere kann weggelassen werden.
Zum Beispiel: Wir verbinden zwei Tabellen emp und dept, fragen ename und deptno ab, die Anweisung lautet wie folgt:
SELECT emp.ename,dept.deptno FROM emp INNER JOIN dept ON emp.deptno=dept.deptno;
Auch eine Schreibweise: SELECT emp.ename,dept.deptno from emp,dept where emp.deptno=dept.deptno;
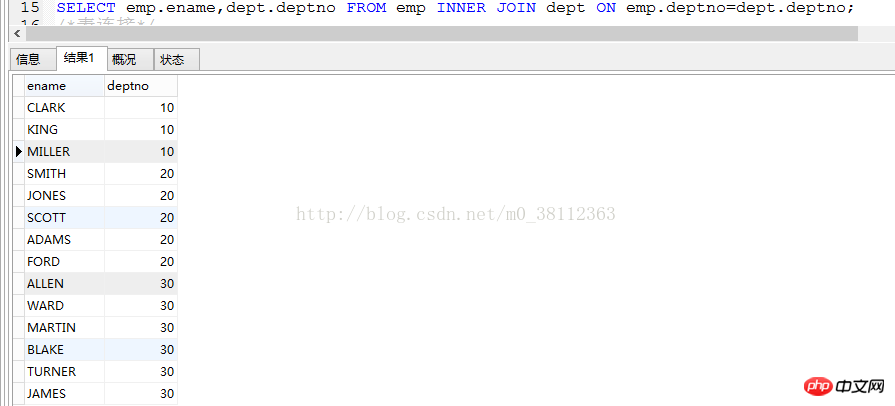
Hinweis: Es stellt sich heraus, dass in der Dept-Tabelle eine Deptno von 40 vorhanden ist, diese jedoch nach der Abfrage verschwunden ist. Dies liegt daran, dass im Feld Deptno in emp kein Wert von 40 vorhanden ist. Daher wird die Dept-Tabelle automatisch gelöscht, wenn Inner-Join-Datensätze mit einem Deptno-Feldwert von 40 verwendet werden.
2. Äußerer Join:
2.1: Linker äußerer Join: Die Ergebnismenge behält alle Zeilen aus der linken Tabelle bei, aber nur die Zeilen aus der zweiten Tabelle, die mit der ersten Tabelle übereinstimmen. Die entsprechenden leeren Zeilen der zweiten Tabelle werden in NULL-Werte gesetzt.
2.2: Rechter äußerer Join: Die Ergebnismenge behält alle Zeilen aus der rechten Tabelle bei, enthält aber nur Zeilen aus der zweiten Tabelle, die mit der ersten Tabelle übereinstimmen. Die entsprechenden leeren Zeilen der zweiten Tabelle werden in NULL-Werte gesetzt.
Left Outer Join und Right Outer Join können den gleichen Effekt erzielen, indem sie die Positionen der beiden Tabellen vertauschen.
Jetzt führen wir Abfragen durch, die Gruppierungen verwenden und Tabellen miteinander verbinden
Zum Beispiel: Wir möchten das Gesamtgehalt jeder Abteilung von emp abfragen und dem Abteilungsnamen in der Abteilungstabelle
Analysieren Sie diesen Satz: Das Abfragefeld ist sal (Gesamtgehalt) jeder Abteilung in emp. Gruppenabfrage wird hier jedoch auch der Abteilungsname (dname) der entsprechenden Abteilung abgefragt
befindet sich in der dept-Tabelle, daher sollten wir die emp- und dept-Tabellen verbinden.
Idee 1: Wir fragen zunächst alle Felder ab, die wir benötigen, bevor wir fortfahren Gruppieren, also zuerst verbinden und dann gruppieren, die Anweisung lautet wie folgt:
SELECT e.deptno,d.dname,SUM(e.sal) FROM emp e INNER JOIN dept d ON e.deptno= d.deptno GROUP BY d.deptno;) (Beachten Sie, dass hier
verwendet wird. Der Alias von emp ist e und der Alias von dept ist d)
Die zweite Schreibweise:
SELECT e.deptno,d.dname,SUM (e.sal) FROM emp e ,dept d WHEREe.deptno=d.deptno GROUP BY d.deptno;
Die Ergebnisse dieser beiden Schreibmethoden sind das Gleiche, wie folgt:

Idee 2: Wir möchten das Gesamtgehalt jeder Abteilung von emp abfragen und diese Ergebnismenge als Tabelle behandeln (hier Tabelle 1 genannt). ), und lassen Sie dann Tabelle 1 eine Verbindung zur Abteilungstabelle herstellen. Fragen Sie den entsprechenden Abteilungsnamen (dname) ab.
Schritt 1: SELECT deptno,SUM(sal) FROM emp GROUP BY deptno; Diese Anweisung fragt die emp-Tabelle ab. Das Gesamtgehalt jeder Abteilung in , jetzt verbinden wir es mit der dept
-Tabelle:
Schritt 2: SELECT xin.*,d .dname FROM(SELECT deptno,SUM(sal) FROM emp GROUP BY deptno) xin INNER JOIN dept d ON xin.deptno
=d.deptno ; Auf diese Weise können Sie das gewünschte Ergebnis abfragen. Beachten Sie, dass xin hier ein Alias ist. Das Ergebnis lautet wie folgt:

Der Code hier Sieht sehr lang aus, aber in Wirklichkeit ist die Idee sehr klar. Behandeln Sie einfach das erste Abfrageergebnis als eine Verbindung zu einer anderen Tabelle. Mit mehr Übung werden Sie bei dieser Idee keine Fehler machen.
3. Paginierung:Schlüsselwörter: LIMIT Syntax: * aus Tabellenname auswählen Bedingungsbegrenzung aktuelle Seitenzahl * Seitenkapazität - 1, Seitenkapazität; Allgemeines Limit wird zusammen mit der Reihenfolge von verwendet Zum Beispiel möchten wir 5-10 in der emp-Tabelle abfragen Aufsteigende Reihenfolge nach Abteilungsnummer. Auf jeder Seite werden 5 Datensätze angezeigt. Die Anweisung lautet wie folgt: SELECT *FROM emp ORDER BY deptno LIMIT 4,5; Auf diese Weise können Sie die gewünschten Ergebnisse abfragen. Beachten Sie, dass der letzte Parameter 5 die Seitenkapazität ist, also die Anzahl der auf dieser Seite anzuzeigenden Zeilen (d. h. die Aufnahmeleiste von der Anfangszeile bis zur Endzeile dieser Seite Nummer). Wenn wir beispielsweise 17 Seiten mit Datensätzen abfragen möchten, werden auf jeder Seite 10 Datensätze angezeigt: LIMIT 17*10-1,10; Vier: IN Stichwort: In Wenn das Rückgabewertergebnis der Unterabfrage mehr als eine Bedingung ist, muss IN verwendet werden und kann nicht verwendet werden"="; Hinweis: LIMIT steht am Ende . Verwandte Empfehlungen: So lösen Sie das Problem der fehlenden my.ini-Datei in MySQL5. 7 Eine Zusammenfassung der Ausführungsprobleme zwischen MySQL Max und Where Eine detaillierte Übersicht von MySQL-Statistiken
Das obige ist der detaillierte Inhalt vonKomplexe Abfrage der MySQL-Abfrageanweisung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!