
Heim >Datenbank >MySQL-Tutorial >Detaillierte Übersicht über MySQL-Statistiken
Detaillierte Übersicht über MySQL-Statistiken
- php中世界最好的语言Original
- 2018-03-05 16:12:542654Durchsuche
Dieser Artikel bietet einen umfassenden Überblick über die relevanten Wissenspunkte der statistischen MySQL-Informationen, indem er das Konzept der statistischen Informationen und die Vorteile der statistischen MYSQL-Informationen vorstellt. Ich hoffe, er kann Freunden in Not helfen.
MySQL durchläuft bei der Ausführung von SQL den Prozess der SQL-Analyse und Abfrageoptimierung. Der Parser zerlegt SQL in Datenstrukturen und übergibt sie an nachfolgende Schritte und erstellt einen Ausführungsplan. Der Abfrageoptimierer bestimmt, wie SQL ausgeführt wird, und zwar anhand der Statistiken der Datenbank. Im Folgenden stellen wir den relevanten Inhalt der Innodb-Statistiken in MySQL 5.7 vor.
Der MySQL-Statistikspeicher ist in zwei Typen unterteilt: nicht-persistente und persistente Statistiken.
1. Nicht-persistente statistische Informationen
Nicht-persistente statistische Informationen werden im Speicher gespeichert. Wenn die Datenbank neu gestartet wird, gehen die statistischen Informationen verloren. Es gibt zwei Möglichkeiten, nicht persistente Statistiken festzulegen:
| ||||||||||||||
|
2 Parameter der CREATE/ALTER-Tabelle, STATS_PERSISTENT=0 | ||||||||||||||
1 ANALYZE TABLE ausführen | ||||||||||||||
2 Wenn innodb_stats_on_metadata=ON, führen Sie SHOW TABLE STATUS, SHOW INDEX aus, fragen Sie TABLES unter INFORMATION_SCHEMA, STATISTICS ab | ||||||||||||||
3 Wenn die Funktion --auto-rehash aktiviert ist, melden Sie sich zum ersten Mal mit dem MySQL-Client an
|
||||||||||||||
4 Tabelle Geöffnet | ||||||||||||||
| ||||||||||||||
innodb_index_stats | |
database_name |
数据库名 |
table_name |
表名 |
index_name |
索引名 |
last_update |
统计信息最后一次更新时间 |
stat_name |
统计信息名 |
stat_value |
统计信息的值 |
sample_size |
采样大小 |
stat_description |
类型说明 |
| 1 INNODB_STATS_AUTO_RECALC=ON, 10 % der Daten in der Tabelle werden geändert |
| 2 Fügen Sie einen neuen Index hinzu |
| innodb_table_stats | |
| database_name | Datenbankname |
| Tabellenname | Tabellenname |
| last_update | Zeit der letzten Aktualisierung der Statistik |
| n_rows | Die Anzahl der Zeilen in der Tabelle |
| clustered_index_size | Die Anzahl der Seiten im Clustered-Index |
| sum_of_other_index_sizes | Andere Indexseiten Anzahl von |
| innodb_index_stats | |
| Datenbankname | Datenbankname td> |
| Tabellenname | Tabellenname |
| Indexname | Indexname |
| last_update | Zeitpunkt der letzten Aktualisierung der Statistik |
| stat_name | Statistikname | tr>
| Statistikwert | |
| sample_size | Stichprobengröße |
| stat_description | Typbeschreibung td> |
Um innodb_index_stats besser zu verstehen, erstellen Sie eine Testtabelle zur Erläuterung:
CREATE TABLE t1 ( a INT, b INT, c INT, d INT, e INT, f INT, PRIMARY KEY (a, b), KEY i1 (c, d), UNIQUE KEY i2uniq (e, f) ) ENGINE=INNODB;
Schreiben Sie die Daten wie folgt:
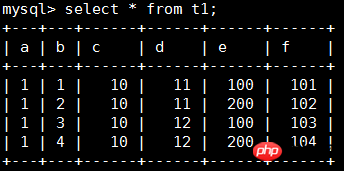
Um die statistischen Informationen der t1-Tabelle anzuzeigen, müssen Sie sich auf die Felder stat_name und stat_value konzentrieren
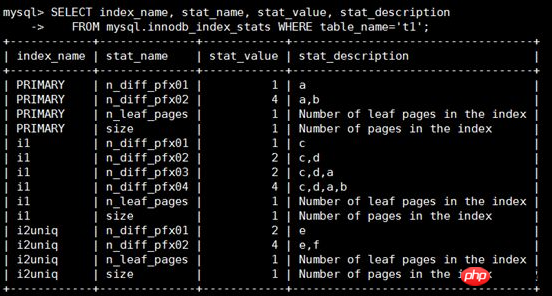
Wenn tat_name=size: stat_value angibt Anzahl der indizierten Seiten
Wenn stat_name=n_leaf_pages: stat_value die Anzahl der Blattknoten darstellt
Wenn stat_name=n_diff_pfxNN: stat_value die Anzahl der eindeutigen Werte im Indexfeld darstellt. Hier ist a Ausführliche Erklärung:
1. n_diff_pfx01 stellt die Zahl nach der ersten Spalte des Index dar. Spalte a von PRIMARY hat beispielsweise nur einen Wert 1, wenn also index_name='PRIMARY' und stat_name='. n_diff_pfx01', stat_value=1.
2. n_diff_pfx02 stellt die Zahl nach der Differenz der ersten beiden Spalten des Index dar. Beispielsweise haben die Spalten e und f von i2uniq 4 Werte, also wenn index_name='i2uniq' und stat_name='n_diff_pfx02 ', stat_value=4.
3. Bei nicht eindeutigen Indizes wird der Primärschlüsselindex nach den ursprünglichen Spalten hinzugefügt, z. B. index_name='i1' und stat_name='n_diff_pfx03', und die Primärschlüsselspalte a wird danach hinzugefügt Die ursprünglichen Indexspalten c und d (Das eindeutige Ergebnis von c, d, a) ist 2.
Das Verständnis der spezifischen Bedeutung von stat_name und stat_value kann uns bei der Fehlersuche helfen, warum beim Ausführen von SQL kein geeigneter Index verwendet wird. Beispielsweise ist der stat_value eines bestimmten Index n_diff_pfxNN viel kleiner als der tatsächliche Wert des Abfrageoptimierers hält den Index für selektiv. Wenn er schlecht ist, kann dies dazu führen, dass der falsche Index verwendet wird.
3. Umgang mit ungenauen statistischen Informationen
Wir haben den Ausführungsplan überprüft und festgestellt, dass nicht der richtige Index verwendet wurde. Wenn dies auf einen großen Unterschied in den statistischen Informationen in innodb_index_stats zurückzuführen ist, kann dies der Fall sein wie folgt gehandhabt werden:
1. Bitte beachten Sie, dass Lesesperren während der Ausführung hinzugefügt werden:
ANALYZETABLE TABLE_NAME;
2 Die statistischen Informationen sind nach der Aktualisierung immer noch ungenau. Erwägen Sie das Hinzufügen weiterer Daten. Die Datenseite der Tabellenstichprobe kann auf zwei Arten geändert werden:
a) Globale Variable INNODB_STATS_PERSISTENT_SAMPLE_PAGES, der Standardwert ist 20;
b) A Eine einzelne Tabelle kann die Stichprobe der Tabelle angeben:
ALTER TABLE TABLE_NAME STATS_SAMPLE_PAGES=40;
Nach dem Test beträgt der Maximalwert von STATS_SAMPLE_PAGES hier 65535. Wenn er überschritten wird, wird ein Fehler gemeldet .
Derzeit bietet MySQL keine Histogrammfunktion. In einigen Fällen (z. B. bei ungleichmäßiger Datenverteilung) führt die einfache Aktualisierung statistischer Informationen möglicherweise nicht zu einem genauen Ausführungsplan. Die neue Version 8.0 wird eine Histogrammfunktion hinzufügen. Freuen wir uns darauf, dass MySQL immer leistungsfähiger wird!
Verwandte Empfehlungen:
Beispielanalyse: statistisches Informationsmanagement, Spring-Annotation-Entwicklung und EasyUI
Das obige ist der detaillierte Inhalt vonDetaillierte Übersicht über MySQL-Statistiken. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!