
Heim >Web-Frontend >js-Tutorial >Eine kurze Einführung in React
Eine kurze Einführung in React

- 小云云Original
- 2018-02-28 13:22:481639Durchsuche
Dieser Artikel vermittelt Ihnen hauptsächlich den Ursprung und die Entwicklung von React. Ich hoffe, er kann Ihnen helfen.
Character Splicing Era – 2004
Im Jahr 2004 arbeitete Mark Zuckerberg noch in seinem Wohnheim an der Originalversion von Facebook.
In diesem Jahr nutzt jeder die String-Verkettungsfunktion von PHP, um Websites zu entwickeln.
$str = '<ul>';
foreach ($talks as $talk) {
$str += '<li>' . $talk->name . '</li>';
}
$str += '</ul>';
Diese Methode der Website-Entwicklung schien damals sehr richtig zu sein, denn egal, ob es sich um Back-End-Entwicklung oder Front-End-Entwicklung handelt, oder auch ohne Entwicklungserfahrung, Sie können diese Methode verwenden Erstellen Sie eine große Website.
Der einzige Nachteil besteht darin, dass diese Entwicklungsmethode leicht zu XSS-Injection und anderen Sicherheitsproblemen führen kann. Wenn $talk->name Schadcode enthält und keine Schutzmaßnahmen ergriffen werden, kann der Angreifer beliebigen JS-Code einschleusen. Daraus entstand die Sicherheitsregel „Vertraue niemals Benutzereingaben“.
Der einfachste Weg, damit umzugehen, besteht darin, alle Eingaben des Benutzers zu escape (Escape) zu machen. Dies bringt jedoch auch andere Probleme mit sich. Wenn die Zeichenfolge mehrmals mit Escapezeichen versehen wird, muss auch die Anzahl der Anti-Escapezeichen gleich sein, da sonst der ursprüngliche Inhalt nicht erhalten wird. Wenn Sie versehentlich das HTML-Tag (Markup) maskieren, wird das HTML-Tag dem Benutzer direkt angezeigt, was zu einer schlechten Benutzererfahrung führt.
XHP-Ära – 2010
Im Jahr 2010 entwickelte Facebook XHP, um effizienter zu programmieren und Fehler durch das Entkommen von HTML-Tags zu vermeiden. XHP ist eine Syntaxerweiterung für PHP, die es Entwicklern ermöglicht, HTML-Tags direkt in PHP zu verwenden, anstatt Strings zu verwenden.
$content = <ul />;
foreach ($talks as $talk) {
$content->appendChild(<li>{$talk->name}</li>);
}
In diesem Fall verwenden alle HTML-Tags eine andere Syntax als PHP, und wir können leicht unterscheiden, welche maskiert werden müssen und welche nicht.
Bald später entdeckten Facebook-Ingenieure, dass sie auch benutzerdefinierte Tags erstellen konnten und dass die Kombination benutzerdefinierter Tags beim Erstellen großer Anwendungen helfen würde.
Und das ist genau eine Umsetzung der Konzepte von Semantic Web und Web Components.
$content = <talk:list />;
foreach ($talks as $talk) {
$content->appendChild(<talk talk={$talk} />);
}
Danach versuchte Facebook weitere neue technische Methoden in JS, um die Verzögerung zwischen dem Client und dem Server zu reduzieren. Zum Beispiel browserübergreifende DOM-Bibliotheken und Datenbindung, aber keines davon ist ideal.
JSX – 2013
Warten Sie bis 2013, und plötzlich schlug Front-End-Ingenieur Jordan Walke seinem Manager eine mutige Idee vor: die erweiterten Funktionen von XHP auf JS zu migrieren. Zuerst dachten alle, er sei verrückt, weil es nicht mit dem JS-Framework kompatibel war, dem damals alle optimistisch gegenüberstanden. Doch schließlich überzeugte er seinen Manager, ihm sechs Monate Zeit zu geben, um die Idee zu testen. Ich muss hier sagen, dass die gute Philosophie des technischen Managements von Facebook bewundernswert und es wert ist, daraus zu lernen.
Anhang: Lee Byron spricht über die Facebook-Ingenieurkultur: Warum in Tools investieren
Um die erweiterten Funktionen von XHP auf JS zu migrieren, besteht die erste Aufgabe darin, eine Erweiterung zu benötigen, die JS ermöglicht unterstützt XML-Syntax. Die Erweiterung heißt JSX. Zu dieser Zeit, mit dem Aufkommen von Node.js, gab es bei Facebook bereits beträchtliche technische Praxis für die Konvertierung von JS. Die Implementierung von JSX war also ein Kinderspiel und dauerte nur etwa eine Woche.
const content = (
<TalkList>
{ talks.map(talk => <Talk talk={talk} />)}
</TalkList>
);
React
Seitdem hat der lange Marsch von React begonnen und größere Schwierigkeiten stehen noch bevor. Am schwierigsten ist es, den Update-Mechanismus in PHP zu reproduzieren.
In PHP müssen Sie bei jeder Datenänderung nur zu einer neuen, von PHP gerenderten Seite springen.
Aus Entwicklersicht ist die Entwicklung von Anwendungen auf diese Weise sehr einfach, da man sich nicht um Änderungen kümmern muss und alles synchronisiert wird, wenn sich Benutzerdaten auf der Schnittstelle ändern.
Solange es eine Datenänderung gibt, wird die gesamte Seite neu gerendert.
Obwohl diese Methode einfach und grob ist, ist auch der Nachteil dieser Methode besonders deutlich, nämlich dass sie sehr langsam ist.
„Man muss richtig sein, bevor man gut ist“ bedeutet, dass Entwickler zur Überprüfung der Machbarkeit des Migrationsplans schnell eine nutzbare Version implementieren müssen, unabhängig von vorerst auftretenden Leistungsproblemen.
DOM mit dem neuen DOM.
Diese Methode kann funktionieren, ist jedoch in einigen Szenarien nicht geeignet. Zum Beispiel gehen das aktuell fokussierte Element und der Cursor sowie die Textauswahl und die Seiten-Scroll-Position verloren, die den aktuellen Status der Seite darstellen. 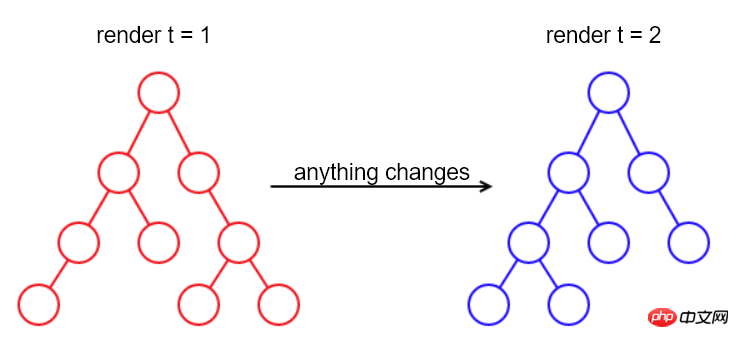 Mit anderen Worten, ein DOM-Knoten ist ein
Mit anderen Worten, ein DOM-Knoten ist ein
Wäre es nicht ausreichend, den Status des alten DOM aufzuzeichnen und ihn dann im neuen DOM wiederherzustellen, da es den Status enthält? Aber leider ist diese Methode nicht nur kompliziert in der Umsetzung, sondern kann auch nicht alle Situationen abdecken. Beim Scrollen der Seite auf einem OSX-Computer entsteht eine gewisse Scroll-Trägheit. Allerdings stellt JS keine entsprechende API zum Lesen oder Schreiben der Scroll-Trägheit bereit. Da die Wiederherstellung des Zustands nicht funktioniert, finden wir einen anderen Weg, dies zu umgehen. Solange Sie an diesem Punkt identifizierenkönnen, welche Knoten sich geändert haben, können Sie das DOM aktualisieren. Es stellt sich also die Frage, wie man die Unterschiede zwischen zwei DOMs vergleicht. Apropos Vergleichsunterschiede: Ich glaube, jeder kann sofort an Versionskontrolle (Versionskontrolle) denken. Das Prinzip ist sehr einfach. Zeichnen Sie mehrere Code-Snapshots auf und vergleichen Sie die beiden Snapshots dann mit dem Diff-Algorithmus, um eine Reihe von Änderungen zu generieren, z. B. „5 Zeilen löschen“, „3 Zeilen hinzufügen“, „Wörter ersetzen“ usw.; Durch Anwenden dieser Reihe von Änderungen auf den vorherigen Code-Snapshot, um den nachfolgenden Code-Snapshot zu erhalten. Das ist genau das, was React braucht, außer dass es mit dem DOM statt mit Textdateien funktioniert. DOM ist eine Baumstruktur, daher muss der Diff-Algorithmus auf der Baumstruktur basieren. Die Komplexität des derzeit bekannten vollständigen Baumstruktur-Diff-Algorithmus beträgt O(n^3). Wenn die Seite 10.000 DOM-Knoten enthält, mag diese Zahl riesig erscheinen, aber sie ist nicht unvorstellbar. Um die Größenordnung dieser Komplexität zu berechnen, gehen wir außerdem davon aus, dass wir einen einzelnen Vergleichsvorgang in einem CPU-Zyklus abschließen können (obwohl dies unmöglich ist) und dass die CPU mit 1 GHz getaktet ist. In diesem Fall beträgt die Zeit, die das Diff benötigt, wie folgt: Ganze 17 Minuten lang, was unvorstellbar ist! Obwohl die Verifizierungsphase vorerst keine Leistungsprobleme berücksichtigt, können wir dennoch kurz verstehen, wie der Algorithmus implementiert wird. Vergleichen Sie jeden Knoten im neuen Baum mit jedem Knoten im alten Baum Wenn die übergeordneten Knoten gleich sind, fahren Sie mit der Schleife fort und vergleichen Sie die Teilbäume Im Baum im obigen Bild finden Sie drei verschachtelte Knoten, die auf dem Prinzip der minimalen Operation basieren Schleifenvergleiche. Aber wenn Sie sorgfältig darüber nachdenken, gibt es in Webanwendungen nur sehr wenige Szenarien, in denen Sie ein Element an eine andere Stelle verschieben. Ein Beispiel könnte das Ziehen und Ablegen eines Elements an eine andere Stelle sein, aber das ist nicht üblich. Das einzige häufige Szenario ist das Verschieben von Elementen zwischen Unterelementen, z. B. das Hinzufügen, Löschen und Verschieben von Elementen in einer Liste. In diesem Fall können Sie nur Knoten auf derselben Ebene vergleichen. Wie in der Abbildung oben gezeigt, führen Sie Unterschiede nur bei Knoten derselben Farbe durch, wodurch die Zeitkomplexität auf O(n^2) reduziert wird. . Ein weiteres Problem wird für den Vergleich ähnlicher Elemente eingeführt. Das intuitivste Ergebnis besteht darin, die ersten beiden unverändert zu lassen und den dritten zu löschen. Was passiert, wenn Sie die Attribute des Elements hinzufügen? Wenn beispielsweise 那使用所有元素都有的 结合 前面说到,React 其实实现了对 DOM 节点的版本控制。 之所以有这么多属性,是因为 DOM 节点被用于浏览器渲染管道的很多过程中。 现在回过头来想想 React ,其实它只在 diff 算法中用到了 DOM 节点,而且只用到了标签名称和部分属性。 其过程如下: 维护一个使用 JS 对象表示的 Virtual DOM,与真实 DOM 一一对应 对前后两个 Virtual DOM 做 diff ,生成变更(Mutation) 把变更应用于真实 DOM,生成最新的真实 DOM 可以看出,因为要把变更应用到真实 DOM 上,所以还是避免不了要直接操作 DOM ,但是 React 的 diff 算法会把 DOM 改动次数降到最低。 至此,React 的两大优化:diff 算法和 Virtual DOM ,均已完成。再加上 XHP 时代尝试的数据绑定,已经算是一个可用版本了。 React 的开源可谓是一石激起千层浪,社区开发者都被这种全新的 Web 开发方式所吸引,React 因此迅速占领了 JS 开源库的榜首。 接下来要说的两大优化就是来自于开源社区。 著名浏览器厂商 Opera 把重排和重绘(Reflow and Repaint)列为影响页面性能的三大原因之一。 我们说 DOM 是很慢的,除了前面说到的它的复杂和庞大,还有另一个原因就是重排和重绘。 当 DOM 被修改后,浏览器必须更新元素的位置和真实像素; 另外,由于浏览器本身对 DOM 操作进行了优化,比如把两次很近的“修改”操作合并成一个“修改”操作。 与此同时,常规的 JS 写法又很容易触发重排和重绘。 Am Ende nutzte Community-Mitarbeiter Ben Alpert die Stapelverarbeitung, um diese peinliche Situation zu retten. In React teilen Entwickler React mit, dass sich die aktuelle Komponente ändern wird, indem sie die Ben Alperts Ansatz besteht darin, die Änderungen nicht sofort beim Aufruf von Nachdem das Initialisierungsereignis vollständig übertragen wurde, beginnt der erneute Rendering-Prozess (Re-Render) von oben nach unten. Dadurch wird sichergestellt, dass React das Element nur einmal rendert. Zwei Punkte sollten hier beachtet werden: Das erneute Rendern bezieht sich hier auf die Synchronisierung der Im Gegensatz zum oben erwähnten „Neu-Rendering des gesamten DOM“ wird beim echten Neu-Rendering nur das markierte Element und seine Unterelemente gerendert, also nur das Blau Element im obigen Bild ist. Elemente, die durch farbige Kreise dargestellt werden, werden neu gerendert Dies erinnert Entwickler auch daran, dass zustandsbehaftete Komponenten so nah wie möglich an Blattknoten gehalten werden sollten , was die Anzahl der erneuten Renderings verringern kann. Wenn die Anwendung größer wird, verwaltet React immer mehr Komponentenzustände, was bedeutet, dass auch der Umfang des erneuten Renderns immer größer wird. Wenn Sie den oben genannten Stapelverarbeitungsprozess sorgfältig beobachten, können Sie feststellen, dass sich die drei Elemente in der unteren rechten Ecke des virtuellen DOM nicht wirklich geändert haben, sondern dass die Änderung ihrer übergeordneten Knoten auch zu einem erneuten Rendern geführt hat. Es ist sinnlos, mehr Arbeit zu leisten. Für diese Situation hat React selbst dies bereits berücksichtigt und stellt die Obwohl React zu diesem Zeitpunkt die Der Grund dafür ist, dass wir in JS normalerweise Objekte zum Speichern des Status verwenden und beim Ändern des Status das Statusobjekt direkt ändern. Mit anderen Worten, zwei unterschiedliche Zustände vor und nach der Änderung verweisen auf dasselbe Objekt. Wenn also direkt verglichen wird, ob sich zwei Objekte geändert haben, sind sie gleich, auch wenn sich der Zustand geändert hat. In diesem Zusammenhang schlug David Nolen eine Lösung vor, die auf einer unveränderlichen Datenstruktur basiert. David hat ClojureScript verwendet, um eine unveränderliche Datenstrukturlösung für React: Om zu schreiben, die eine Standardimplementierung für Da unveränderliche Datenstrukturen jedoch von Webentwicklern nicht allgemein akzeptiert wurden, wurde diese Funktion zu diesem Zeitpunkt nicht in React integriert. Wenn Sie wirklich unveränderliche Datenstrukturen verwenden möchten, um die Leistung von React zu verbessern, können Sie sich an Facebook Immutable.js wenden, das aus derselben Schule wie React stammt. Es ist ein guter Partner von React! Die Optimierung von React geht noch weiter. Beispielsweise wird Fiber in React 16 neu eingeführt. Es handelt sich um eine Rekonstruktion des Kernalgorithmus, also der Methode und des Timings der Erkennung Änderungen werden neu gestaltet, sodass der Rendervorgang in Segmenten und nicht auf einmal durchgeführt werden kann. Verwandte Empfehlungen: Detaillierte Erläuterung des Lebenszyklus von React-Komponenten Detaillierte Erläuterung der von React gesteuerten und unkontrollierten Komponenten Ein Beispiel für das Schreiben einer Paging-Komponente mit React
Bei Seiten, die iframe enthalten, ist die Situation komplizierter. Wenn es von einer anderen Domäne stammt, können wir aufgrund der Einschränkungen der Browser-Sicherheitsrichtlinien den darin enthaltenen Inhalt überhaupt nicht anzeigen, geschweige denn wiederherstellen.
Es ist also ersichtlich, dass das DOM nicht nur einen Status hat, sondern auch einen versteckten, nicht erreichbaren Status.
Bei unveränderten DOM-Knoten lassen Sie diese unverändert und erstellen und ersetzen Sie nur die geänderten DOM-Knoten.
Diese Methode implementiert die DOM-Knoten-Wiederverwendung (Wiederverwendung). Diff
Kein Wunder, dass jemand sagte: „Ich neige dazu, mir React als Versionskontrolle für das DOM vorzustellen.“ 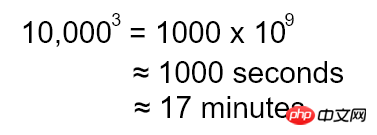
Anhang: Vollständiger Tree-Diff-Implementierungsalgorithmus.
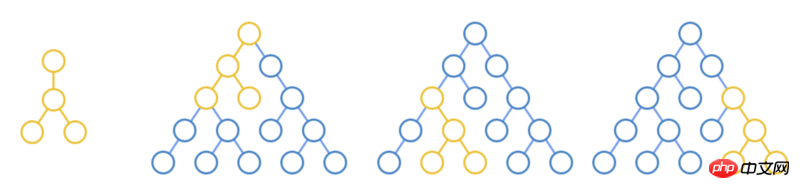
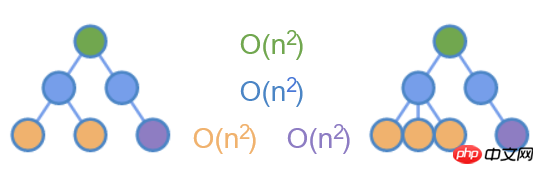
Schlüssel

Wenn die Namen von Elementen auf derselben Ebene unterschiedlich sind, können sie direkt als Nichtübereinstimmung identifiziert werden. Wenn sie gleich sind, ist das nicht so einfach.
Angenommen, unter einem bestimmten Knoten wurden beim letzten Mal drei <input /> und beim nächsten Mal zwei gerendert. Was wird zu diesem Zeitpunkt das Ergebnis von diff sein?
Natürlich können Sie auch den ersten löschen und die letzten beiden behalten.
Wenn Ihnen die Mühe nichts ausmacht, können Sie alle drei alten Elemente löschen und zwei neue Elemente hinzufügen.
Dies zeigt, dass wir für Knoten mit demselben Labelnamen nicht genügend Informationen haben, um die Unterschiede vorher und nachher zu vergleichen. 
value die Tag-Namen und value-Attribute vorher und nachher zweimal identisch sind, gelten die Elemente als übereinstimmend und es sind keine Änderungen erforderlich. Die Realität ist jedoch, dass dies nicht funktioniert, da sich der Wert ständig ändert, wenn der Benutzer eingibt, was dazu führt, dass das Element ständig ersetzt wird, was dazu führt, dass es den Fokus verliert. Schlimmer noch: Nicht alle HTML-Elemente verfügen über dieses Attribut . 
id 属性呢?这是可以的,如上图,我们可以容易的识别出前后 DOM 的差异。考虑表单情况,表单模型的输入通常跟 id 关联,但如果使用 AJAX 来提交表单的话,我们通常不会给 input 设置 id 属性。因此,更好的办法是引入一个新的属性名称,专门用来辅助 diff 算法。这个属性最终确定为 key 。这也是为什么在 React 中使用列表时会要求给子元素设置 key 属性的原因。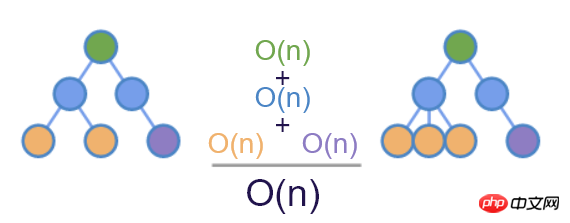
key ,再加上哈希表,diff 算法最终实现了 O(n) 的最优复杂度。
至此,可以看到从 XHP 迁移到 JS 的方案可行的。接下来就可以针对各个环节进行逐步优化。附:详细的 diff 理解:不可思议的 react diff 。
持续优化
Virtual DOM
做过 JS 应用优化的人可能都知道,DOM 是复杂的,对它的操作(尤其是查询和创建)是非常慢非常耗费资源的。看下面的例子,仅创建一个空白的 p,其实例属性就达到 231 个。// Chrome v63
const p = document.createElement('p');
let m = 0;
for (let k in p) {
m++;
}
console.log(m); // 231
浏览器首先根据 CSS 规则查找匹配的节点,这个过程会缓存很多元信息,例如它维护着一个对应 DOM 节点的 id 映射表。
然后,根据样式计算节点布局,这里又会缓存位置和屏幕定位信息,以及其他很多的元信息,浏览器会尽量避免重新计算布局,所以这些数据都会被缓存。
可以看出,整个渲染过程会耗费大量的内存和 CPU 资源。
如果用更轻量级的 JS 对象来代替复杂的 DOM 节点,然后把对 DOM 的 diff 操作转移到 JS 对象,就可以避免大量对 DOM 的查询操作。这种方式称为 Virtual DOM 。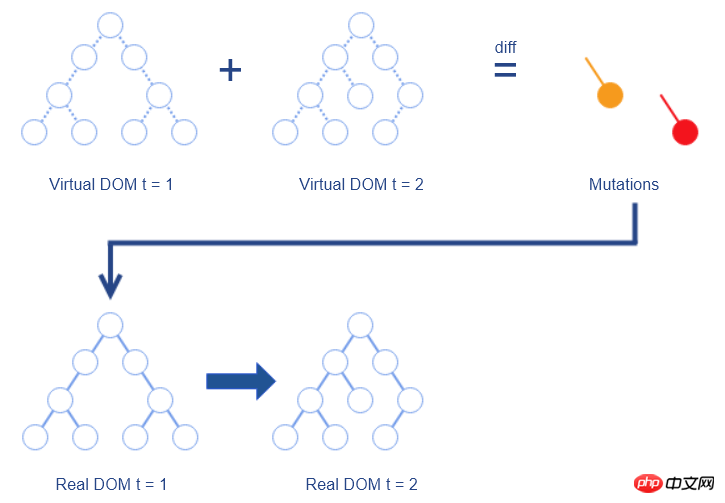
这个时候 Facebook 做了个重大的决定,那就是把 React 开源!
很多大公司也把 React 应用到生产环境,同时也有大批社区开发者为 React 贡献了代码。批处理(Batching)
当尝试从 DOM 读取属性时,为了保证读取的值是正确的,浏览器也会触发重排和重绘。
因此,反复的“读取、修改、读取、修改...”操作,将会触发大量的重排和重绘。
所以如果把“读取、修改、读取、修改...”重新排列为“读取、读取...”和“修改、修改...”,会有助于减小重排和重绘的次数。但是这种刻意的、手动的级联写法是不安全的。
在减小重排和重绘的道路上,React 陷入了尴尬的处境。setState-Methode der Komponente aufrufen. 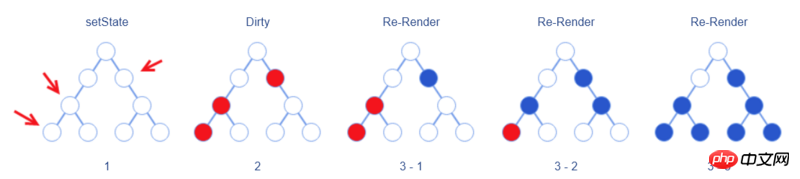
setState mit dem Virtual DOM zu synchronisieren, sondern nur das entsprechende Element als „zu markieren“ Warten auf die Markierung „Aktualisieren“. Wenn setState in der Komponente mehrmals aufgerufen wird, wird derselbe Markierungsvorgang ausgeführt.
setState Änderungen mit dem virtuellen DOM, erst dann wird die Diff-Operation ausgeführt um die echten DOM-Änderungen zu generieren. Bereinigung
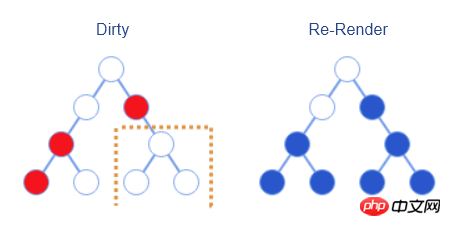
bool shouldComponentUpdate(nextProps, nextState)-Schnittstelle dafür bereit. Entwickler können diese Schnittstelle manuell implementieren, um den Vorher- und Nachher-Status und die Eigenschaften zu vergleichen und so festzustellen, ob ein erneutes Rendern erforderlich ist. In diesem Fall erfolgt das erneute Rendern wie in der folgenden Abbildung dargestellt. 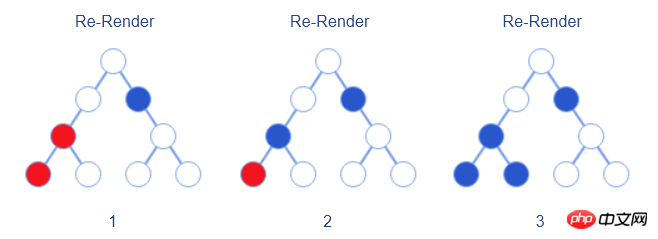
shouldComponentUpdate-Schnittstelle bereitstellte, stellte es keine Standardimplementierung bereit (die Entwickler mussten immer rendern). Sie müssen dies manuell tun, um den gewünschten Effekt zu erzielen.
Diese Lösung ist von ClojureScript inspiriert, wo die meisten Werte unveränderlich sind. Mit anderen Worten: Wenn ein Wert aktualisiert werden muss, ändert das Programm nicht den ursprünglichen Wert, sondern erstellt einen neuen Wert basierend auf dem ursprünglichen Wert und verwendet dann den neuen Wert für die Zuweisung. shouldComponentUpdate bereitstellt.
Leider bietet shouldComponentUpdate derzeit noch keine Standardimplementierung.
Aber David hat Entwicklern eine gute Forschungsrichtung eröffnet. Fazit
Aus Platzgründen wird Fiber in diesem Artikel nicht ausführlich vorgestellt. Interessierte können sich auf „Was React Fiber ist“ beziehen.
Das obige ist der detaillierte Inhalt vonEine kurze Einführung in React. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Eine eingehende Analyse der Bootstrap-Listengruppenkomponente
- Detaillierte Erläuterung des JavaScript-Funktions-Curryings
- Vollständiges Beispiel für die Generierung von JS-Passwörtern und die Erkennung der Stärke (mit Download des Demo-Quellcodes)
- Angularjs integriert WeChat UI (weui)
- Wie man mit JavaScript schnell zwischen traditionellem Chinesisch und vereinfachtem Chinesisch wechselt und wie Websites den Wechsel zwischen vereinfachtem und traditionellem Chinesisch unterstützen – Javascript-Kenntnisse