
Heim >Web-Frontend >js-Tutorial >Wie Web-Technologie mobile Überwachung realisiert
Wie Web-Technologie mobile Überwachung realisiert

- 小云云Original
- 2018-02-09 13:27:111771Durchsuche
In diesem Artikel wird hauptsächlich vorgestellt, wie Web-Technologie Bewegungsüberwachung und Bewegungserkennung, allgemein auch Bewegungserkennung genannt, realisieren kann, die häufig für unbeaufsichtigte Überwachungsvideos und automatische Alarme verwendet wird. Die von der Kamera mit unterschiedlichen Bildraten gesammelten Bilder werden von der CPU nach einem bestimmten Algorithmus berechnet und verglichen. Wenn sich das Bild ändert, z. B. wenn jemand vorbeigeht und das Objektiv bewegt wird, wird die aus den Berechnungs- und Vergleichsergebnissen resultierende Zahl geändert Überschreiten Sie den Schwellenwert und geben Sie an, dass das System die entsprechende Verarbeitung automatisch durchführen kann
Einführung in die mobile Überwachung mithilfe der Web-Technologie
Aus dem obigen Zitat kann geschlossen werden, dass „mobil „Überwachung“ erfordert die folgenden Elemente:
Ein Computer mit einer Kamera wird verwendet, um die Bewegung des Algorithmus zu bestimmen. Verarbeitung nach der Bewegung
Hinweis: Alle in diesem Artikel behandelten Fälle sind Basierend auf den neueren Versionen der Chrome-/Firefox-Browser auf PC/Mac. In einigen Fällen müssen alle Screenshots mit der Kamera lokal gespeichert werden.
Die andere Partei will nicht mit dir reden und wirft dir einen Link zu:
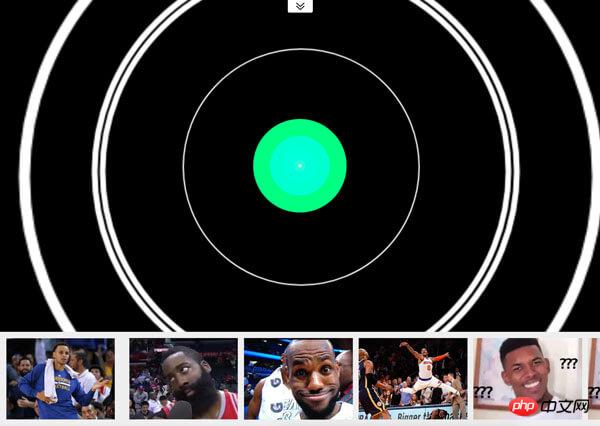
Umfassende Hülle
Diese Hülle hat die folgenden zwei Funktionen:
Das Foto wird 1 Sekunde nach der Aufnahme des POST aufgenommen und die Musik stoppt nach 1 Sekunde Stille. Bei Bewegung wird der Wiedergabezustand wieder aufgenommen
Der obige Fall spiegelt möglicherweise nicht direkt die tatsächliche Wirkung und das Prinzip der „mobilen Überwachung“ wider.
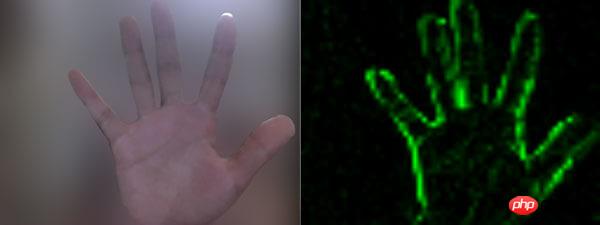
Pixelunterschied
Die linke Seite des Gehäuses ist die Videoquelle, während die Auf der rechten Seite handelt es sich um die Pixelverarbeitung nach der Bewegung (Pixelierung, Beurteilung der Bewegung und Beibehaltung von nur Grün usw.).
Da es auf Web-Technologie basiert, verwendet die Videoquelle WebRTC und die Pixelverarbeitung Canvas.
Videoquelle
Verlässt sich nicht auf Flash oder Silverlight, wir verwenden die navigator.getUserMedia() API in WebRTC (Web Real-Time Communications), die Web ermöglicht Anwendungen Holen Sie sich die Kamera- und Mikrofon-Streams des Benutzers.
Der Beispielcode lautet wie folgt:
<!-- 若不加 autoplay,则会停留在第一帧 -->
<video id="video" autoplay></video>
// 具体参数含义可看相关文档。
const constraints = {
audio: false,
video: {
width: 640,
height: 480
}
}
navigator.mediaDevices.getUserMedia(constraints)
.then(stream => {
// 将视频源展示在 video 中
video.srcObject = stream
})
.catch(err => {
console.log(err)
})Aus Kompatibilitätsgründen beginnt Safari 11 mit der Unterstützung von WebRTC. Weitere Informationen finden Sie unter caniuse.
Pixelverarbeitung
Nachdem wir die Videoquelle erhalten haben, verfügen wir über das Material, um festzustellen, ob sich das Objekt bewegt. Natürlich wird hier kein erweiterter Erkennungsalgorithmus verwendet, sondern lediglich der Pixelunterschied zwischen zwei aufeinanderfolgenden Screenshots, um festzustellen, ob sich das Objekt bewegt hat (streng genommen handelt es sich um eine Veränderung im Bild).
Screenshots
Beispielcode zum Erhalten von Screenshots der Videoquelle:
const video = document.getElementById('video')
const canvas = document.createElement('canvas')
const ctx = canvas.getContext('2d')
canvas.width = 640
canvas.height = 480
// 获取视频中的一帧
function capture () {
ctx.drawImage(video, 0, 0, canvas.width, canvas.height)
// ...其它操作
}Erkennen Sie den Unterschied zwischen Screenshots Unterschied
Für den Pixelunterschied zwischen den beiden Bildern gilt die in diesem Blogbeitrag erwähnte „Pixelerkennung“-Kollision „Warte mal, lass mich berühren! – Gemeinsame 2D-Kollisionserkennung“ von Alveolar Lab Algorithms eine Lösung. Dieser Algorithmus ermittelt, ob eine Kollision vorliegt, indem er prüft, ob die Transparenz der Pixel an derselben Position auf zwei Leinwänden außerhalb des Bildschirms gleichzeitig größer als 0 ist. Natürlich müssen wir es hier ändern, um festzustellen, ob die Pixel an derselben Position unterschiedlich sind (oder ob der Unterschied unter einem bestimmten Schwellenwert liegt).
Aber die obige Methode ist etwas umständlich und ineffizient. Hier verwenden wir ctx.globalCompositeOperation = 'difference', um die Synthesemethode neuer Elemente auf der Leinwand anzugeben (d. h. den zweiten Screenshot und den ersten Screenshot), um den Unterschied zwischen ihnen zu ermitteln zwei Screenshots Teil.
Erlebnislink>>
Beispielcode:
function diffTwoImage () {
// 设置新增元素的合成方式
ctx.globalCompositeOperation = 'difference'
// 清除画布
ctx.clearRect(0, 0, canvas.width, canvas.height)
// 假设两张图像尺寸相等
ctx.drawImage(firstImg, 0, 0)
ctx.drawImage(secondImg, 0, 0)
}
Unterschied zwischen den beiden Bildern
Nachdem Sie den oben genannten Fall erlebt haben, haben Sie Lust, das „QQ-Spiel „Let's Find the Difference““ von damals zu spielen? Darüber hinaus kann dieser Fall auch auf die folgenden zwei Situationen zutreffen:
-
Wenn Sie den Unterschied zwischen den beiden Designentwürfen, die Ihnen der Designer vorher und nachher gegeben hat, nicht kennen
Wenn Sie den Unterschied in der Darstellung derselben Webseite durch zwei Browser sehen möchten, handelt es sich um eine „Aktion“
Durch das Obige „ Fall „Zwei Bilder unterscheiden sich“ Von der Mitte aus erhalten: Schwarz bedeutet, dass sich das Pixel an dieser Position nicht geändert hat. Je heller das Pixel, desto größer ist die „Bewegung“ an diesem Punkt. Wenn also nach der Kombination zweier aufeinanderfolgender Screenshots helle Pixel vorhanden sind, handelt es sich um die Generierung einer „Aktion“. Um das Programm jedoch weniger „empfindlich“ zu machen, können wir einen Schwellenwert festlegen. Wenn die Anzahl der hellen Pixel den Schwellenwert überschreitet, wird davon ausgegangen, dass eine „Aktion“ stattgefunden hat. Natürlich können wir auch „nicht hell genug“ Pixel eliminieren, um den Einfluss äußerer Umgebungen (wie Lichter etc.) weitestgehend zu vermeiden.
想要获取 Canvas 的像素信息,需要通过 ctx.getImageData(sx, sy, sw, sh),该 API 会返回你所指定画布区域的像素对象。该对象包含 data、width、height。其中 data 是一个含有每个像素点 RGBA 信息的一维数组,如下图所示。

含有 RGBA 信息的一维数组
获取到特定区域的像素后,我们就能对每个像素进行处理(如各种滤镜效果)。处理完后,则可通过 ctx.putImageData() 将其渲染在指定的 Canvas 上。
扩展:由于 Canvas 目前没有提供“历史记录”的功能,如需实现“返回上一步”操作,则可通过 getImageData 保存上一步操作,当需要时则可通过 putImageData 进行复原。
示例代码:
let imageScore = 0
const rgba = imageData.data
for (let i = 0; i < rgba.length; i += 4) {
const r = rgba[i] / 3
const g = rgba[i + 1] / 3
const b = rgba[i + 2] / 3
const pixelScore = r + g + b
// 如果该像素足够明亮
if (pixelScore >= PIXEL_SCORE_THRESHOLD) {
imageScore++
}
}
// 如果明亮的像素数量满足一定条件
if (imageScore >= IMAGE_SCORE_THRESHOLD) {
// 产生了移动
}在上述案例中,你也许会注意到画面是『绿色』的。其实,我们只需将每个像素的红和蓝设置为 0,即将 RGBA 的 r = 0; b = 0 即可。这样就会像电影的某些镜头一样,增加了科技感和神秘感。
体验地址>>
const rgba = imageData.data
for (let i = 0; i < rgba.length; i += 4) {
rgba[i] = 0 // red
rgba[i + 2] = 0 // blue
}
ctx.putImageData(imageData, 0, 0)
将 RGBA 中的 R 和 B 置为 0
跟踪“移动物体”
有了明亮的像素后,我们就要找出其 x 坐标的最小值与 y 坐标的最小值,以表示跟踪矩形的左上角。同理,x 坐标的最大值与 y 坐标的最大值则表示跟踪矩形的右下角。至此,我们就能绘制出一个能包围所有明亮像素的矩形,从而实现跟踪移动物体的效果。
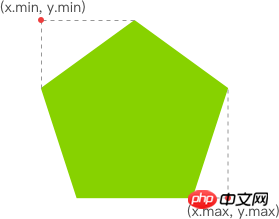
Wie Web-Technologie mobile Überwachung realisiert
体验链接>>
示例代码:
function processDiff (imageData) {
const rgba = imageData.data
let score = 0
let pixelScore = 0
let motionBox = 0
// 遍历整个 canvas 的像素,以找出明亮的点
for (let i = 0; i < rgba.length; i += 4) {
pixelScore = (rgba[i] + rgba[i+1] + rgba[i+2]) / 3
// 若该像素足够明亮
if (pixelScore >= 80) {
score++
coord = calcCoord(i)
motionBox = calcMotionBox(montionBox, coord.x, coord.y)
}
}
return {
score,
motionBox
}
}
// 得到左上角和右下角两个坐标值
function calcMotionBox (curMotionBox, x, y) {
const motionBox = curMotionBox || {
x: { min: coord.x, max: x },
y: { min: coord.y, max: y }
}
motionBox.x.min = Math.min(motionBox.x.min, x)
motionBox.x.max = Math.max(motionBox.x.max, x)
motionBox.y.min = Math.min(motionBox.y.min, y)
motionBox.y.max = Math.max(motionBox.y.max, y)
return motionBox
}
// imageData.data 是一个含有每个像素点 rgba 信息的一维数组。
// 该函数是将上述一维数组的任意下标转为 (x,y) 二维坐标。
function calcCoord(i) {
return {
x: (i / 4) % diffWidth,
y: Math.floor((i / 4) / diffWidth)
}
}在得到跟踪矩形的左上角和右下角的坐标值后,通过 ctx.strokeRect(x, y, width, height) API 绘制出矩形即可。
ctx.lineWidth = 6 ctx.strokeRect( diff.motionBox.x.min + 0.5, diff.motionBox.y.min + 0.5, diff.motionBox.x.max - diff.motionBox.x.min, diff.motionBox.y.max - diff.motionBox.y.min )

这是理想效果,实际效果请打开 体验链接
扩展:为什么上述绘制矩形的代码中的
x、y要加0.5呢?一图胜千言:
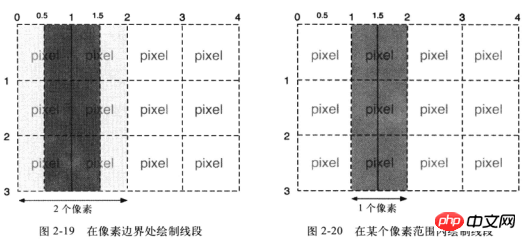
性能缩小尺寸
在上一个章节提到,我们需要通过对 Canvas 每个像素进行处理,假设 Canvas 的宽为 640,高为 480,那么就需要遍历 640 * 480 = 307200 个像素。而在监测效果可接受的前提下,我们可以将需要进行像素处理的 Canvas 缩小尺寸,如缩小 10 倍。这样需要遍历的像素数量就降低 100 倍,从而提升性能。
体验地址>>
示例代码:
const motionCanvas // 展示给用户看 const backgroundCanvas // offscreen canvas 背后处理数据 motionCanvas.width = 640 motionCanvas.height = 480 backgroundCanvas.width = 64 backgroundCanvas.height = 48

尺寸缩小 10 倍
定时器
我们都知道,当游戏以『每秒60帧』运行时才能保证一定的体验。但对于我们目前的案例来说,帧率并不是我们追求的第一位。因此,每 100 毫秒(具体数值取决于实际情况)取当前帧与前一帧进行比较即可。
另外,因为我们的动作一般具有连贯性,所以可取该连贯动作中幅度最大的(即“分数”最高)或最后一帧动作进行处理即可(如存储到本地或分享到朋友圈)。
延伸
至此,用 Web 技术实现简易的“移动监测”效果已基本讲述完毕。由于算法、设备等因素的限制,该效果只能以 2D 画面为基础来判断物体是否发生“移动”。而微软的 Xbox、索尼的 PS、任天堂的 Wii 等游戏设备上的体感游戏则依赖于硬件。以微软的 Kinect 为例,它为开发者提供了可跟踪最多六个完整骨骼和每人 25 个关节等强大功能。利用这些详细的人体参数,我们就能实现各种隔空的『手势操作』,如画圈圈诅咒某人。
下面几个是通过 Web 使用 Kinect 的库:
DepthJS:以浏览器插件形式提供数据访问。
Node-Kinect2: 以 Nodejs 搭建服务器端,提供数据比较完整,实例较多。
ZigFu: Unterstützt H5, U3D, Flash und verfügt über eine relativ vollständige API.
Kinect-HTML5: Kinect-HTML5 verwendet C#, um einen Server aufzubauen und Farbdaten, Tiefendaten und Knochendaten bereitzustellen.
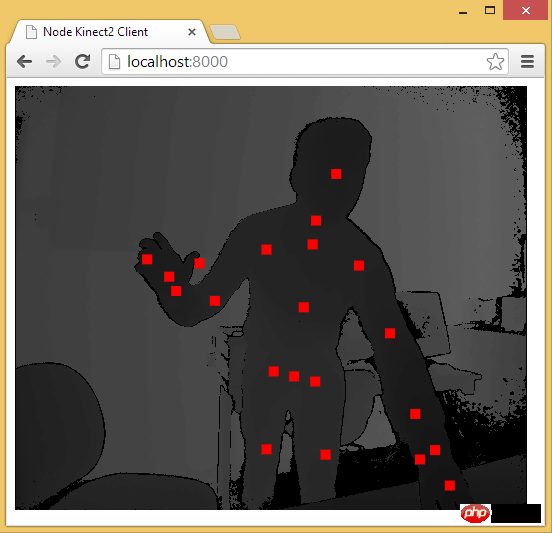
Erhalten Sie Skelettdaten über Node-Kinect2
Verwandte Empfehlungen:
Globale Überwachung des Ajax-Betriebs , Lösungen für Benutzersitzungsfehler
10 empfohlene Inhalte in der Kategorie Zeitüberwachung
PHP-Timer-Seiten-Laufzeitüberwachungskategorie
Das obige ist der detaillierte Inhalt vonWie Web-Technologie mobile Überwachung realisiert. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Eine eingehende Analyse der Bootstrap-Listengruppenkomponente
- Detaillierte Erläuterung des JavaScript-Funktions-Curryings
- Vollständiges Beispiel für die Generierung von JS-Passwörtern und die Erkennung der Stärke (mit Download des Demo-Quellcodes)
- Angularjs integriert WeChat UI (weui)
- Wie man mit JavaScript schnell zwischen traditionellem Chinesisch und vereinfachtem Chinesisch wechselt und wie Websites den Wechsel zwischen vereinfachtem und traditionellem Chinesisch unterstützen – Javascript-Kenntnisse