
Heim >Web-Frontend >CSS-Tutorial >So implementieren Sie das Parsen von CSS-Auswahlfeldern
So implementieren Sie das Parsen von CSS-Auswahlfeldern

- 小云云Original
- 2018-02-02 10:30:161958Durchsuche
Basierend auf den oben erlernten Grundkenntnissen der CSS-Syntax implementieren wir nun die Feldanalyse. Analysieren Sie zunächst den Titel. Öffnen Sie die Webentwicklertools und suchen Sie den Quellcode, der dem Titel entspricht. In diesem Artikel werden hauptsächlich relevante Informationen zur CSS-Selektor-Implementierung der Feldanalyse vorgestellt. Ich hoffe, dass er allen helfen kann der Knoten h1 unten, also habe ich die Scrapy-Shell zum Debuggen geöffnet
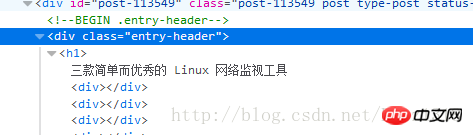
Aber was soll ich tun, wenn ich zu diesem Zeitpunkt kein Tag wie 4a249f0d628e2318394fd9b75b4636b1 möchte? Ich muss den Pseudocode in der CSS-Selektorklassenmethode verwenden. Wie unten gezeigt. p class="entry-header"


Verwandte Empfehlungen:
# -*- coding: utf-8 -*-
import scrapy
import re
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/113549/']
def parse(self, response):
# title = response.xpath('//p[@class = "entry-header"]/h1/text()').extract()[0]
# create_date = response.xpath("//p[@class = 'entry-meta-hide-on-mobile']/text()").extract()[0].strip().replace("·","").strip()
# praise_numbers = response.xpath("//span[contains(@class,'vote-post-up')]/h10/text()").extract()[0]
# fav_nums = response.xpath("//span[contains(@class,'bookmark-btn')]/text()").extract()[0]
# match_re = re.match(".*?(\d+).*",fav_nums)
# if match_re:
# fav_nums = match_re.group(1)
# comment_nums = response.xpath("//a[@href='#article-comment']/span").extract()[0]
# match_re = re.match(".*?(\d+).*", comment_nums)
# if match_re:
# comment_nums = match_re.group(1)
# content = response.xpath("//p[@class='entry']").extract()[0]
#通过CSS选择器提取字段
title = response.css(".entry-header h1::text").extract()[0]
create_date = response.css(".entry-meta-hide-on-mobile::text").extract()[0].strip().replace("·","").strip()
praise_numbers = response.css(".vote-post-up h10::text").extract()[0]
fav_nums = response.css("span.bookmark-btn::text").extract()[0]
match_re = re.match(".*?(\d+).*", fav_nums)
if match_re:
fav_nums = match_re.group(1)
comment_nums = response.css("a[href='#article-comment'] span::text").extract()[0]
match_re = re.match(".*?(\d+).*", comment_nums)
if match_re:
comment_nums = match_re.group(1)
content = response.css("p.entry").extract()[0]
tags = response.css("p.entry-meta-hide-on-mobile a::text").extract()[0]
pass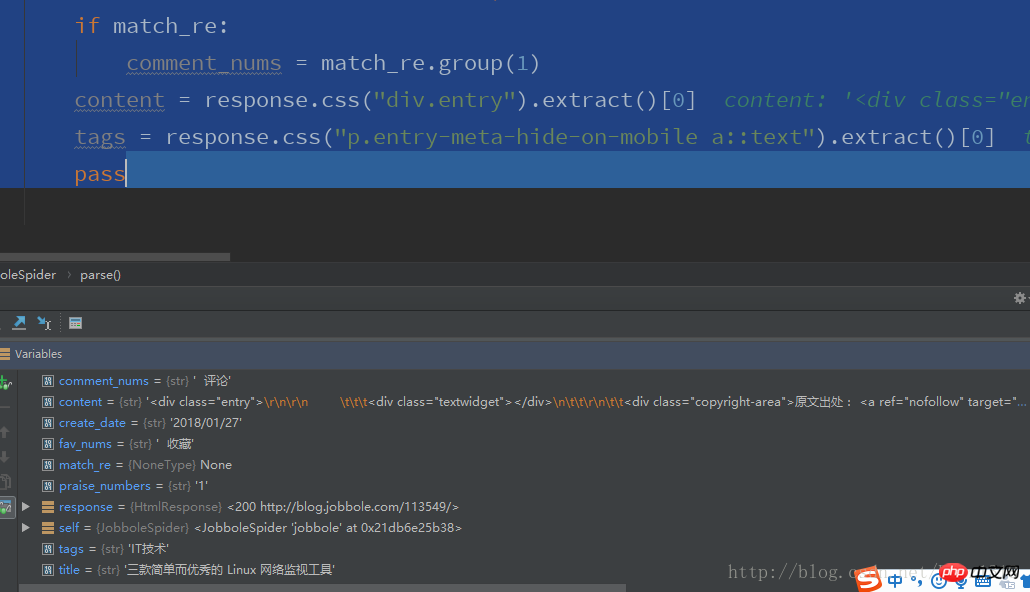 OpenERP-Mitarbeiter ( (Mitarbeiter)-Tabelle Parsen von Feldern, die mit Benutzertabellen verknüpft sind
OpenERP-Mitarbeiter ( (Mitarbeiter)-Tabelle Parsen von Feldern, die mit Benutzertabellen verknüpft sind
Das obige ist der detaillierte Inhalt vonSo implementieren Sie das Parsen von CSS-Auswahlfeldern. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!