
Heim >Backend-Entwicklung >Python-Tutorial >Detaillierte Erläuterung der Lernbeispiele für Python-Textmerkmalsextraktion und Vektorisierungsalgorithmus
Detaillierte Erläuterung der Lernbeispiele für Python-Textmerkmalsextraktion und Vektorisierungsalgorithmus

- 小云云Original
- 2017-12-23 17:05:575265Durchsuche
Angenommen, wir haben gerade Nolans Blockbuster „Interstellar“ gesehen. Wie können wir eine Maschine automatisch analysieren lassen, ob die Bewertung des Films durch das Publikum „positiv“ oder „negativ“ ist? Diese Art von Problem ist ein Problem der Stimmungsanalyse. Der erste Schritt zur Lösung dieser Art von Problem besteht darin, Text in Features umzuwandeln. In diesem Artikel wird hauptsächlich der Python-Textmerkmalsextraktions- und Vektorisierungsalgorithmus vorgestellt. Ich hoffe, er kann jedem helfen.
Daher lernen wir in diesem Kapitel nur den ersten Schritt, wie man Features aus Text extrahiert und sie vektorisiert.
Da die Verarbeitung von Chinesisch eine Wortsegmentierung umfasst, veranschaulicht dieser Artikel anhand eines einfachen Beispiels, wie die maschinelle Lernbibliothek von Python zum Extrahieren von Funktionen aus dem Englischen verwendet wird.
1. Datenvorbereitung
Pythons sklearn.datasets unterstützt das Lesen aller klassifizierten Texte aus dem Verzeichnis. Allerdings müssen die Verzeichnisse nach den Regeln eines Ordners und eines Labelnamens platziert werden. Der in diesem Artikel verwendete Datensatz hat beispielsweise insgesamt zwei Bezeichnungen, eine ist „net“ und die andere ist „pos“, und in jedem Verzeichnis befinden sich 6 Textdateien. Das Verzeichnis ist wie folgt:
neg
1.txt
2.txt
......
pos
1.txt
2 .txt
....
Der Inhalt der 12 Dateien ist wie folgt zusammengefasst:
neg: shit. waste my money. waste of money. sb movie. waste of time. a shit movie. pos: nb! nb movie! nb! worth my money. I love this movie! a nb movie. worth it!
2. Textmerkmale
Wie kann man aus diesen englischen Wörtern emotionale Einstellungen extrahieren und sie klassifizieren?
Der intuitivste Weg ist das Extrahieren von Wörtern. Es wird allgemein angenommen, dass viele Schlüsselwörter die Einstellung des Sprechers widerspiegeln können. Im obigen einfachen Datensatz lässt sich beispielsweise leicht feststellen, dass alles, was „Scheiße“ sagt, zur Kategorie „Negativ“ gehören muss.
Natürlich ist der obige Datensatz lediglich zur Vereinfachung der Beschreibung konzipiert. In der Realität hat ein Wort oft zweideutige Einstellungen. Dennoch gibt es Grund zu der Annahme, dass die Wahrscheinlichkeit, dass ein Wort die negative Einstellung ausdrückt, umso größer ist, je häufiger es in der negativen Kategorie vorkommt.
Außerdem stellen wir fest, dass einige Wörter für die Stimmungsklassifizierung bedeutungslos sind. Zum Beispiel Wörter wie „von“ und „I“ in den obigen Daten. Diese Art von Wort hat einen Namen, der „Stop_Word“ (Stoppwort) heißt. Solche Wörter können völlig ignoriert und nicht gezählt werden. Offensichtlich kann durch Ignorieren dieser Wörter der Speicherplatz der Worthäufigkeitsdatensätze optimiert werden und die Konstruktionsgeschwindigkeit ist schneller.
Es besteht auch ein Problem darin, die Worthäufigkeit jedes Wortes als wichtiges Merkmal zu betrachten. Beispielsweise kommt „Film“ in den obigen Daten fünfmal in 12 Stichproben vor, aber die Anzahl der positiven und negativen Vorkommen ist nahezu gleich und es gibt keinen Unterschied. Und „Wert“ erscheint zweimal, aber nur in der Kategorie „Pos“. Es hat offensichtlich eine starke, kräftige Farbe, das heißt, die Unterscheidung ist sehr hoch.
Daher müssen wir TF-IDF (Term Frequency-Inverse Document Frequency, Term Frequency und Inverse Document Frequency ) einführen, um jedes Wort weiter zu berücksichtigen .
TF (Begriffshäufigkeit) Die Berechnung von ist sehr einfach, dh für ein Dokument t die Häufigkeit, mit der ein bestimmtes Wort Nt im Dokument vorkommt. Im Dokument „Ich liebe diesen Film“ beträgt beispielsweise die TF des Wortes „Liebe“ 1/4. Wenn Sie die Stoppwörter „I“ und „it“ entfernen, ist es 1/2.
IDF (Inverse File Frequency) bedeutet, dass für ein bestimmtes Wort t die Anzahl der Dokumente Dt, in denen das Wort vorkommt, den Anteil aller Testdokumente D ausmacht. Dann Finden Sie den natürlichen Logarithmus.
Zum Beispiel kommt das Wort „Film“ insgesamt fünfmal vor und die Gesamtzahl der Dokumente beträgt 12, sodass die IDF ln(5/12) ist.
IDF zielt offensichtlich darauf ab, die Wörter hervorzuheben, die selten vorkommen, aber eine starke emotionale Farbe haben. Beispielsweise beträgt die IDF eines Wortes wie „Film“ ln(12/5)=0,88, was viel kleiner ist als die IDF von „Liebe“=ln(12/1)=2,48.
TF-IDF multipliziert einfach die beiden. Auf diese Weise ist das Finden der TF-IDF jedes Wortes in jedem Dokument der Textmerkmalswert, den wir extrahiert haben.
3. Vektorisierung
Mit der oben genannten Grundlage kann das Dokument vektorisiert werden. Schauen wir uns zuerst den Code an und analysieren dann die Bedeutung der Vektorisierung:
# -*- coding: utf-8 -*-
import scipy as sp
import numpy as np
from sklearn.datasets import load_files
from sklearn.cross_validation import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
'''''加载数据集,切分数据集80%训练,20%测试'''
movie_reviews = load_files('endata')
doc_terms_train, doc_terms_test, y_train, y_test\
= train_test_split(movie_reviews.data, movie_reviews.target, test_size = 0.3)
'''''BOOL型特征下的向量空间模型,注意,测试样本调用的是transform接口'''
count_vec = TfidfVectorizer(binary = False, decode_error = 'ignore',\
stop_words = 'english')
x_train = count_vec.fit_transform(doc_terms_train)
x_test = count_vec.transform(doc_terms_test)
x = count_vec.transform(movie_reviews.data)
y = movie_reviews.target
print(doc_terms_train)
print(count_vec.get_feature_names())
print(x_train.toarray())
print(movie_reviews.target)运行结果如下:
[b'waste of time.', b'a shit movie.', b'a nb movie.', b'I love this movie!', b'shit.', b'worth my money.', b'sb movie.', b'worth it!']
['love', 'money', 'movie', 'nb', 'sb', 'shit', 'time', 'waste', 'worth']
[[ 0. 0. 0. 0. 0. 0. 0.70710678 0.70710678 0. ]
[ 0. 0. 0.60335753 0. 0. 0.79747081 0. 0. 0. ]
[ 0. 0. 0.53550237 0.84453372 0. 0. 0. 0. 0. ]
[ 0.84453372 0. 0.53550237 0. 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 1. 0. 0. 0. ]
[ 0. 0.76642984 0. 0. 0. 0. 0. 0. 0.64232803]
[ 0. 0. 0.53550237 0. 0.84453372 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 0. 0. 0. 1. ]]
[1 1 0 1 0 1 0 1 1 0 0 0]
python输出的比较混乱。我这里做了一个表格如下:
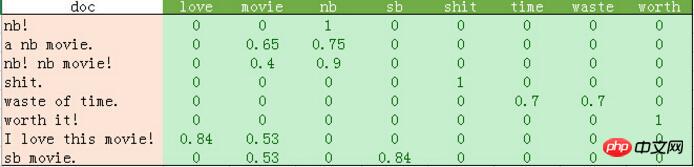
从上表可以发现如下几点:
1、停用词的过滤。
初始化count_vec的时候,我们在count_vec构造时传递了stop_words = 'english',表示使用默认的英文停用词。可以使用count_vec.get_stop_words()查看TfidfVectorizer内置的所有停用词。当然,在这里可以传递你自己的停用词list(比如这里的“movie”)
2、TF-IDF的计算。
这里词频的计算使用的是sklearn的TfidfVectorizer。这个类继承于CountVectorizer,在后者基本的词频统计基础上增加了如TF-IDF之类的功能。
我们会发现这里计算的结果跟我们之前计算不太一样。因为这里count_vec构造时默认传递了max_df=1,因此TF-IDF都做了规格化处理,以便将所有值约束在[0,1]之间。
3. Das Ergebnis von count_vec.fit_transform ist eine riesige Matrix. Wir können sehen, dass es in der obigen Tabelle viele Nullen gibt, daher verwendet sklearn für seine interne Implementierung eine dünn besetzte Matrix. Die Daten in diesem Beispiel sind klein. Wenn Leser interessiert sind, können Sie echte Daten ausprobieren, die von Forschern des maschinellen Lernens der Cornell University verwendet werden: http://www.cs.cornell.edu/people/pabo/movie-review-data/. Diese Website bietet viele Datensätze, darunter mehrere Datenbanken von etwa 2 Millionen, mit etwa 700 positiven und negativen Beispielen. Der Umfang dieser Art von Daten ist nicht groß und kann dennoch innerhalb einer Minute abgeschlossen werden. Ich empfehle Ihnen, es auszuprobieren. Beachten Sie jedoch, dass diese Datensätze möglicherweise Probleme mit illegalen Zeichen aufweisen. Beim Erstellen von count_vec wird daher decode_error = 'ignore' übergeben, um diese unzulässigen Zeichen zu ignorieren.
Die Ergebnisse in der obigen Tabelle sind die Ergebnisse des Trainings von 8 Funktionen an 8 Proben. Dieses Ergebnis kann mithilfe verschiedener Klassifizierungsalgorithmen klassifiziert werden.
Verwandte Empfehlungen:
Teilen Sie ein Beispiel für einen QR-Code zur Python-Textgenerierung
Detaillierte Erläuterung des Bearbeitungsabstands für die Berechnung der Python-Textähnlichkeit
Detailliertes Beispiel für die Erfassung einfacher Webseitenbilder in Python
Das obige ist der detaillierte Inhalt vonDetaillierte Erläuterung der Lernbeispiele für Python-Textmerkmalsextraktion und Vektorisierungsalgorithmus. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!