
Heim >Datenbank >MySQL-Tutorial >Vergleichende Analyse von Hochverfügbarkeitslösungen für Oracle und MySQL
Vergleichende Analyse von Hochverfügbarkeitslösungen für Oracle und MySQL

- 小云云Original
- 2017-12-08 11:58:031546Durchsuche
Was die Hochverfügbarkeitslösungen von Oracle und MySQL betrifft, wollte ich sie schon immer zusammenfassen, deshalb werde ich in mehreren Serien kurz darauf eingehen. Durch diesen Vergleich erhalten Sie ein grundlegendes Verständnis für die detaillierten Unterschiede im Design der beiden Datenbankarchitekturen. Oracle verfügt über eine sehr ausgereifte Lösung. Meinem Ppt zum Thema OOW nach zu urteilen, handelt es sich um den Plan von MAA. Dieses Jahr jährt sich dieser Plan zum 16. Mal. In diesem Artikel wird hauptsächlich die vergleichende Analyse der Hochverfügbarkeitslösungen von Oracle und MySQL vorgestellt. Sie ist sehr gut und hat Referenzwert.

Aufgrund des Open-Source-Charakters von MySQL hat die Community mehr Lösungen auf den Markt gebracht. Meiner persönlichen Meinung nach wird InnoDB Cluster die Standard-Hochverfügbarkeitslösung für MySQL sein Zukunft.
Derzeit ist MGR gut, und es gibt auch MySQL-Cluster-Lösungen, PXC, Galera und andere Lösungen. Ich persönlich bevorzuge immer noch MHA.
Daher wird dieser Artikel in mehrere Teile unterteilt Um es zu erklären, machen wir zunächst einen grundlegenden Vergleich zwischen RAC und MHA.
Die Lösungen von Oracle unterstützten Alibabas Kerngeschäftsanforderungen während seiner schnellen Entwicklungsphase. Es handelt sich wahrscheinlich um ein solches Architektursystem, das sehr riesig aussieht. Der RAC im Inneren gilt als Aristokrat, der teuren kommerziellen Speicher, extrem hohe Anforderungen an die Netzwerkbandbreite sowie eine große Anzahl kleiner Front-End-Computerdienste und teure Lizenzgebühren nutzt. Eine sehr typische klassische IOE-Architektur.

Wenn Sie eine externe Notfallwiederherstellung in Betracht ziehen möchten, müssen die Ressourcenzuweisung verdoppelt und das Budget verdoppelt werden.
Die Architekturlösung von MySQL ist relativ zivilisiert, aber die Größenordnung ist höher. Bei der Geschäftsaufteilung kann die horizontale Aufteilung viele Knoten vergrößern Es gibt Hunderte oder Hunderte von MySQL-Clustern, und Tausende sind keine Seltenheit. Bei so vielen Serviceressourcen besteht immer noch die Wahrscheinlichkeit eines Scheiterns. Die Gewährleistung eines nachhaltigen Zugangs zu Unternehmensdiensten ist der Schlüssel zu technischen Lösungen. Wenn Sie der MHA-Architektur folgen, ist der MHA-Manager-Knoten im Wesentlichen für den Status des gesamten Clusters verantwortlich. Er ist wie eine Tante des Nachbarschaftskomitees, die alle großen und kleinen Dinge über die Bewohner weiß.

Natürlich ist die obige Aussage zu allgemein, beginnen wir mit einigen Details. Lassen Sie uns zum Beispiel zunächst über das Internet sprechen.
Oracle stellt sehr strenge Anforderungen an das Netzwerk. Jeder Server benötigt zusätzlich zum gemeinsamen Speicher mindestens 2 erforderlich.
Private IP dient der gegenseitigen Vertrauensstellung zwischen Knoten, die sich im selben Netzwerksegment befinden, und ist die Drift-IP des Netzwerks, in dem sich die öffentliche IP befindet. Dies geschieht alles über VIP. Für den Lastausgleich wurde seit 11g Scan-IP eingeführt, und das ursprüngliche VIP wird weiterhin beibehalten, sodass die Anforderungen an die Netzwerkkonfiguration in Oracle immer noch sehr hoch sind. Unabhängig vom gemeinsam genutzten Speicher ist der Kern der Konstruktion die Netzwerkkonfiguration, und das Netzwerk ist allgemein.
Scan-IP kann weiterhin erweitert werden und unterstützt bis zu 3 Scan-IPs, wie in der Abbildung unten gezeigt

Natürlich auf Netzwerkebene ist nicht auf diese beschränkt. Das Highlight von Oracle ist, dass es sehr professionell ist. Wir müssen TAF verstehen. In meinem Buch „Oracle DBA Work Notes“ habe ich Folgendes geschrieben:
TAF (Transparent Application Failover) ist ein anwendungstransparentes Failover in einer RAC-Umgebung, das besonders häufig verwendet wird. Der Lastausgleich in RAC wurde in der Tat erheblich verbessert, vom Lastausgleich mehrerer VIP-Adressen ab der 10g-Version bis hin zum SCAN in der 11g-Version.
Bei der Implementierung von Failover gibt es immer noch bestimmte Nutzungsbeschränkungen. Beispielsweise verfügt die Standardimplementierung von SCAN-IP in 11g tatsächlich nicht standardmäßig über eine Failover-Option. Wenn Sie dann die Abfrage in der ursprünglichen Verbindung fortsetzen, werden Sie gefragt, dass die Sitzung getrennt wurde und erneut verbunden werden muss. Client TAF wird hauptsächlich einige einfache Inhalte der Failover-Methode und des Failover-Typs besprechen.
(1)Failover-Methode
Die Hauptidee der Failover-Methode besteht darin, Failover-Zeit oder Ressourcen für die Implementierung auszutauschen.
Angenommen, wir haben zwei Knoten. Wenn eine Sitzung mit Knoten 2 verbunden ist, aber Knoten 2 plötzlich auflegt, gibt es zwei Arten der Failover-Methode : Preconnect und Basic.
– Preconnect wird immer noch viele Ressourcen beanspruchen. Es werden einige zusätzliche Ressourcen auf jedem Knoten beansprucht. Der Wechsel wird relativ reibungsloser und schneller sein.
– Basic Bei dieser Methode werden bei einem Failover die entsprechenden Ressourcen umgeschaltet. Es kommt zu einer gewissen Verzögerung im Prozess, aber der Ressourcenverbrauch ist relativ viel geringer.
Um es einfach auszudrücken: Die Basismethode beurteilt nur, wenn ein Fehler auftritt, während die Vorverbindung aus einer praktischen Anwendung heraus für die Vorbereitung auf einen schlechten Tag gedacht ist. Die Basismethode ist vielseitiger und auch die Standard-Failover-Methode .
(2)Failover-Typ
Die Implementierung des Failover-Typs ist umfangreicher, flexibler und sehr leistungsstark. Zu diesem Zeitpunkt kann die Steuerungsgranularität basierend auf der Ausführung von Benutzer-SQL gesteuert werden. Es gibt zwei Typen: Auswählen und Sitzung.
Zum Beispiel haben wir eine große Abfrage auf Knoten 2 und Knoten 2 hängt plötzlich. Für die ausgeführte Abfrage gibt es beispielsweise 10.000 Daten, und das Ergebnis wird genau dann erkannt, wenn der Fehler auftritt Wenn Sie 8.000 Artikel haben, was sollten Sie mit den restlichen 2.000 machen?
Die erste Möglichkeit besteht darin, select zu verwenden. Das heißt, der Failover wird abgeschlossen und die verbleibenden 2.000 Datensätze werden weiterhin zurückgegeben. Natürlich wird es in der Mitte einen transparenten Kontextwechsel geben der Benutzer.
Die zweite Methode ist die Sitzung; das heißt, Sie trennen die Verbindung direkt und bitten erneut um eine Abfrage.
In der 10g-Version lautet die Konfiguration zum Erreichen von Load Balance+Failover mithilfe der VIP-Konfiguration wie folgt:
racdb= (DESCRIPTION = (ADDRESS= (PROTOCOL= TCP)(HOST=192.168.3.101)(PORT= 1521)) (ADDRESS= (PROTOCOL= TCP)(HOST=192.168.3.201)(PORT= 1521)) (LOAD_BALANCE = yes) (FAILOVER = ON) (CONNECT_DATA = (SERVER= DEDICATED) (SERVICE_NAME = racdb) (FAILOVER_MODE = (TYPE= SELECT) (METHOD= BASIC) (RETRIES = 30) (DELAY = 5)))) 如果11g的SCAN-IP也想进一步扩展Failover,同样也需要设置failover_mode和对应的类型。 RACDB = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = rac-scan)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = RACDB) ) )
Aus dieser Perspektive ist die Lösung von Oracle wirklich ausgefeilt. Werfen wir einen Blick auf die Lösung von MySQL.
Die verteilte Lösung lässt MySQL wie ein Schweizer Messer aussehen. Man kann sagen, dass MySQL keine Anforderungen hat. Wenn Sie einen Master und einen Slave beantragen, benötigen Sie nur 4 IPs , Slave, VIP, MHA_Manager (betrachten Sie einen Managerknoten)), ein Master und zwei Slaves sind 5.

MySQL unterstützt den sogenannten Lastausgleich nicht nativ. Er kann durch Front-End-Geschäfte wie die Verwendung von Middleware-Proxys oder kontinuierlicher Aufteilung umgeleitet werden, um eine bestimmte zu erreichen Nach der Granularität werden die Anforderungen durch architektonisches Design erfüllt. Da die logikbasierte Replikation leicht zu erweitern ist, sind ein Master und mehrere Slaves weit verbreitet und die Kosten sind nicht hoch. Man kann nicht sagen, dass die Verzögerung Null ist, sondern nur sehr gering, und sie kann an die meisten Internet-Geschäftsanforderungen angepasst werden.
Wenn es um die Bedingungen geht, die einen MHA-Wechsel auslösen, stellen die folgenden roten Punkte potenzielle Gefahren dar. Bei einigen handelt es sich um Netzwerkunterbrechungen, bei anderen um Netzwerkverzögerungen Daten schützen. Die Leistung ist stabil und kann an Ihre eigenen Bedürfnisse angepasst werden. Unter diesem Gesichtspunkt besteht die Wahrscheinlichkeit eines Datenverlusts. Es handelt sich definitiv nicht um eine verlustfreie Kopie mit starker Konsistenz.
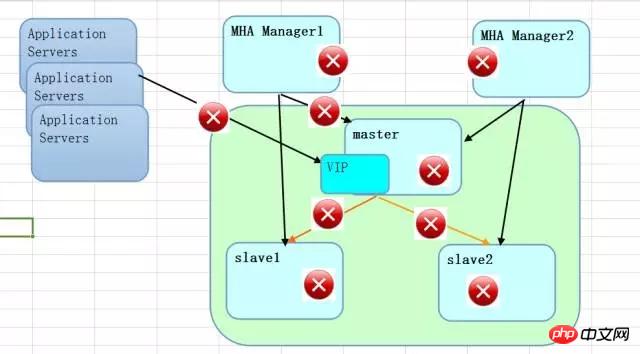
Wenn man die beiden Lösungen insgesamt betrachtet, ist RAC eine zentralisierte gemeinsame Nutzung. Zusätzlich zur gemeinsamen Nutzung auf Speicherebene erhöht Multicast auf Netzwerkebene tatsächlich die Kosten für die Kommunikation zwischen Knoten Daher stellt RAC hohe Anforderungen an das Netzwerk. Wenn es zu einer Spaltung des Gehirns kommt, ist dies sehr peinlich. Die Lösung von MySQL MHA wird verteilt. Durch die Unterstützung hochvolumiger Umgebungen sind die Kommunikationskosten zwischen Knoten relativ gering. Da es sich jedoch aus Sicht der Datenarchitektur um eine replizierte Datenverteilungsmethode handelt, sind die Speicherkosten, obwohl es sich nicht um gemeinsam genutzten Speicher handelt, immer noch höher als bei RAC (dies bedeutet nicht den Speicherpreis, sondern die gespeicherte Datenmenge). ).
Verwandte Empfehlungen:
Oracle und MySQL generieren jeweils Sequenzsequenzen
Vergleich einiger einfacher Befehle zwischen Oracle und MySQL_MySQL
Einen Vergleich einiger einfacher Befehle zwischen Oracle und MySQL finden Sie unter [Foto]_MySQL
Das obige ist der detaillierte Inhalt vonVergleichende Analyse von Hochverfügbarkeitslösungen für Oracle und MySQL. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!