
Heim >Datenbank >MySQL-Tutorial >Ausführliche Erklärung zur Verwendung von „distinct' in SQL
Ausführliche Erklärung zur Verwendung von „distinct' in SQL

- 黄舟Original
- 2017-12-05 15:02:493433Durchsuche
Das Schlüsselwort „distinct“ wird verwendet, um redundante doppelte Datensätze herauszufiltern und nur einen zu behalten. Oft wird es jedoch nur verwendet, um die Anzahl eindeutiger Datensätze zurückzugeben, anstatt alle Werte eindeutiger Datensätze zurückzugeben. Der Grund dafür ist, dass „distinct“ nur sein Zielfeld, aber keine anderen -Felder zurückgeben kann. Als Nächstes werde ich Ihnen in diesem Artikel die Verwendung von „distinct“ mitteilen >Bei der
Verwendung von MySQList es manchmal erforderlich, Abfragen durchzuführen, um nicht doppelte Datensätze in einem bestimmten Feld zu finden, obwohl MySQL das eindeutige Schlüsselwort zum Herausfiltern redundanter doppelter Datensätze bereitstellt Behalten Sie nur einen, aber es wird oft nur verwendet, um die Anzahl eindeutiger Datensätze zurückzugeben, anstatt alle Werte nicht doppelter Datensätze zurückzugeben. Der Grund dafür ist, dass Unique nur sein Zielfeld, aber keine anderen Felder zurückgeben kann. Dieses Problem hat mich schon lange beschäftigt. Wenn es nicht mit Unique gelöst werden kann, kann ich es nur mit einer doppelten -Schleife Abfrage, und das ist Bei einer Website mit sehr großen Datenmengen wirkt sich dies zweifellos direkt auf die Effizienz aus, sodass ich viel Zeit verschwendet habe. Die Tabelle enthält möglicherweise doppelte Werte. Dies ist kein Problem, aber manchmal möchten Sie vielleicht nur unterschiedliche Werte auflisten. Das Schlüsselwort „distinct“ wird verwendet, um eindeutig unterschiedliche Werte zurückzugeben.
Tabelle A: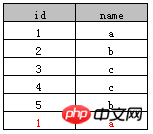 Beispiel 1
Beispiel 1
Der Code lautet wie folgt:
Das Ergebnis nach der Ausführung ist wie folgt:
select distinct name from A
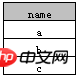 Beispiel 2
Beispiel 2
Der Code lautet wie folgt:
Ausführung Das Endergebnis ist wie folgt:
select distinct name, id from A
basiert tatsächlich auf 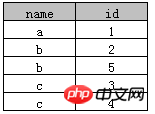 "name+id"
"name+id"
Name als auch für ID wird diese Methode sowohl von Access als auch von SQL Server unterstützt. Beispiel 3: Statistik
Der Code lautet wie folgt:Beispiel 4
select count(distinct name) from A; --表中name去重后的数目, SQL Server支持,而Access不支持 select count(distinct name, id) from A; --SQL Server和Access都不支持Der Code lautet wie folgt:
Sonstige
select id, distinct name from A; --会提示错误,因为distinct必须放在开头Die in der Select-Anweisung in der Distinct-Anweisung angezeigten Felder können nur die durch Distinct und angegebenen Felder sein andere Felder sind nicht möglich. Wenn Tabelle A beispielsweise eine Spalte „Bemerkungen“ enthält und Sie den eindeutigen Namen und das entsprechende Feld „Bemerkungen“ abrufen möchten, ist es nicht möglich, dies direkt über „bemerkungen“ zu tun.
Zusammenfassung:
Dieser Artikel verwendet Beispiele, um die Verwendung von „distinct“ in SQL im Detail vorzustellen Einer davon ist, dass jeder die Verwendung von „distinct“ demonstriert. Ich glaube, jeder hat sein eigenes Verständnis und Verständnis. Ich hoffe, dass es für Ihre Arbeit hilfreich sein wird.
MySQL zählt eindeutige statistische Ergebnisse, um Duplikate zu entfernen
Gedanken, die durch ein bestimmtes Problem verursacht werden
Oracle – Verwendung von eindeutig
Verwendung von „distinct“ in SQL (Analyse von vier Beispielen)
Das obige ist der detaillierte Inhalt vonAusführliche Erklärung zur Verwendung von „distinct' in SQL. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!