
Heim >Java >javaLernprogramm >Beispielanalyse eines Java-Parsing-DICOM-Diagramms zum Erhalten hexadezimaler Daten
Beispielanalyse eines Java-Parsing-DICOM-Diagramms zum Erhalten hexadezimaler Daten

- 黄舟Original
- 2017-10-18 09:51:161908Durchsuche
DICOM steht für Medical Digital Imaging and Communication. Es handelt sich um einen internationalen Standard für medizinische Bilder und zugehörige Informationen (ISO 12052). Der folgende Artikel führt Sie hauptsächlich in die relevanten Informationen zum Erhalten hexadezimaler Daten mithilfe von Java zum Parsen von DICOM ein Diagramme. Der Artikel stellt es ausführlich anhand von Beispielcode vor.
Vorwort
In einem aktuellen Projekt wurde JAVA benötigt, um DICOM-Bilder zu analysieren. DICOM wird häufig in der Radiologie, Medizin, kardiovaskulären Bildgebung und Strahlentherapie verwendet Diagnose- und Behandlungsgeräte (Röntgen, CT, MRT, Ultraschall usw.) und werden zunehmend auch in anderen medizinischen Bereichen wie der Augenheilkunde und der Zahnmedizin eingesetzt. Nachfolgend werden einige bei der Umsetzung aufgetretene Probleme aufgeführt.
Suchen Sie zunächst eine *.dcm-Datei. Öffnen Sie es mit dem Editor und Sie sehen die folgende Oberfläche. Der von mir verwendete Editor ist UltraEdit
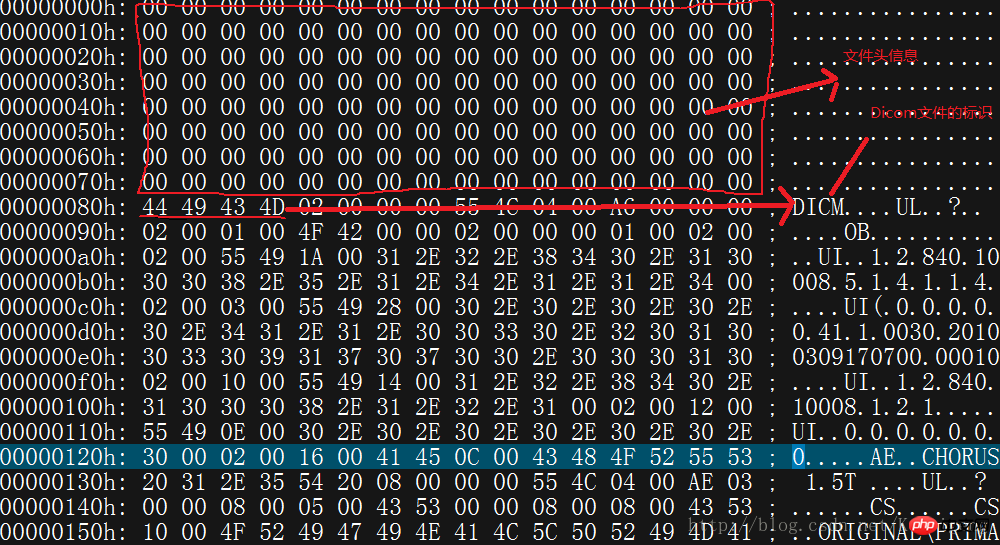
Der rot markierte Text ist die Bytecode-Anmerkung. Die ersten 8 Codezeilen sind die Header-Informationen der Datei und im Allgemeinen nutzlos . Wichtig sind die vier Hexadezimalzahlen „44,49,43,4D“ ab der neunten Zeile. Die ASCll-Code-Erklärung ist DICM. Zeigt an, dass es sich um eine DICOM-Datei handelt. Wenn diese vier Hexadezimalzahlen verloren gehen oder beschädigt sind, kann das DICOM-Bild nicht geöffnet werden.
Im Folgenden wird Java verwendet, um diese Hexadezimalzahlen zu lesen
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
public class My_DICOM {
static FileInputStream input;
static byte[] b;
public static void main(String[] args) {
try {
File file = new File("G:/zzz.dcm");
input = new FileInputStream(file);
b = new byte[(int) file.length()];
input.read(b);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
init();
}
public static void init(){
System.out.println("b.length="+b.length);
for (int i =0;i<10000;i++) {
System.out.print(Integer.toHexString(b[i]));
if (i%16==15) {
System.out.println();
}else{
System.out.print(", ");
}
}
}
} (weil Die Datei ist zu groß und hat 130.000 Bytes, daher wird zur Demonstration nur eine Schleife von 10.000 Malen durchgeführt.)
Der obige Code ist sehr verbreitet und dient dazu, den Dateistream in ein Byte-Array einzulesen . Verwenden Sie Integer.toHexString(b[i]), um es in Hexadezimal umzuwandeln.
Es tritt ein Problem auf.
Nach dem Ausführen:
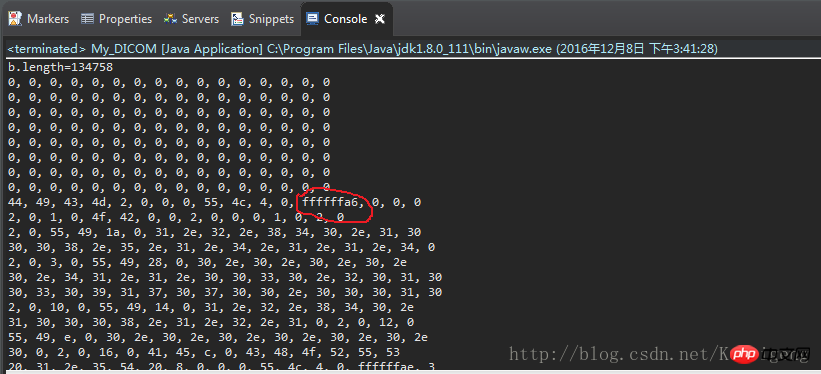
Verglichen mit der vom obigen Editor geöffneten Hexadezimalliste sollte der rote Text a6 sein, aber es ist ist nicht ffffffa6 wird gedruckt.
Finden Sie das Problem
Die Position des falschen Bytes ist 140. Das Drucken von system.out.pritln(b[140]); ergibt -90. Warum -90?
Das Zurückschieben auf a6 und die Konvertierung in eine Dezimalzahl sollte 166 ergeben.
Okay, ich habe das Problem gefunden. 166+90=256 Das ist kein Zufall. Ein übersehenes Problem besteht darin, dass der Maximalwert des Byte-Arrays nur 127 beträgt. Wenn das in der Datei gelesene Array größer als 127 ist, tritt daher beim Lesen des Byte-Arrays ein Fehler auf.
Lösung
public static void init(){
System.out.println("b.length="+b.length);
for (int i =0;i<10000;i++) {
if (b[i]<0) {
int temp=b[i]+256;
System.out.print(Integer.toHexString(temp));
}else{
System.out.print(Integer.toHexString(b[i]));
}
if (i%16==15) {
System.out.println();
}else{
System.out.print(", ");
}
}
}Zusammenfassung
Das obige ist der detaillierte Inhalt vonBeispielanalyse eines Java-Parsing-DICOM-Diagramms zum Erhalten hexadezimaler Daten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!