
Heim >Java >javaLernprogramm >Analyse von vier Möglichkeiten zur Optimierung interner Sperren in der Java Virtual Machine
Analyse von vier Möglichkeiten zur Optimierung interner Sperren in der Java Virtual Machine

- 黄舟Original
- 2017-10-13 10:18:431322Durchsuche
Dieser Artikel stellt hauptsächlich die vier Optimierungsmethoden der Java Virtual Machine für interne Sperren vor. Jetzt werde ich ihn mit Ihnen teilen und Ihnen eine Referenz geben. Folgen wir dem Editor, um einen Blick darauf zu werfen
Seit Java 6/Java 7 hat die Java Virtual Machine einige Optimierungen an der Implementierung interner Sperren vorgenommen. Zu diesen Optimierungen gehören hauptsächlich Lock Elision, Lock Coarsening, Biased Locking und Adaptive Locking. Diese Optimierungen funktionieren nur im Java Virtual Machine-Servermodus (d. h. wenn wir ein Java-Programm ausführen, müssen wir möglicherweise den Java Virtual Machine-Parameter „-server“ in der Befehlszeile angeben, um diese Optimierungen zu aktivieren).
1 Sperrenbeseitigung
Die Sperrenbeseitigung ist eine vom JIT-Compiler vorgenommene Optimierung für die spezifische Implementierung interner Sperren.
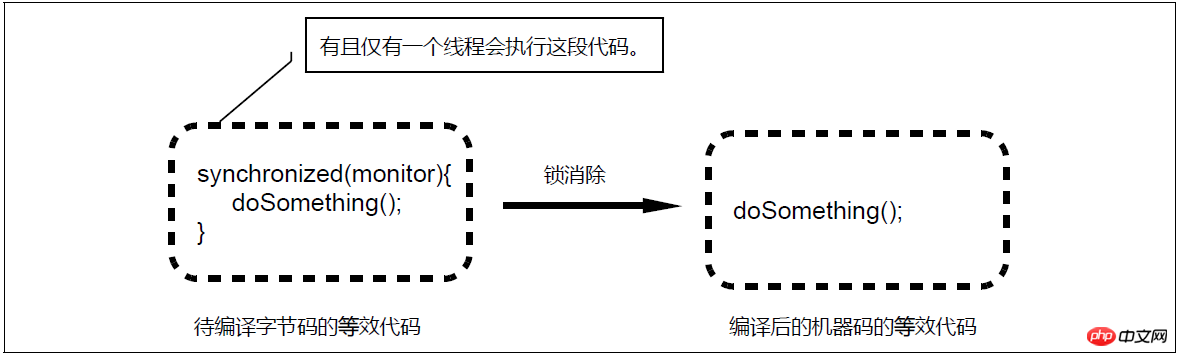
Lock-Elision-Diagramm
Beim dynamischen Kompilieren synchronisierter Blöcke kann der JIT-Compiler eine Methode namens Escape-Analyse (Escape Analysis)-Technologie verwenden, um zu bestimmen, ob die Sperre vorliegt Das vom synchronisierten Block verwendete Objekt kann nur von einem Thread aufgerufen werden und wurde nicht für andere Threads freigegeben. Wenn durch diese Analyse bestätigt wird, dass das vom synchronisierten Block verwendete Sperrobjekt nur für einen Thread zugänglich ist, generiert der JIT-Compiler beim Kompilieren des synchronisierten Blocks nicht den Maschinencode, der der Sperranwendung und -freigabe entspricht, die durch synchronisiert dargestellt wird, sondern nur Es wird der Maschinencode generiert, der dem ursprünglichen Code des kritischen Abschnitts entspricht, wodurch der dynamisch kompilierte Bytecode so aussieht, als ob er die beiden Bytecode-Anweisungen Monitorenter (Sperre beantragen) und Monitorexit (Sperre aufheben) nicht enthält, d. h. die Verwendung von Sperren eliminiert . Diese Compileroptimierung wird als Sperreneliminierung (Lock Elision) bezeichnet und ermöglicht es uns, den Overhead von Sperren unter bestimmten Umständen vollständig zu eliminieren.
Obwohl einige Klassen in der Java-Standardbibliothek (z. B. StringBuffer) threadsicher sind, teilen wir in der tatsächlichen Verwendung häufig keine Instanzen dieser Klassen zwischen mehreren Threads. Diese Klassen stützen sich bei der Implementierung der Thread-Sicherheit häufig auf interne Sperren. Daher sind diese Klassen häufige Ziele für Optimierungen zur Sperrenbeseitigung.
Listing 12-1 Beispielcode, der für die Sperrenbeseitigung optimiert werden kann
public class LockElisionExample {
public static String toJSON(ProductInfo productInfo) {
StringBuffer sbf = new StringBuffer();
sbf.append("{\"productID\":\"").append(productInfo.productID);
sbf.append("\",\"categoryID\":\"").append(productInfo.categoryID);
sbf.append("\",\"rank\":").append(productInfo.rank);
sbf.append(",\"inventory\":").append(productInfo.inventory);
sbf.append('}');
return sbf.toString();
}
}Im obigen Beispiel kompiliert der JIT-Compiler toJSON Wenn eine Methode aufgerufen wird, wird die von ihr aufgerufene StringBuffer.append/toString-Methode in die Methode eingebunden, was dem Kopieren der Anweisungen im Methodenkörper der StringBuffer.append/toString-Methode in den toJSON-Methodenkörper entspricht. Die StringBuffer-Instanz sbf ist hier eine lokale Variable, und das von dieser Variable referenzierte Objekt wird nicht in anderen Threads veröffentlicht. Daher kann auf das von sbf referenzierte Objekt nur der aktuelle Ausführungsthread (ein Thread) der Methode zugreifen, in der sich sbf befindet lokalisiert (toJSON-Methode). Daher kann der JIT-Compiler jetzt die interne Sperre beseitigen, die von den Anweisungen in der toJSON-Methode verwendet wird, die aus dem Methodenkörper der StringBuffer.append/toString-Methode kopiert werden. In diesem Beispiel wird die von der StringBuffer.append/toString-Methode selbst verwendete Sperre nicht freigegeben, da es möglicherweise andere Stellen im System gibt, die StringBuffer verwenden, und diese Codes möglicherweise StringBuffer-Instanzen gemeinsam nutzen.
Die Escape-Analysetechnologie, auf der die Sperrenbeseitigungsoptimierung basiert, ist seit Java SE 6u23 standardmäßig aktiviert, die Sperrenbeseitigungsoptimierung wurde jedoch in Java 7 eingeführt.
Wie aus den obigen Beispielen ersichtlich ist, erfordert die Optimierung der Sperreneliminierung möglicherweise auch eine Inline-Optimierung des JIT-Compilers. Ob eine Methode vom JIT-Compiler inline wird, hängt von der Beliebtheit der Methode und der Größe des der Methode entsprechenden Bytecodes (Bytecode-Größe) ab. Ob eine Sperreneliminierungsoptimierung implementiert werden kann, hängt daher auch davon ab, ob die aufgerufene synchronisierte Methode (oder Methode mit synchronisiertem Block) inline sein kann.
Die Optimierung der Sperreneliminierung sagt uns, dass wir Sperren verwenden müssen, wenn wir Sperren verwenden sollten, und dass wir uns nicht zu viele Gedanken über den Overhead von Sperren machen müssen. Entwickler sollten überlegen, ob eine Sperre auf der logischen Ebene des Codes erforderlich ist. Ob eine Sperre auf der Code-Laufebene tatsächlich erforderlich ist, wird vom JIT-Compiler entschieden. Die Optimierung der Sperrenbeseitigung bedeutet nicht, dass Entwickler beim Schreiben von Code nach Belieben interne Sperren verwenden können (Sperren, wenn keine Sperre erforderlich ist), da die Sperrenbeseitigung eine Optimierung ist, die vom JIT-Compiler und nicht von Javac durchgeführt wird und ein Absatzcode nur durch optimiert werden kann der JIT-Compiler, wenn er häufig genug ausgeführt wird. Das heißt, bevor die JIT-Compiler-Optimierung eingreift, bleibt der Overhead dieser Sperre bestehen, solange die interne Sperre im Quellcode verwendet wird. Darüber hinaus haben die vom JIT-Compiler durchgeführte Inline-Optimierung, Escape-Analyse und Sperrenbeseitigungsoptimierung jeweils ihren eigenen Overhead.
Durch die Sperrenbeseitigung wird ThreadLocal verwendet, um ein Thread-sicheres Objekt (z. B. Random) als Thread-spezifisches Objekt zu verwenden. Dadurch werden nicht nur Sperrenkonflikte vermieden, sondern auch alle internen Fehler vollständig beseitigt Diese Objekte sind der Overhead der verwendeten Sperre.
2 Sperrvergröberung
Die Sperrvergröberung (Lock Coarsening/Lock Merging) ist eine vom JIT-Compiler vorgenommene Optimierung der spezifischen Implementierung interner Sperren.
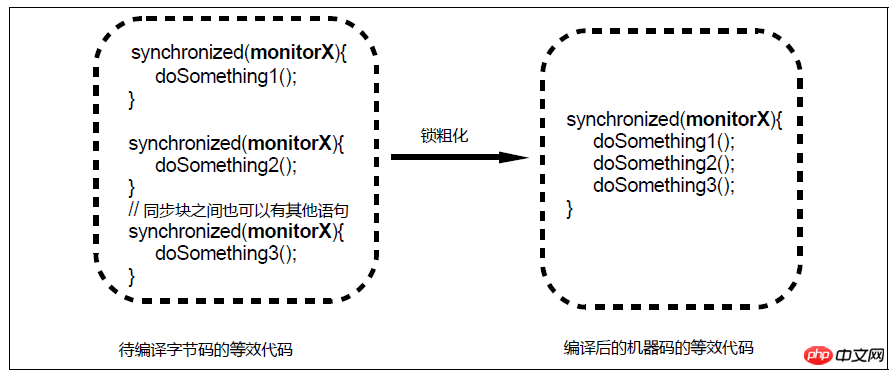
Vergröberungsdiagramm sperren
对于相邻的几个同步块,如果这些同步块使用的是同一个锁实例,那么JIT编译器会将这些同步块合并为一个大同步块,从而避免了一个线程反复申请、释放同一个锁所导致的开销。然而,锁粗化可能导致一个线程持续持有一个锁的时间变长,从而使得同步在该锁之上的其他线程在申请锁时的等待时间变长。例如上图中,第1个同步块结束和第2个同步块开始之间的时间间隙中,其他线程本来是有机会获得monitorX的,但是经过锁粗化之后由于临界区的长度变长,这些线程在申请monitorX时所需的等待时间也相应变长了。因此,锁粗化不会被应用到循环体内的相邻同步块。
相邻的两个同步块之间如果存在其他语句,也不一定就会阻碍JIT编译器执行锁粗化优化,这是因为JIT编译器可能在执行锁粗化优化前将这些语句挪到(即指令重排序)后一个同步块的临界区之中(当然,JIT编译器并不会将临界区内的代码挪到临界区之外)。
实际上,我们写的代码中可能很少会出现上图中那种连续的同步块。这种同一个锁实例引导的相邻同步块往往是JIT编译器编译之后形成的。
例如,在下面的例子中
清单12-2 可进行锁粗化优化的示例代码
public class LockCoarseningExample {
private final Random rnd = new Random();
public void simulate() {
int iq1 = randomIQ();
int iq2 = randomIQ();
int iq3 = randomIQ();
act(iq1, iq2, iq3);
}
private void act(int... n) {
// ...
}
// 返回随机的智商值
public int randomIQ() {
// 人类智商的标准差是15,平均值是100
return (int) Math.round(rnd.nextGaussian() * 15 + 100);
}
// ...
}simulate方法连续调用randomIQ方法来生成3个符合正态分布(高斯分布)的随机智商(IQ)。在simulate方法被执行得足够频繁的情况下,JIT编译器可能对该方法执行一系优化:首先,JIT编译器可能将randomIQ方法内联(inline)到simulate方法中,这相当于把randomIQ方法体中的指令复制到simulate方法之中。在此基础上,randomIQ方法中的rnd.nextGaussian()调用也可能被内联,这相当于把Random.nextGaussian()方法体中的指令复制到simulate方法之中。Random.nextGaussian()是一个同步方法,由于Random实例rnd可能被多个线程共享(因为simulate方法可能被多个线程执行),因此JIT编译器无法对Random.nextGaussian()方法本身执行锁消除优化,这使得被内联到simulate方法中的Random.nextGaussian()方法体相当于一个由rnd引导的同步块。经过上述优化之后,JIT编译器便会发现simulate方法中存在3个相邻的由rnd(Random实例)引导的同步块,于是锁粗化优化便“粉墨登场”了。
锁粗化默认是开启的。如果要关闭这个特性,我们可以在Java程序的启动命令行中添加虚拟机参数“-XX:-EliminateLocks”(开启则可以使用虚拟机参数“-XX:+EliminateLocks”)。
3 偏向锁
偏向锁(Biased Locking)是Java虚拟机对锁的实现所做的一种优化。这种优化基于这样的观测结果(Observation):大多数锁并没有被争用(Contented),并且这些锁在其整个生命周期内至多只会被一个线程持有。然而,Java虚拟机在实现monitorenter字节码(申请锁)和monitorexit字节码(释放锁)时需要借助一个原子操作(CAS操作),这个操作代价相对来说比较昂贵。因此,Java虚拟机会为每个对象维护一个偏好(Bias),即一个对象对应的内部锁第1次被一个线程获得,那么这个线程就会被记录为该对象的偏好线程(Biased Thread)。这个线程后续无论是再次申请该锁还是释放该锁,都无须借助原先(指未实施偏向锁优化前)昂贵的原子操作,从而减少了锁的申请与释放的开销。
然而,一个锁没有被争用并不代表仅仅只有一个线程访问该锁,当一个对象的偏好线程以外的其他线程申请该对象的内部锁时,Java虚拟机需要收回(Revoke)该对象对原偏好线程的“偏好”并重新设置该对象的偏好线程。这个偏好收回和重新分配过程的代价也是比较昂贵的,因此如果程序运行过程中存在比较多的锁争用的情况,那么这种偏好收回和重新分配的代价便会被放大。有鉴于此,偏向锁优化只适合于存在相当大一部分锁并没有被争用的系统之中。如果系统中存在大量被争用的锁而没有被争用的锁仅占极小的部分,那么我们可以考虑关闭偏向锁优化。
偏向锁优化默认是开启的。要关闭偏向锁优化,我们可以在Java程序的启动命令行中添加虚拟机参数“-XX:-UseBiasedLocking”(开启偏向锁优化可以使用虚拟机参数“-XX:+UseBiasedLocking”)。
4 适应性锁
适应性锁(Adaptive Locking,也被称为 Adaptive Spinning )是JIT编译器对内部锁实现所做的一种优化。
存在锁争用的情况下,一个线程申请一个锁的时候如果这个锁恰好被其他线程持有,那么这个线程就需要等待该锁被其持有线程释放。实现这种等待的一种保守方法——将这个线程暂停(线程的生命周期状态变为非Runnable状态)。由于暂停线程会导致上下文切换,因此对于一个具体锁实例来说,这种实现策略比较适合于系统中绝大多数线程对该锁的持有时间较长的场景,这样才能够抵消上下文切换的开销。另外一种实现方法就是采用忙等(Busy Wait)。所谓忙等相当于如下代码所示的一个循环体为空的循环语句:
// 当锁被其他线程持有时一直循环
while (lockIsHeldByOtherThread){}可见,忙等是通过反复执行空操作(什么也不做)直到所需的条件成立为止而实现等待的。这种策略的好处是不会导致上下文切换,缺点是比较耗费处理器资源——如果所需的条件在相当长时间内未能成立,那么忙等的循环就会一直被执行。因此,对于一个具体的锁实例来说,忙等策略比较适合于绝大多数线程对该锁的持有时间较短的场景,这样能够避免过多的处理器时间开销。
事实上,Java虚拟机也不是非要在上述两种实现策略之中择其一 ——它可以综合使用上述两种策略。对于一个具体的锁实例,Java虚拟机会根据其运行过程中收集到的信息来判断这个锁是属于被线程持有时间“较长”的还是“较短”的。对于被线程持有时间“较长”的锁,Java虚拟机会选用暂停等待策略;而对于被线程持有时间“较短”的锁,Java虚拟机会选用忙等等待策略。Java虚拟机也可能先采用忙等等待策略,在忙等失败的情况下再采用暂停等待策略。Java虚拟机的这种优化就被称为适应性锁(Adaptive Locking),这种优化同样也需要JIT编译器介入。
适应性锁优化可以是以具体的一个锁实例为基础的。也就是说,Java虚拟机可能对一个锁实例采用忙等等待策略,而对另外一个锁实例采用暂停等待策略。
从适应性锁优化可以看出,内部锁的使用并不一定会导致上下文切换,这就是我们说锁与上下文切换时均说锁“可能”导致上下文切换的原因。

Das obige ist der detaillierte Inhalt vonAnalyse von vier Möglichkeiten zur Optimierung interner Sperren in der Java Virtual Machine. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Wie können Java-Assertions die Codequalität verbessern und Fehler verhindern?
- Beeinflusst die Deklaration von Strings als „final' in Java „=='-Vergleiche?
- String-Manipulation in Java
- Wie aktualisiere ich JLabel kontinuierlich mit den Ergebnissen einer lang andauernden Aufgabe?
- Wie konvertiere ich int[] in Integer[] zur Verwendung als Map-Schlüssel in Java?