
Heim >Backend-Entwicklung >Python-Tutorial >Python3 implementiert einen Crawler zur Erfassung beliebter Kommentaranalysen von NetEase Cloud Music (Bild)
Python3 implementiert einen Crawler zur Erfassung beliebter Kommentaranalysen von NetEase Cloud Music (Bild)

- 黄舟Original
- 2017-10-09 10:25:352294Durchsuche
Dieser Artikel führt Sie hauptsächlich in die relevanten Informationen zum praktischen Crawler von NetEase Cloud ein. Der Artikel stellt ihn ausführlich anhand von Beispielcode vor. Er hat einen gewissen Referenz-Lernwert für jedermanns Studium oder Arbeit Bitte folgen Sie dem Herausgeber, um gemeinsam zu lernen.
Vorwort
Ich habe gerade erst mit dem Python-Crawler angefangen und seit etwa einem halben Monat kein Python mehr geschrieben, und ich hätte es fast vergessen darüber. Deshalb wollte ich zum Üben einen einfachen Crawler schreiben. Ich hatte das Gefühl, dass die besten Eigenschaften von NetEase Cloud Music die genauen Songempfehlungen und einzigartigen Benutzerrezensionen sind, also habe ich diese Methode geschrieben, um die heißen Rezensionen in der Liste der angesagten Songs von NetEase Cloud Music zu erfassen. Reptil. Ich fange auch gerade erst mit dem Crawlen an. Wenn Sie Kommentare oder Fragen haben, können Sie diese gerne stellen. Lassen Sie uns gemeinsam Fortschritte machen.
Kein Unsinn mehr ~ Werfen wir einen Blick auf die ausführliche Einführung.
Unser Ziel ist es, die beliebten Kommentare aller Songs in den Hot-Song-Rankings in NetEase Cloud zu crawlen.
Dies kann nicht nur den Arbeitsaufwand für das Crawlen reduzieren, sondern auch qualitativ hochwertige Kommentare einsparen.
Implementierungsanalyse
Zuerst öffnen wir die NetEase Cloud-Webversion, wie in der Abbildung gezeigt:
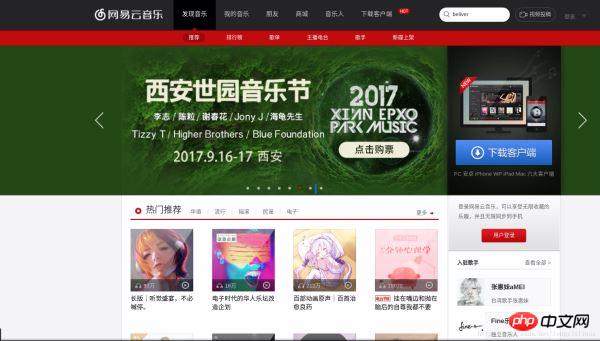
Klicken Sie auf die Rangliste und dann links auf die Cloud-Musik-Hot-Song-Liste, wie im Bild gezeigt:
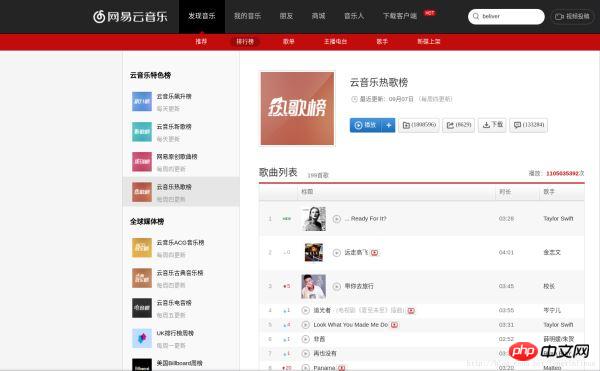
Öffnen wir zunächst zufällig ein Lied und finden Sie heraus, wie Sie die angegebene Methode zum Rezensieren beliebter Lieder finden. Ich habe als Beispiel ein Lied ausgewählt, das mir kürzlich gefallen hat:
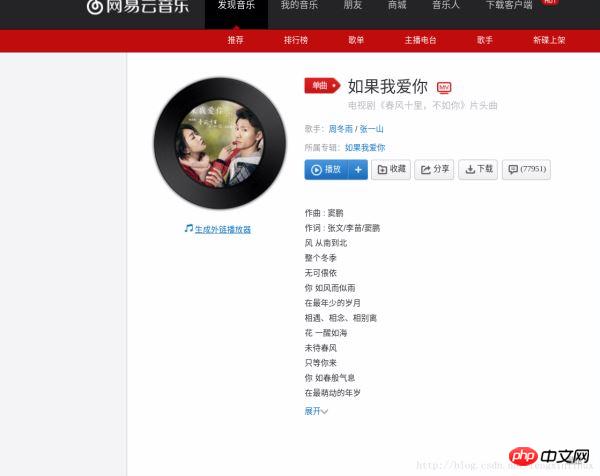
Nach dem Betreten sehen wir die Songrezension unterhalb dieser Seite. Als nächstes müssen wir einen Weg finden, diese Kommentare zu erhalten.
Öffnen Sie als nächstes die Webkonsole (wenn Sie Chrom verwenden, öffnen Sie die Entwicklertools, es sollte für andere Browser ähnlich sein), drücken Sie F12 unter Chrom, wie im Bild gezeigt:
Wählen Sie Netzwerk aus und drücken Sie dann F5 zum Aktualisieren. Die nach der Aktualisierung erhaltenen Daten sind wie folgt:
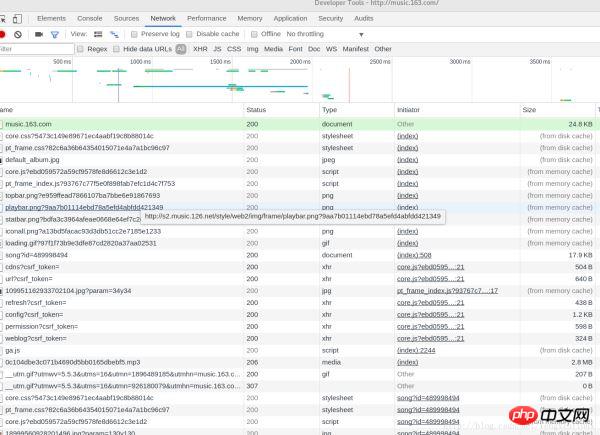
Sie können sehen, dass der Browser Ich habe viele Informationen gesendet. Welche wollen wir also? Hier können wir anhand des Statuscodes eine vorläufige Beurteilung vornehmen. Der Statuscode ist hier 200, was bedeutet, dass die Anfrage normal ist, und 304, was bedeutet, dass sie abnormal ist (es gibt viele Typen). Wenn Sie mehr darüber erfahren möchten, können Sie selbst danach suchen. Auf die spezifische Bedeutung von 304 werde ich hier nicht eingehen. Daher müssen wir uns im Allgemeinen nur Anfragen mit dem Statuscode 200 ansehen. Außerdem können wir durch die Vorschau in der rechten Spalte grob beobachten, welche Informationen der Server zurückgibt (oder die Antwort anzeigen). Durch die Kombination dieser beiden Methoden können wir schnell die Anfrage finden, die wir analysieren möchten. Nach wiederholter Suche habe ich schließlich eine Anfrage mit Songrezensionen gefunden, wie im Bild gezeigt:
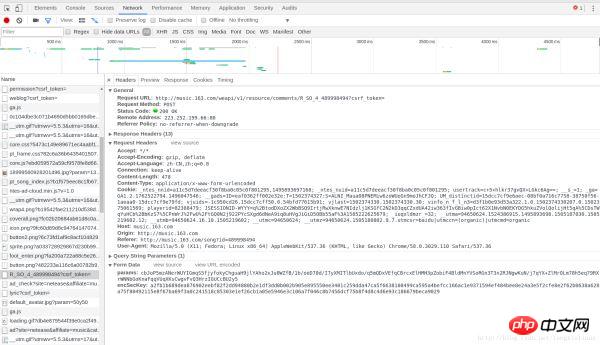
Möglicherweise ist der Screenshot auf CSDN nicht ganz klar, wir befinden uns in einer Datei mit dem Namen R_SO_4_489998494?csrf_token= In der POST-Anfrage wurde eine Songrezension mit diesem Song gefunden. Senden wir diesen Block-Screenshot, damit wir ihn besser sehen können:
Grundlegende Informationen anfordern:

Header anfordern:
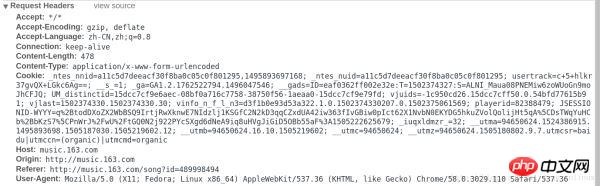
Formulardaten in der Anfrage:

Wir können das sehen, einschließlich dieser Die Anfrage-URL für Songrezensionen ist http://music.163.com/weapi/v1/resource/comments/R_SO_4_489998494?csrf_token= Nachdem wir einige Songs geändert hatten, stellten wir fest, dass der erste Teil der Anfrage derselbe ist Die Zahlenfolge unmittelbar nach R_SO_4_ ist unterschiedlich. Wir können daraus schließen, dass jedes Lied eine bestimmte ID hat und was auf R_SO_4_ folgt, ist die ID des Liedes.
Werfen wir einen weiteren Blick auf die übermittelten Formulardaten? Wir werden feststellen, dass zwei Daten in das Formular eingetragen werden müssen: „params“ und „encSecKey“. Was folgt, ist eine große Zeichenfolge. Wenn Sie einige Songs ändern, werden Sie feststellen, dass die Parameter und der encSecKey jedes Songs unterschiedlich sind. Daher wurden diese beiden Daten möglicherweise durch einen bestimmten Algorithmus verschlüsselt.
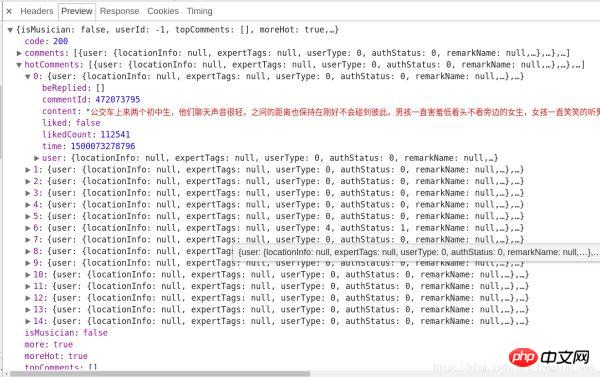
Die vom Server zurückgegebenen kommentarbezogenen Daten liegen im JSON-Format vor und enthalten sehr umfangreiche Informationen (z. B. Informationen zum Kommentator, Kommentardatum, Anzahl der Likes, Kommentarinhalt usw.), darunter hotComments ist unser Es gibt insgesamt 15 beliebte Kommentare, nach denen wir suchen, wie im Bild gezeigt:
An diesem Punkt haben wir die Richtung festgelegt, das heißt wir Es müssen nur die beiden Parameter params und encSecKey ermittelt werden. Aber diese beiden Parameter werden durch einen bestimmten Algorithmus verschlüsselt. Was sollen wir tun? Ich habe ein Muster gefunden: http://music.163.com/weapi/v1/resource/comments/R_SO_4_489998494?csrf_token= Die Zahl nach R_SO_4_ ist der ID-Wert dieses Songs und für verschiedene Songs der Parameter- und encSecKey-Wert. Wenn Sie diese beiden Parameterwerte eines Songs wie A an Song B übergeben, ist dieser Parameter für die gleiche Anzahl von Seiten universell, dh die beiden Parameterwerte der ersten Seite von A wird an Song B übergeben. Für die beiden Parameter jedes anderen Songs können Sie die Kommentare auf der ersten Seite des entsprechenden Songs abrufen. Dasselbe gilt für die zweite Seite, die dritte Seite usw.
Und wir brauchen eigentlich nur die 15 beliebten Kommentare auf der ersten Seite, also müssen wir nur einen Song finden und die Parameter und den encSecKey in der Anfrage auf der ersten Seite des Songs hinzufügen Diese beiden Parameterwerte und Sie können sie verwenden.
Auf die Frage, wie man diese beiden Parameter entschlüsselt, gibt es tatsächlich eine Antwort auf das mächtige Zhihu. Interessierte Freunde können einen Blick darauf werfen (https://www.zhihu.com/question). / 36081767), wir müssen hier nur unsere Lazy-Methode verwenden, um die Anforderungen zu erfüllen, xixi.
Bisher haben wir analysiert, wie die beliebten Kommentare von NetEase Cloud Music erfasst werden. Lassen Sie uns analysieren, wie Sie die Informationen aller Songs in der Hot-Song-Liste von Cloud Music erhalten.
Wir müssen die Songnamen und die entsprechenden ID-Werte aller Songs in der Cloud-Musik-Hot-Song-Liste abrufen.
Ähnlich wie bei den obigen Analyseschritten geben wir zunächst die URL der Hot-Song-Liste ein, wie im Bild gezeigt:
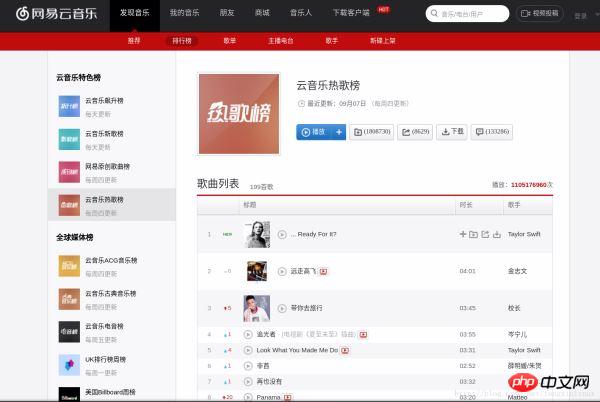
Drücken Sie F12 um die WEB-Workbench aufzurufen, wie im Bild gezeigt:
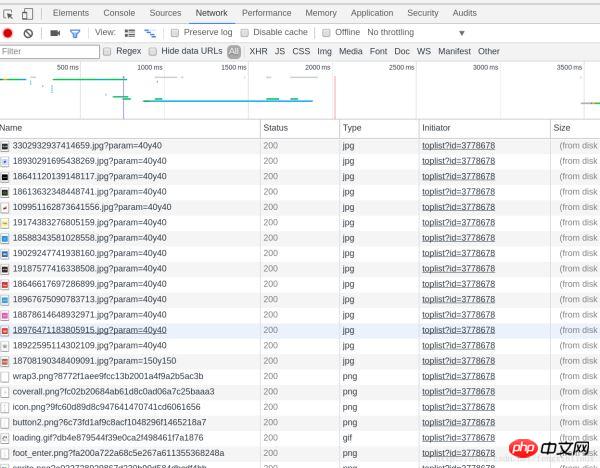
Wir haben alle Songinformationen dieser Liste in einer GET-Anfrage mit dem Namen toplist?id=3778678 gefunden.
Die der Anfrage entsprechenden Informationen sind wie in der Abbildung dargestellt:
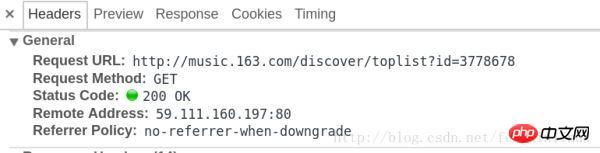
Sehen wir uns eine Vorschau der von der Anfrage zurückgegebenen Ergebnisse an, wie in der Abbildung dargestellt:
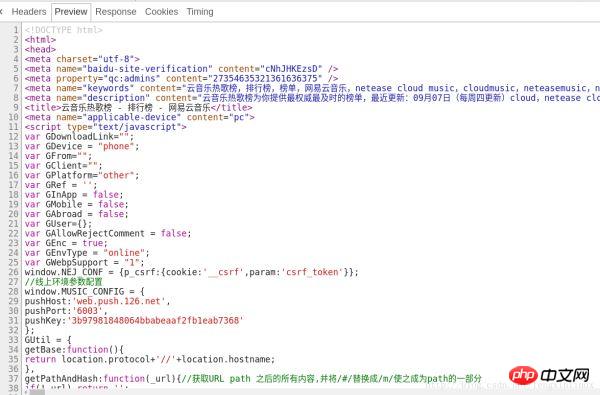
Wir haben den Code mit den Songinformationen in Zeile 524 des Codes gefunden, wie in der Abbildung gezeigt:
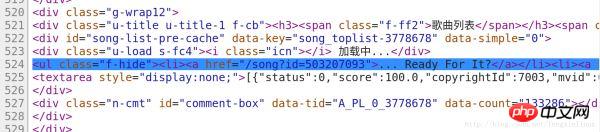
Daher müssen wir nur den Anforderungscode hinzufügen und Codes mit Informationen herausfiltern.
Hier verwenden wir reguläre Ausdrücke zur Datenfilterung.
Durch Beobachtung der Eigenschaften können wir die benötigten Songinformationen über zwei reguläre Ausdrucksfilter extrahieren.
Für den ersten regulären Ausdruck haben wir die 525. Codezeile aus allen von der Anfrage zurückgegebenen Codes extrahiert.
Der erste reguläre Ausdruck lautet wie folgt:
<ul class="f-hide"> <li> <a href="/song\?id=\d*?" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >.*</a> </li> </ul>
Mit dem zweiten regulären Ausdruck extrahieren wir die Songinformationen, die wir in Zeile 524 benötigen. Wir benötigen den Songtitel und die Song-ID , der entsprechende reguläre Ausdruck lautet wie folgt:
Holen Sie sich den Songtitel:
<li><a href="/song\?id=\d*?" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >(.*?)</a></li>
Holen Sie sich die Song-ID:
<li><a href="/song\?id=(\d*?)" rel="external nofollow" rel="external nofollow" >.*?</a></li>
bis An diesem Punkt , wir haben den gesamten Prozess analysiert. Schauen wir uns den Code an, um die spezifischen Details zu sehen. ~~
Der Code lautet wie folgt:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import re
import urllib.request
import urllib.error
import urllib.parse
import json
def get_all_hotSong(): #获取热歌榜所有歌曲名称和id
url='http://music.163.com/discover/toplist?id=3778678' #网易云云音乐热歌榜url
html=urllib.request.urlopen(url).read().decode('utf8') #打开url
html=str(html) #转换成str
pat1=r'<ul class="f-hide"><li><a href="/song\?id=\d*?">.*</a></li></ul>' #进行第一次筛选的正则表达式
result=re.compile(pat1).findall(html) #用正则表达式进行筛选
result=result[0] #获取tuple的第一个元素
pat2=r'<li><a href="/song\?id=\d*?">(.*?)</a></li>' #进行歌名筛选的正则表达式
pat3=r'<li><a href="/song\?id=(\d*?)">.*?</a></li>' #进行歌ID筛选的正则表达式
hot_song_name=re.compile(pat2).findall(result) #获取所有热门歌曲名称
hot_song_id=re.compile(pat3).findall(result) #获取所有热门歌曲对应的Id
return hot_song_name,hot_song_id
def get_hotComments(hot_song_name,hot_song_id):
url='http://music.163.com/weapi/v1/resource/comments/R_SO_4_' + hot_song_id + '?csrf_token=' #歌评url
header={ #请求头部
'User-Agent':'Mozilla/5.0 (X11; Fedora; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
#post请求表单数据
data={'params':'zC7fzWBKxxsm6TZ3PiRjd056g9iGHtbtc8vjTpBXshKIboaPnUyAXKze+KNi9QiEz/IieyRnZfNztp7yvTFyBXOlVQP/JdYNZw2+GRQDg7grOR2ZjroqoOU2z0TNhy+qDHKSV8ZXOnxUF93w3DA51ADDQHB0IngL+v6N8KthdVZeZBe0d3EsUFS8ZJltNRUJ','encSecKey':'4801507e42c326dfc6b50539395a4fe417594f7cf122cf3d061d1447372ba3aa804541a8ae3b3811c081eb0f2b71827850af59af411a10a1795f7a16a5189d163bc9f67b3d1907f5e6fac652f7ef66e5a1f12d6949be851fcf4f39a0c2379580a040dc53b306d5c807bf313cc0e8f39bf7d35de691c497cda1d436b808549acc'}
postdata=urllib.parse.urlencode(data).encode('utf8') #进行编码
request=urllib.request.Request(url,headers=header,data=postdata)
reponse=urllib.request.urlopen(request).read().decode('utf8')
json_dict=json.loads(reponse) #获取json
hot_commit=json_dict['hotComments'] #获取json中的热门评论
num=0
fhandle=open('./song_comments','a') #写入文件
fhandle.write(hot_song_name+':'+'\n')
for item in hot_commit:
num+=1
fhandle.write(str(num)+'.'+item['content']+'\n')
fhandle.write('\n==============================================\n\n')
fhandle.close()
hot_song_name,hot_song_id=get_all_hotSong() #获取热歌榜所有歌曲名称和id
num=0
while num < len(hot_song_name): #保存所有热歌榜中的热评
print('正在抓取第%d首歌曲热评...'%(num+1))
get_hotComments(hot_song_name[num],hot_song_id[num])
print('第%d首歌曲热评抓取成功'%(num+1))
num+=1Die Ergebnisse der Ausführung des Codes sind wie folgt:
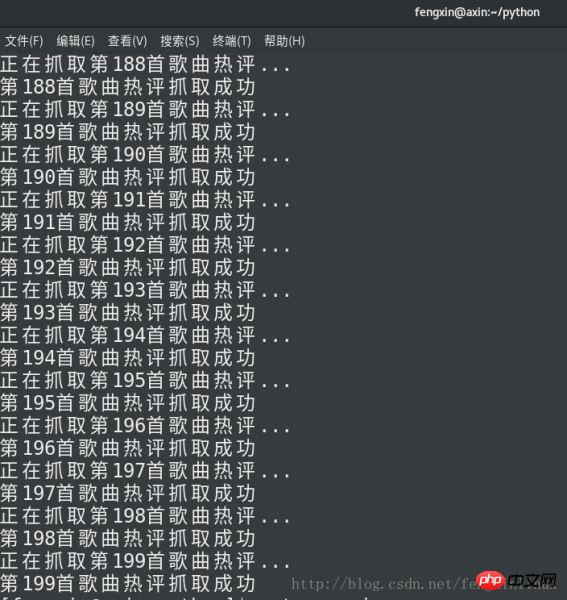
Vergleichen Sie die Songrezensionen des Songs „If I.“ Love You“ auf der Webseite mit den von uns gespeicherten Songs. Kommentare:
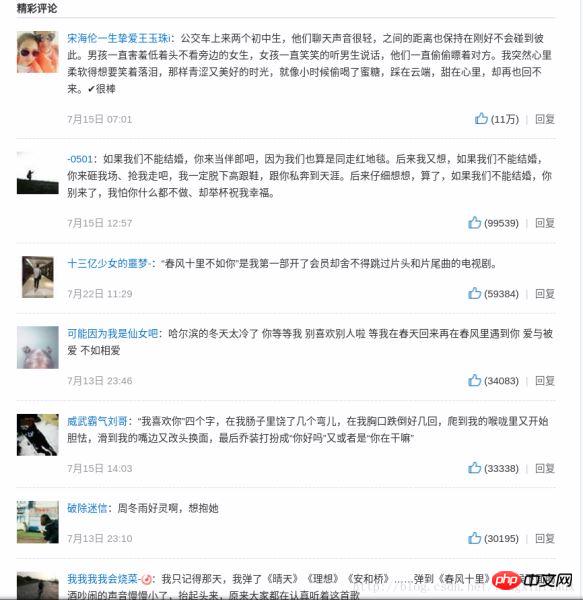

Korrekte Informationen~
Zusammenfassung
Das obige ist der detaillierte Inhalt vonPython3 implementiert einen Crawler zur Erfassung beliebter Kommentaranalysen von NetEase Cloud Music (Bild). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!