
Heim >Datenbank >MySQL-Tutorial >Welche Vorgänge beziehen sich auf MySQL?
Welche Vorgänge beziehen sich auf MySQL?
- 一个新手Original
- 2017-09-30 09:59:022140Durchsuche
1》Datenbank erstellen:
Syntax: Datenbank erstellen Datenbankname;
Syntax: Datenbanken anzeigen Vorhandene Datenbanken anzeigen
Beispiel:
Mysql->create database zytest; 注意每一条要以;号结尾 Mysql->show databases;查询是否创建成功 >use zytest;
🎜>2》Datenbank löschen: 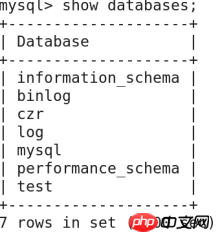 Syntax: Datenbankname löschen; e90ba6f3cb1fcaa1a0e6b0648bec2c2a
Syntax: Datenbankname löschen; e90ba6f3cb1fcaa1a0e6b0648bec2c2a
Mysql->Datenbank löschen zytest
Mysql- >Datenbanken anzeigen; erfolgreich
3> Einführung in die Speicher-Engine:
1>innoDB-Engine
innoDB ist die erste Tabellen-Engine, die Fremdschlüsseleinschränkungen bereitstellt und Transaktionen mit innoDB verarbeiten kann. Es ist auch etwas, mit dem andere Motoren nicht mithalten können. ,  Innodb unterstützt die automatische Inkrementierung von Spalten mithilfe von auto_increment. Der Wert der automatisch inkrementierten Spalte darf nicht leer sein.
Innodb unterstützt die automatische Inkrementierung von Spalten mithilfe von auto_increment. Der Wert der automatisch inkrementierten Spalte darf nicht leer sein.
Erstellen Sie in der innodb-Speicher-Engine eine Tabelle. Die Tabellenstruktur wird in der .frm-Datei gespeichert, und die Daten und Indizes werden in dem durch innodb_data_home_dir und innodb_data_file_path definierten Tabellenbereich gespeichert. Standardmäßig werden die Metadaten jeder Datentabelle in InnoDB immer im gemeinsam genutzten Tabellenbereich ibdata1 gespeichert, daher ist diese Datei unbedingt erforderlich
innodb_data_file_path = ibdata1:10M:autoextend
Daten- und Indexdateien werden zusammengefasst: *.ibd Jede Tabelle hat separate Metadaten,
Gesamtmetadaten aller Tabellen Die Datei ist ibdata1 Inoodb-Speicher-Engine Vorteile: Sie bietet eine gute Transaktionsverwaltung, Absturz-, Reparaturfunktionen und Parallelitätskontrolle. Nachteile: Die Lese- und Schreibeffizienz ist etwas schlecht und der von ihr belegte Datenraum ist relativ klein.
Was ist eine Transaktion? ? Werfen wir zunächst einen Blick auf die ACID-Prinzipien
ACID sind die vier Grundelemente für die normale Ausführung von Datenbanktransaktionen, die sich auf Atomizität, Konsistenz, Unabhängigkeit und Haltbarkeit beziehen
Die Atomizität einer Transaktion bedeutet, dass eine Transaktion entweder vollständig ausgeführt wird oder nicht. Mit anderen Worten: Eine Transaktion kann nicht nur zur Hälfte ausgeführt werden und dann beispielsweise gestoppt werden Der Vorgang kann in zwei Schritte unterteilt werden: 1. Durchziehen der Karte, 2. Abheben des Geldes. Es ist nicht möglich, die Karte durchzuziehen, aber das Geld wird nicht gleichzeitig ausgegeben. Konsistenz (Konsistenz) 2>MyISAM-Engine 4》Speicher-Engine anzeigen: 1> Abfrage der von MySQL unterstützten Engines; 3>查询Mysql默认存储引擎 如果想修改存储引擎,可以在 my.ini中进行修改或者my.cnf中的Default-storage-engine=引擎类型; 5》如何选择存储引擎: 在企业生产环境中,选择一个款合适的存储引擎是一个很复杂的问题。每一种存储引擎都有各自的优势,不能笼统的说,谁比谁好。通常用的比较多的 是innodb存储引擎 ==========================创建,修改,删除表: 1》创建表的方法: 2》表的完整性约束: | 约束条件 | 说明| | (1)primary key | 标识该字段为表的主键,具备唯一性| | (2)foreign key | 标识该字段为表的外键,与某表的主键联系| | (3)not null | 标识该属于的值不能为空| | (4)unique | 标识这个属性值是唯一| | (5)auto_increment | 标识该属性值的自动增加 | (6)default | 为该属性值设置默认值| 1>设置表的主键: 举例: 2>设置多个字段做主键 3>设置表的外键: (1) yy1表存储了zhangsan姓名和ID号 (2) yy2表存储了ID号和zhangsan的年龄(old) (3)数据填充yy1和yy2表 (4)更新测试: (5)删除测试: 4>设置表的非空值 5> 设置表的唯一性约束 6>设置表的属性值自动增加 7>、设置表的默认值 插入数据,应为ID为自增,值为空,user_name设置了默认值,所以也为空。 3》查看表结构的方法: 2>修改表的数据类型 3>修改表的字段名称 4>修改增加字段 v 增加没有约束条件的字段: v 增加有完整约束条件的字段 v 在表的第一个位置增加字段默认情况每次增加的字段。都在表的最后。 v 执行在那个位置插入新的字段,在phone后面增加 总结: 6>更改表的存储引擎 7>删除表的外键约束 4》删除表的方法 1>删除没有被关联的普通表
:
Transaktionskonsistenz bedeutet, dass die Ausführung der Transaktion die Konsistenz der Daten in der Datenbank nicht verändert. Beispielsweise die Integritätsbeschränkung a+b =10, wenn eine Transaktion a ändert, sollte sich auch b entsprechend ändern. Isolation :
Die Unabhängigkeit einer Transaktion wird auch Isolation genannt, was bedeutet, dass zwei oder mehr Transaktionen werden nicht verschachtelt ausgeführt, da dies zu Dateninkonsistenzen führen kann Dauerhaftigkeit (Dauerhaftigkeit)
:Die Dauerhaftigkeit einer Transaktion bezieht sich auf die Änderungen Durch die Transaktion an der Datenbank vorgenommene Änderungen werden dauerhaft in der Datenbank gespeichert und werden nicht ohne Grund zurückgesetzt
Die MyISAM-Speichertabelle ist in 3 Dateien unterteilt. Die Datei- und Tabellennamen sind gleich und die Erweiterungen umfassen frm, MYD und MYI frm ist die Erweiterung
myd Speichert Daten für Dateien mit Erweiterungen
Myi speichert Indizes für Dateien mit Erweiterungen
Vorteile: Geringer Platzbedarf. Schnelle Verarbeitungsgeschwindigkeit,
Nachteile: Unterstützt nicht die Integrität und Parallelität von Transaktionsprotokollen 3>MEMORY Engine Die spezielle Engine in MySQL, alle Daten werden im Speicher in der Produktionsumgebung des Unternehmens gespeichert. Fast nutzlos. Da die Daten im Speicher gespeichert werden, tritt eine Ausnahme im Speicher auf. Wird die Integrität der Daten beeinträchtigen. Vorteile: Schnelle Speicherung
MyISAM: unterstützt keine Fremdschlüssel, unterstützt keine Transaktionen, Indizes und Daten sind getrennt und mehr kann geladen werden Index, und der Index ist komprimiert, die Nutzungseffizienz ist im Vergleich zum Speicher erheblich verbessert. Er verwendet einen Tabellensperrmechanismus, um mehrere gleichzeitige Lese- und Schreibvorgänge zu optimieren. Verwendungszweck: In einer Projektplattform Hostet die meisten Projekte, die mehr lesen und weniger schreiben. Die Leseleistung von MyISAM ist viel besser als die von Innodb
Innodb: unterstützt Fremdschlüssel, unterstützt Transaktionen und Rollback, aber der Index und die Daten sind es fest gebunden und es wird keine Komprimierung verwendet, was dazu führt, dass INNODB viel größer als MYISAM ist.
Verwendungszwecke: Wenn Sie bei den meisten gehosteten Projekten Einfügungen und Aktualisierungen durchführen möchten, sollten Sie InnoDB wählen.
Einführung in Sperren: In MySQL gibt es drei gängige Sperrebenen: Sperren auf Tabellenebene, Sperren auf Zeilenebene und Sperren auf Zeilenebene von Sperren auf Tabellenebene – Gemeinsame Lesesperre für die Tabelle und exklusive Schreibsperre für die Tabelle.
MyISAM: Sperre auf Tabellenebene : Beim Durchführen eines Lesevorgangs für die Myisam-Tabelle werden die Leseanforderungen anderer Benutzer für dieselbe Tabelle nicht blockiert, es werden jedoch Schreibvorgänge für dieselbe Tabelle blockiert>; Es blockiert die Lese- und Schreibanforderungen anderer Benutzer für dieselbe Tabelle. 🎜>
Bietet Zeilensperren (Sperren auf Zeilenebene). Sperren von InnoDB-Tabellen sind nicht absolut. Wenn der zu scannende Bereich nicht bestimmt werden kann, sperrt die InnoDB-Tabelle auch die gesamte Tabelle 🎜> 1) Reduzieren Sie den LOCK-Status, wenn viele Verbindungen unterschiedliche Abfragen durchführen.
2) Wenn eine Ausnahme auftritt, kann der Datenverlust reduziert werden. Weil Sie jeweils nur eine Zeile oder einige Zeilen mit kleinen Datenmengen zurücksetzen können. Die Nachteile von Sperren auf Zeilenebene sind folgende: 1) Sie beanspruchen mehr Speicher als Sperren auf Seitenebene und Sperren auf Tabellenebene. 2) Abfragen erfordern mehr E/A als Sperren auf Seiten- und Tabellenebene, daher verwenden wir häufig Sperren auf Zeilenebene für Schreibvorgänge statt für Lesevorgänge. 3) Es besteht die Gefahr eines Deadlocks.
Hinweis: Inodb kann die Zeile der Operation nicht ermitteln, d. h. die Tabellensperre auf Zeilenebene.
2> MySQL-Engine-Details abfragen: Mysql->show engine innodb status\G;
Mysql-> show variables like 'storage_engine';

以下是存储引擎的对比: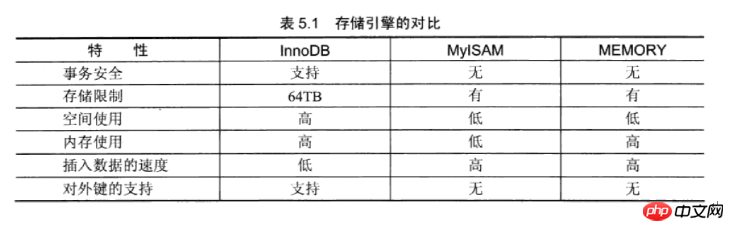
语法:create table 表名(
属性名数据类型完整约束条件,
属性名数据类型条完整约束件,
。。。。。。。。。
属性名数据类型
);
举例: create table example0(
id int,
name varchar(20),
sexboolean);
主键是一个表的特殊字段,这个字段是唯一标识表中的每条信息,主键和记录的关系,跟人的身份证一样。名字可以一样,但是身份证号码觉得不会一样, 主键用来标识每个记录,每个记录的主键值都不同,主键可以帮助Mysql以最快的速度查找到表中的某一条信息,主键必须满足的条件那就是它的唯一性,表中的 任意两条记录的主键值,不能相同,否则就会出现主键值冲突,主键值不能为空,可以是单一的字段,也可以多个字段的组合。 create table sxkj(
User_id int primary key,
user_name varchar(20),
user_sexchar(7));
举例: create table sxkj2(
user_id int ,
user_name float,
grade float,
primary key(user_id,user_name));
外键是表的一个特殊字段,如果aa是B表的一个属性且依赖于A表的主键,那么A表被称为父表。B表为被称为子表,
举例说明:
user_id 是A 表的主键,aa 是B表的外键,那么user_id的值为zhangsan,如果这个zhangsan离职了,需要从A表中删除,那么B表关于 zhangsan的信息也该得到相应的删除,这样可以保证信息的完整性。
语法:
constraint外键别名 foreign key(外键字段1,外键字段2)
references 表名(关联的主键字段1,主键字段2)
create table yy1(
user_id int primary key not null,
user_name varchar(20));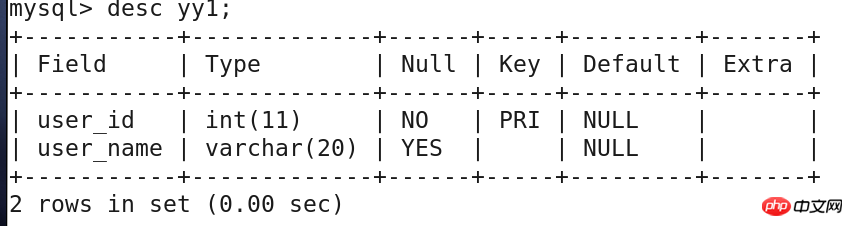
create table yy2(
user_id int primary key not null,
old int(5),
constraint y_fk foreign key(user_id)
references yy1(user_id)on delete cascade on update cascade);
insert into yy1 values('110','zhangsan');
insert into yy2 values('110','30');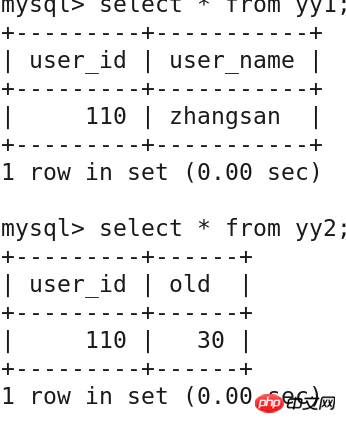
update yy1 set user_id='120' where user_name='zhangsan';
查询验证
select * from yy2;
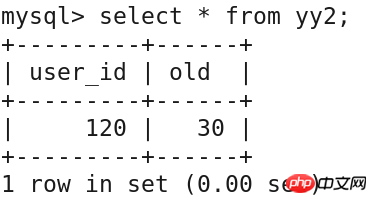
delete from yy1 where user_id='120';
查询验证
select * from yy2;

语法:属性名数据类型 NOT NULL
举例: create table C(
user_id int NOT NULL);
唯一性指的就是所有记录中该字段。不能重复出现。
语法:属性名数据类型 unique
举例: root@zytest 15:43>create table D(
->user_id int unique);
root@zytest 15:44>show create table D;
Auto_increment 是Mysql数据库中特殊的约束条件,它的作用是向表中插入数据时自动生成唯一的ID,一个表只能有一个字段使用 auto_increment 约束,必须是唯一的;
语法:属性名数据类型 auto_increment,默认该字段的值从1开始自增。
举例:
create table F( user_id int primary key auto_increment);
root@zytest 15:56>insert into F values();插入一条空的信息
Query OK, 1 row affected, 1 warning (0.00 sec)
root@zytest 15:56>select * from F;值自动从1开始自增
+---------+
| user_id |
+---------+
| 1 |
+---------+
1 row in set (0.01 sec)
在创建表时,可以指定表中的字段的默认值,如果插入一条新的纪录时,没有给这个字段赋值,那么数据库会自动的给这个字段插入一个默认 值,字段的默认值用default来设置。
语法: 属性名数据类型 default 默认值
举例: root@zytest 16:05>create table G(
user_id int primary key auto_increment,
user_name varchar(20) default 'zero');
root@zytest 16:05>insert into G values('','');
DESCRIBE可以查看那表的基本定义,包括、字段名称,字段的数据类型,是否为主键以及默认值等。。
(1)语法:describe 表名;可以缩写为desc
(2) show create table查询表详细的结构语句,
1>修改表名
语法:alter table 旧表名 rename 新表名;
举例; root@zytest 16:11>alter table A rename zyA;
Query OK, 0 rows affected (0.02 sec)
语法:alter table 表名 modify 属性名 数据类型;
举例; root@zytest 16:15>alter table A modify user_name double;
Query OK, 0 rows affected (0.18 sec)
语法: alter table 表名 change 旧属性名 新属性名 新数据类型; root@zytest 16:15>alter table A change user_name user_zyname float;
Query OK, 0 rows affected (0.10 sec) alter table 表名 ADD 属性名1 数据类型 [完整性约束条件] [FIRST |AFTER 属性名2]
root@zytest 16:18>alter table A add phone varchar(20);
Query OK, 0 rows affected (0.13 sec)root@zytest 16:42>alter table A add age int(4) not null;
Query OK, 0 rows affected (0.13 sec)root@zytest 16:45>alter table tt add num int(8) primary key first;
Query OK, 1 row affected (0.12 sec)
Records: 1 Duplicates: 0 Warnings: 0 root@zytest 16:46>alter table A add address varchar(30) not null after phone;
Query OK, 0 rows affected (0.10 sec)
Records: 0 Duplicates: 0 Warnings: 0
(1) 默认ADD 增加字段是在最后面增加
(2) 如果想在表的最前端增加字段用first关键字
(3) 如果想在某一个字段后面增加的新的字段,使用after关键字
5>删除一个字段
alter table 表名DROP 属性名;
举例: 删除A 表的age字段 root@zytest 16:51>alter table A drop age;
Query OK, 0 rows affected (0.11 sec)
Records: 0 Duplicates: 0 Warnings: 0 alter table表名 engine=存储引擎
alter table A engine=MyISAM; alter table 表名drop foreign key 外键别名;
alter table yy2 drop foreign key y_fk;
drop table 表名;
2>删除被其它表关联的父表
在数据库中某些表之间建立了一些关联关系。一些成为了父表,被其子表关联,要删除这些父表,就不是那么简单了。删除方法,先删除所关联的 子表的外键,在删除主表。
Das obige ist der detaillierte Inhalt vonWelche Vorgänge beziehen sich auf MySQL?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!