
Heim >Backend-Entwicklung >Python-Tutorial >So verwenden Sie Haystack mit Django in Python: ein Beispiel für das Volltextsuch-Framework
So verwenden Sie Haystack mit Django in Python: ein Beispiel für das Volltextsuch-Framework

- 黄舟Original
- 2017-10-03 06:00:562191Durchsuche
Der folgende Editor bringt Ihnen einen Artikel über die Verwendung von Haystack mit Python Django: Volltextsuch-Framework (Erklärung mit Beispielen). Der Herausgeber findet es ziemlich gut, deshalb teile ich es jetzt mit Ihnen und gebe es als Referenz. Folgen wir dem Herausgeber, um einen Blick darauf zu werfen
Heuhaufen: ein Framework für die Volltextsuche
whoosh: geschrieben in reiner Python-Volltextsuchmaschine
jieba: ein kostenloses chinesisches Wortsegmentierungspaket
Diese drei Pakete zuerst installieren
pip install django-haystack
pip install whoosh
pip install jieba
1. Ändern Sie die Datei „settings.py“. und installieren Sie die Anwendung Heuhaufen,
2. Konfigurieren Sie die Suchmaschine in der Datei „settings.py“
HAYSTACK_CONNECTIONS = {
'default': {
# 使用whoosh引擎
'ENGINE': 'haystack.backends.whoosh_cn_backend.WhooshEngine',
# 索引文件路径
'PATH': os.path.join(BASE_DIR, 'whoosh_index'),
}
}
# 当添加、修改、删除数据时,自动生成索引
HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'3. blog/“ im Vorlagenverzeichnis „Das Verzeichnis verwendet den Namen der Blog-Anwendung, um eine Datei zu erstellen blog_text.txt
#Geben Sie das Indexattribut an
{{ object.title }}
{{ object.text}}
{{ object .keywords }}
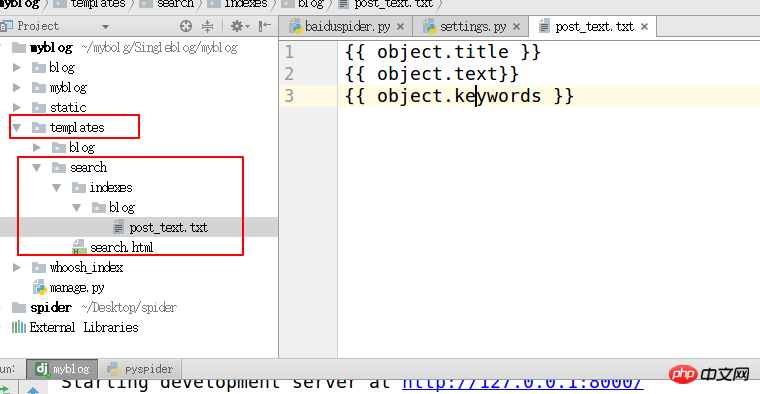
4. Suchindizes erstellen
from haystack import indexes from models import Post #指定对于某个类的某些数据建立索引 class GoodsInfoIndex(indexes.SearchIndex, indexes.Indexable): text = indexes.CharField(document=True, use_template=True) def get_model(self): return Post #搜索的模型类 def index_queryset(self, using=None): return self.get_model().objects.all()
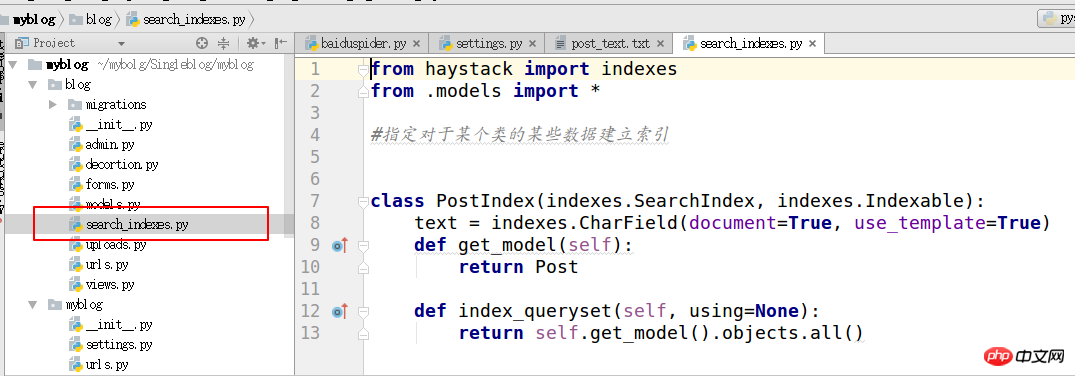 unter der Anwendung, die durchsucht werden muss
unter der Anwendung, die durchsucht werden muss
5.
1. Ändern Sie die Heuhaufendatei
2. Finden Sie den Heuhaufen Verzeichnis unter der virtuellen Umgebung py_django. Dieses Verzeichnis ist je nach verwendeter Python-Umgebung unterschiedlich, auch die Pfade sind unterschiedlich.
3. site-packages/haystack/backends/ Erstellen Sie eine Datei mit dem Namen ChineseAnalyzer.py und schreiben Sie den folgenden Code für die chinesische Wortsegmentierung
import jieba
from whoosh.analysis import Tokenizer, Token
class ChineseTokenizer(Tokenizer):
def __call__(self, value, positions=False, chars=False,
keeporiginal=False, removestops=True,
start_pos=0, start_char=0, mode='', **kwargs):
t = Token(positions, chars, removestops=removestops, mode=mode,
**kwargs)
seglist = jieba.cut(value, cut_all=True)
for w in seglist:
t.original = t.text = w
t.boost = 1.0
if positions:
t.pos = start_pos + value.find(w)
if chars:
t.startchar = start_char + value.find(w)
t.endchar = start_char + value.find(w) + len(w)
yield t
def ChineseAnalyzer():
return ChineseTokenizer() 6.
1. Kopieren Sie die Datei whoosh_backend.py und ändern Sie sie in den folgenden Namen
whoosh_cn_backend.py
Importieren Sie das chinesische Wortsegmentierungsmodul in die kopierte Datei Datei
aus .ChineseAnalyzer import ChineseAnalyzer
2. Ändern Sie die Wortanalyseklasse in Chinesisch
Suchen Sie nach „analysator=StemmingAnalyzer()“ und ändern Sie sie in „analysator=ChineseAnalyzer()“ 🎜>
7. Der letzte Schritt besteht darin, erste Indexdaten zu erstellenpython manage.py rebuild_index8. Suchvorlage in Vorlagen/Indizes erstellen/Suchvorlage erstellen Suchergebnisse Für Paging lautet der von der Ansicht an die Vorlage übergebene Kontext wie folgt Abfrage: Suchbegriffeclass GoodsSearchView(SearchView): def get_context_data(self, *args, **kwargs): context = super().get_context_data(*args, **kwargs) context['iscart']=1 context['qwjs']=2 return contextFügen Sie diese URL zur URL-Datei der Anwendung hinzu.
Das obige ist der detaillierte Inhalt vonSo verwenden Sie Haystack mit Django in Python: ein Beispiel für das Volltextsuch-Framework. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!