
Heim >Backend-Entwicklung >Python-Tutorial >Analysieren Sie verschiedene Möglichkeiten, wie Python XML analysiert
Analysieren Sie verschiedene Möglichkeiten, wie Python XML analysiert
- 巴扎黑Original
- 2017-09-19 10:20:272694Durchsuche
Als ich PYTHON zum ersten Mal lernte, wusste ich nur, dass es zwei Parsing-Methoden gibt: DOM und SAX, aber ihre Effizienz war nicht ideal. Aufgrund der großen Anzahl von Dateien, die verarbeitet werden mussten, waren diese beiden Methoden zu zeitaufwändig. aufwendig und inakzeptabel.
Nachdem ich im Internet gesucht hatte, stellte ich fest, dass ElementTree, das derzeit weit verbreitet und relativ effizient ist, auch ein von vielen Leuten empfohlener Algorithmus ist, daher habe ich diesen Algorithmus für tatsächliche Messungen und Vergleiche verwendet Implementierungen, eine ist Normal ElementTree(ET), eine ist ElementTree.iterparse(ET_iter).
In diesem Artikel wird ein horizontaler Vergleich der vier Methoden DOM, SAX, ET und ET_iter durchgeführt und die Effizienz jedes Algorithmus bewertet, indem die Zeit verglichen wird, die zum Verarbeiten derselben Dateien benötigt wird.
Im Programm werden die vier Parsing-Methoden als Funktionen geschrieben und im Hauptprogramm separat aufgerufen, um ihre Parsing-Effizienz zu bewerten.
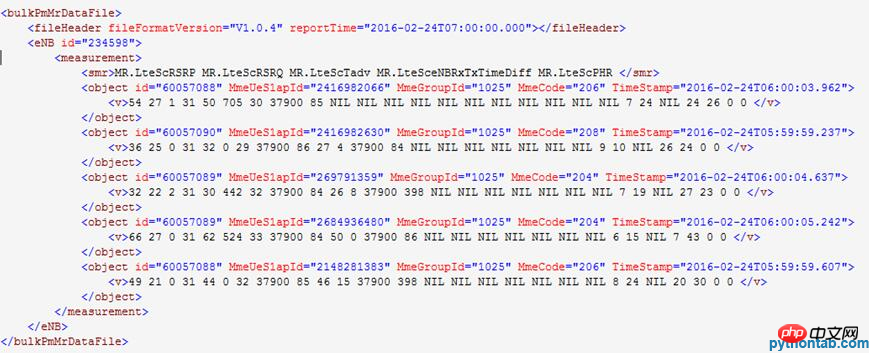
Das Beispiel für den Inhalt einer dekomprimierten XML-Datei lautet:
Der Teilcode des Hauptprogrammfunktionsaufrufs lautet:
print("文件计数:%d/%d." % (gz_cnt,paser_num))
str_s,cnt = dom_parser(gz)
#str_s,cnt = sax_parser(gz)
#str_s,cnt = ET_parser(gz)
#str_s,cnt = ET_parser_iter(gz)
output.write(str_s)
vs_cnt += cntAm Anfang Beim Funktionsaufruf gibt die Funktion zwei Werte zurück, aber beim Empfang des Funktionsaufrufwerts wird sie mit zwei Variablen separat aufgerufen, wodurch jede Funktion zweimal ausgeführt wird. Später wurde geändert, dass zwei Variablen gleichzeitig aufgerufen werden, um den Rückgabewert zu empfangen , wodurch ungültige Anrufe reduziert wurden.
1. DOM-Analyse
Funktionsdefinitionscode:
def dom_parser(gz):
import gzip,cStringIO
import xml.dom.minidom
vs_cnt = 0
str_s = ''
file_io = cStringIO.StringIO()
xm = gzip.open(gz,'rb')
print("已读入:%s.\n解析中:" % (os.path.abspath(gz)))
doc = xml.dom.minidom.parseString(xm.read())
bulkPmMrDataFile = doc.documentElement
#读入子元素
enbs = bulkPmMrDataFile.getElementsByTagName("eNB")
measurements = enbs[0].getElementsByTagName("measurement")
objects = measurements[0].getElementsByTagName("object")
#写入csv文件
for object in objects:
vs = object.getElementsByTagName("v")
vs_cnt += len(vs)
for v in vs:
file_io.write(enbs[0].getAttribute("id")+' '+object.getAttribute("id")+' '+\
object.getAttribute("MmeUeS1apId")+' '+object.getAttribute("MmeGroupId")+' '+object.getAttribute("MmeCode")+' '+\
object.getAttribute("TimeStamp")+' '+v.childNodes[0].data+'\n') #获取文本值
str_s = (((file_io.getvalue().replace(' \n','\r\n')).replace(' ',',')).replace('T',' ')).replace('NIL','')
xm.close()
file_io.close()
return (str_s,vs_cnt)Ergebnis der Programmausführung:
*********** ** *****************************************
Programmabarbeitung startet .
Das Eingabeverzeichnis ist: /tmcdata/mro2csv/input31/.
Das Ausgabeverzeichnis ist: /tmcdata/mro2csv/output31/.
Die Anzahl der .gz-Dateien im Eingabeverzeichnis beträgt: 12, 12 davon werden dieses Mal verarbeitet.
************************************************ **** ******
Dateianzahl: 1/12.
Eingelesen: /tmcdata/mro2csv/input31/TD-LTE_MRO_NSN_OMC_234598_20160224060000.xml.gz.
Analyse:
Dateianzahl: 2/12.
Einlesen:/tmcdata/mro2csv/input31/TD-LTE_MRO_NSN_OMC_233798_20160224060000.xml.gz.
Analyse:
Dateianzahl: 3/12.
Einlesen: /tmcdata/mro2csv/input31/TD-LTE_MRO_NSN_OMC_123798_20160224060000.xml.gz.
Parsing:
…………………………………………
Dateianzahl: 12/12.
Einlesen: /tmcdata/mro2csv/input31/TD- LTE_MRO_NSN_OMC_235598_20160224060000. xml.gz.
Parsing:
VS-Zeilenanzahl: 177849, Laufzeit: 107,077867, verarbeitete Zeilen pro Sekunde: 1660.
Geschrieben an: /tmcdata/mro2csv/output31/mro_0001.csv.
************************************************ **** ******
Programmbearbeitung endet.
Da das DOM-Parsen das Einlesen der gesamten Datei in den Speicher und das Erstellen einer Baumstruktur erfordert, ist der Speicher- und Zeitverbrauch relativ hoch. Der Vorteil besteht jedoch darin, dass die Logik einfach ist und kein Rückruf definiert werden muss Funktion, was die Implementierung erleichtert.
2. SAX-Analyse
Funktionsdefinitionscode:
def sax_parser(gz):
import os,gzip,cStringIO
from xml.parsers.expat import ParserCreate
#变量声明
d_eNB = {}
d_obj = {}
s = ''
global flag
flag = False
file_io = cStringIO.StringIO()
#Sax解析类
class DefaultSaxHandler(object):
#处理开始标签
def start_element(self, name, attrs):
global d_eNB
global d_obj
global vs_cnt
if name == 'eNB':
d_eNB = attrs
elif name == 'object':
d_obj = attrs
elif name == 'v':
file_io.write(d_eNB['id']+' '+ d_obj['id']+' '+d_obj['MmeUeS1apId']+' '+d_obj['MmeGroupId']+' '+d_obj['MmeCode']+' '+d_obj['TimeStamp']+' ')
vs_cnt += 1
else:
pass
#处理中间文本
def char_data(self, text):
global d_eNB
global d_obj
global flag
if text[0:1].isnumeric():
file_io.write(text)
elif text[0:17] == 'MR.LteScPlrULQci1':
flag = True
#print(text,flag)
else:
pass
#处理结束标签
def end_element(self, name):
global d_eNB
global d_obj
if name == 'v':
file_io.write('\n')
else:
pass
#Sax解析调用
handler = DefaultSaxHandler()
parser = ParserCreate()
parser.StartElementHandler = handler.start_element
parser.EndElementHandler = handler.end_element
parser.CharacterDataHandler = handler.char_data
vs_cnt = 0
str_s = ''
xm = gzip.open(gz,'rb')
print("已读入:%s.\n解析中:" % (os.path.abspath(gz)))
for line in xm.readlines():
parser.Parse(line) #解析xml文件内容
if flag:
break
str_s = file_io.getvalue().replace(' \n','\r\n').replace(' ',',').replace('T',' ').replace('NIL','') #写入解析后内容
xm.close()
file_io.close()
return (str_s,vs_cnt)Ergebnis der Programmausführung:
*********** ***************************************
Programmabarbeitung startet.
Das Eingabeverzeichnis ist: /tmcdata/mro2csv/input31/.
Das Ausgabeverzeichnis ist: /tmcdata/mro2csv/output31/.
Die Anzahl der .gz-Dateien im Eingabeverzeichnis beträgt: 12, 12 davon werden dieses Mal verarbeitet.
************************************************ **** ******
Dateianzahl: 1/12.
Eingelesen: /tmcdata/mro2csv/input31/TD-LTE_MRO_NSN_OMC_234598_20160224060000.xml.gz.
Analyse:
Dateianzahl: 2/12.
Einlesen:/tmcdata/mro2csv/input31/TD-LTE_MRO_NSN_OMC_233798_20160224060000.xml.gz.
Analyse:
Dateianzahl: 3/12.
Einlesen: /tmcdata/mro2csv/input31/TD-LTE_MRO_NSN_OMC_123798_20160224060000.xml.gz.
Parsing:
........................................
Dateianzahl: 12/12.
Einlesen: /tmcdata/mro2csv/input31/TD-LTE_MRO_NSN_OMC_235598_20160224060000.xml.gz.
Parsing:
VS-Zeilenanzahl: 177849, läuft Zeit : 14,386779, pro Sekunde verarbeitete Zeilen: 12361.
Geschrieben an: /tmcdata/mro2csv/output31/mro_0001.csv.
************************************************ **** ******
Programmbearbeitung endet.
SAX-Parsing hat eine deutlich kürzere Laufzeit als DOM-Parsing. Da SAX zeilenweises Parsen verwendet, benötigt es weniger Speicher für die Verarbeitung größerer Dateien. Daher ist SAX-Parsing eine derzeit weit verbreitete Parsing-Methode gebraucht. Der Nachteil besteht darin, dass Sie die Rückruffunktion selbst implementieren müssen und die Logik relativ komplex ist.
3. ET-Analyse
Funktionsdefinitionscode:
def ET_parser(gz):
import os,gzip,cStringIO
import xml.etree.cElementTree as ET
vs_cnt = 0
str_s = ''
file_io = cStringIO.StringIO()
xm = gzip.open(gz,'rb')
print("已读入:%s.\n解析中:" % (os.path.abspath(gz)))
tree = ET.ElementTree(file=xm)
root = tree.getroot()
for elem in root[1][0].findall('object'):
for v in elem.findall('v'):
file_io.write(root[1].attrib['id']+' '+elem.attrib['TimeStamp']+' '+elem.attrib['MmeCode']+' '+\
elem.attrib['id']+' '+ elem.attrib['MmeUeS1apId']+' '+ elem.attrib['MmeGroupId']+' '+ v.text+'\n')
vs_cnt += 1
str_s = file_io.getvalue().replace(' \n','\r\n').replace(' ',',').replace('T',' ').replace('NIL','') #写入解析后内容
xm.close()
file_io.close()
return (str_s,vs_cnt)Programmlaufergebnis:
*********** ** *****************************************
Programmabarbeitung startet .
Das Eingabeverzeichnis ist: /tmcdata/mro2csv/input31/.
Das Ausgabeverzeichnis ist: /tmcdata/mro2csv/output31/.
Die Anzahl der .gz-Dateien im Eingabeverzeichnis beträgt: 12, 12 davon werden dieses Mal verarbeitet.
************************************************ **** ******
Dateianzahl: 1/12.
Eingelesen: /tmcdata/mro2csv/input31/TD-LTE_MRO_NSN_OMC_234598_20160224060000.xml.gz.
Analyse:
Dateianzahl: 2/12.
Einlesen:/tmcdata/mro2csv/input31/TD-LTE_MRO_NSN_OMC_233798_20160224060000.xml.gz.
Analyse:
Dateianzahl: 3/12.
Einlesen: /tmcdata/mro2csv/input31/TD-LTE_MRO_NSN_OMC_123798_20160224060000.xml.gz.
Analyse:
...........................................
文件计数:12/12.
已读入:/tmcdata/mro2csv/input31/TD-LTE_MRO_NSN_OMC_235598_20160224060000.xml.gz.
解析中:
VS行计数:177849,运行时间:4.308103,每秒处理行数:41282。
已写入:/tmcdata/mro2csv/output31/mro_0001.csv。
**************************************************
程序处理结束。
相较于SAX解析,ET解析时间更短,并且函数实现也比较简单,所以ET具有类似DOM的简单逻辑实现且匹敌SAX的解析效率,因此ET是目前XML解析的首选。
4、ET_iter解析
函数定义代码:
def ET_parser_iter(gz):
import os,gzip,cStringIO
import xml.etree.cElementTree as ET
vs_cnt = 0
str_s = ''
file_io = cStringIO.StringIO()
xm = gzip.open(gz,'rb')
print("已读入:%s.\n解析中:" % (os.path.abspath(gz)))
d_eNB = {}
d_obj = {}
i = 0
for event,elem in ET.iterparse(xm,events=('start','end')):
if i >= 2:
break
elif event == 'start':
if elem.tag == 'eNB':
d_eNB = elem.attrib
elif elem.tag == 'object':
d_obj = elem.attrib
elif event == 'end' and elem.tag == 'smr':
i += 1
elif event == 'end' and elem.tag == 'v':
file_io.write(d_eNB['id']+' '+d_obj['TimeStamp']+' '+d_obj['MmeCode']+' '+d_obj['id']+' '+\
d_obj['MmeUeS1apId']+' '+ d_obj['MmeGroupId']+' '+str(elem.text)+'\n')
vs_cnt += 1
elem.clear()
str_s = file_io.getvalue().replace(' \n','\r\n').replace(' ',',').replace('T',' ').replace('NIL','') #写入解析后内容
xm.close()
file_io.close()
return (str_s,vs_cnt)程序运行结果:
**************************************************
程序处理启动。
输入目录为:/tmcdata/mro2csv/input31/。
输出目录为:/tmcdata/mro2csv/output31/。
输入目录下.gz文件个数为:12,本次处理其中的12个。
**************************************************
文件计数:1/12.
已读入:/tmcdata/mro2csv/input31/TD-LTE_MRO_NSN_OMC_234598_20160224060000.xml.gz.
解析中:
文件计数:2/12.
已读入:/tmcdata/mro2csv/input31/TD-LTE_MRO_NSN_OMC_233798_20160224060000.xml.gz.
解析中:
文件计数:3/12.
已读入:/tmcdata/mro2csv/input31/TD-LTE_MRO_NSN_OMC_123798_20160224060000.xml.gz.
解析中:
...................................................
文件计数:12/12.
已读入:/tmcdata/mro2csv/input31/TD-LTE_MRO_NSN_OMC_235598_20160224060000.xml.gz.
解析中:
VS行计数:177849,运行时间:3.043805,每秒处理行数:58429。
已写入:/tmcdata/mro2csv/output31/mro_0001.csv。
**************************************************
程序处理结束。
在引入了ET_iter解析后,解析效率比ET提升了近50%,而相较于DOM解析更是提升了35倍,在解析效率提升的同时,由于其采用了iterparse这个循序解析的工具,其内存占用也是比较小的。
Das obige ist der detaillierte Inhalt vonAnalysieren Sie verschiedene Möglichkeiten, wie Python XML analysiert. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!