
Heim >Java >javaLernprogramm >Detaillierte Erläuterung der Verwendung des LRU-Algorithmus in Java
Detaillierte Erläuterung der Verwendung des LRU-Algorithmus in Java

- 黄舟Original
- 2017-09-15 10:35:221967Durchsuche
In diesem Artikel wird hauptsächlich das Konzept des LRU-Algorithmus vorgestellt und die spezifische Verwendung des LRU-Algorithmus anhand von Beispielen analysiert
Das Beispiele in diesem Artikel beschreiben die Java-Einführung und Verwendung des LRU-Algorithmus. Teilen Sie es als Referenz mit allen. Die Details lauten wie folgt:
Vorwort
Wenn Benutzer mit dem Internet verbundene Software verwenden, verwenden sie wird immer aus dem Internet gestartet. Wenn dieselben Daten innerhalb eines bestimmten Zeitraums mehrmals verwendet werden müssen, ist es für den Benutzer nicht möglich, jedes Mal online zu gehen, um eine Anfrage zu stellen, was eine Verschwendung von Zeit und Netzwerk ist
Zu diesem Zeitpunkt können Sie die vom Benutzer angeforderten Daten speichern, es werden jedoch nicht alle Daten gespeichert, was zu einer Speicherverschwendung führt. Die Idee des LRU-Algorithmus kann angewendet werden.
2. Einführung in LRU
LRU ist der Least-Recent-Used-Algorithmus, der Daten verarbeiten kann, die schon lange nicht mehr verwendet wurden . löschen.
LRU spiegelt sich auch gut in den Emotionen mancher Menschen wider. Wenn Sie mit einer Gruppe von Freunden in Kontakt stehen, ist die Beziehung zu den Menschen, mit denen Sie häufig kommunizieren, sehr gut. Wenn Sie sie längere Zeit nicht kontaktieren und wahrscheinlich auch nicht wieder kontaktieren, haben Sie diese verloren Freund.
3. Der folgende Code zeigt den LRU-Algorithmus:
Der einfachste Weg ist die Verwendung von LinkHashMap, da es selbst über eine Methode verfügt um zusätzliche alte Daten innerhalb des festgelegten Cache-Bereichs zu entfernen
public class LRUByHashMap<K, V> {
/*
* 通过LinkHashMap简单实现LRU算法
*/
/**
* 缓存大小
*/
private int cacheSize;
/**
* 当前缓存数目
*/
private int currentSize;
private LinkedHashMap<K, V> maps;
public LRUByHashMap(int cacheSize1) {
this.cacheSize = cacheSize1;
maps = new LinkedHashMap<K, V>() {
/**
*
*/
private static final long serialVersionUID = 1;
// 这里移除旧的缓存数据
@Override
protected boolean removeEldestEntry(java.util.Map.Entry<K, V> eldest) {
// 当超过缓存数量的时候就将旧的数据移除
return getCurrentSize() > LRUByHashMap.this.cacheSize;
}
};
}
public synchronized int getCurrentSize() {
return maps.size();
}
public synchronized void put(K k, V v) {
if (k == null) {
throw new Error("存入的键值不能为空");
}
maps.put(k, v);
}
public synchronized void remove(K k) {
if (k == null) {
throw new Error("移除的键值不能为空");
}
maps.remove(k);
}
public synchronized void clear() {
maps = null;
}
// 获取集合
public synchronized Collection<V> getCollection() {
if (maps != null) {
return maps.values();
} else {
return null;
}
}
public static void main(String[] args) {
// 测试
LRUByHashMap<Integer, String> maps = new LRUByHashMap<Integer, String>(
3);
maps.put(1, "1");
maps.put(2, "2");
maps.put(3, "3");
maps.put(4, "4");
maps.put(5, "5");
maps.put(6, "6");
Collection<String> col = maps.getCollection();
System.out.println("存入缓存中的数据是--->>" + col.toString());
}
}Der Effekt nach dem Ausführen:
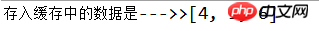
Der Code offensichtlich 6 Einträge eingegeben, aber am Ende wurden nur drei angezeigt. Die drei dazwischen waren alt und wurden ausgeklickt
Die zweite Methode ist die Verwendung einer doppelt verknüpften Liste + HashTable
Die Funktion von Die doppelt verknüpfte Liste dient zum Aufzeichnen des Standorts, während die HashTable als Container zum Speichern von Daten verwendet wird.
Warum HashTable anstelle von HashMap verwenden?
1. Die Schlüssel und Werte von HashTable dürfen nicht null sein;
2. Die oben mit LinkHashMap implementierte LRU ist nützlich für die Synchronisierung, sodass Threads synchron verarbeitet werden können, sodass keine Multithreads erforderlich sind Verursacht Probleme bei der Verarbeitung einheitlicher Daten.
HashTable verfügt über einen eigenen Synchronisierungsmechanismus, sodass Multithreads HashTable korrekt verarbeiten können.
Alle Caches sind mit positionellen doppelt verknüpften Listen verbunden. Wenn eine Position erreicht wird, wird die Position an die Position des Kopfes der verknüpften Liste angepasst, indem die Ausrichtung des neu hinzugefügten Caches angepasst wird wird direkt am Kopf der verknüpften Liste hinzugefügt. Auf diese Weise werden nach mehreren Cache-Vorgängen
, die kürzlich getroffen wurden, an den Anfang der verknüpften Liste verschoben, während diejenigen, die nicht getroffen wurden, an das Ende der verknüpften Liste verschoben werden der verknüpften Liste stellt den zuletzt verwendeten Cache dar. Wenn Inhalte ersetzt werden müssen, ist die letzte Position der verknüpften Liste die Position mit den wenigsten Treffern. Wir müssen nur
den letzten Teil der verknüpften Liste
public class LRUCache {
private int cacheSize;
private Hashtable<Object, Entry> nodes;//缓存容器
private int currentSize;
private Entry first;//链表头
private Entry last;//链表尾
public LRUCache(int i) {
currentSize = 0;
cacheSize = i;
nodes = new Hashtable<Object, Entry>(i);//缓存容器
}
/**
* 获取缓存中对象,并把它放在最前面
*/
public Entry get(Object key) {
Entry node = nodes.get(key);
if (node != null) {
moveToHead(node);
return node;
} else {
return null;
}
}
/**
* 添加 entry到hashtable, 并把entry
*/
public void put(Object key, Object value) {
//先查看hashtable是否存在该entry, 如果存在,则只更新其value
Entry node = nodes.get(key);
if (node == null) {
//缓存容器是否已经超过大小.
if (currentSize >= cacheSize) {
nodes.remove(last.key);
removeLast();
} else {
currentSize++;
}
node = new Entry();
}
node.value = value;
//将最新使用的节点放到链表头,表示最新使用的.
node.key = key
moveToHead(node);
nodes.put(key, node);
}
/**
* 将entry删除, 注意:删除操作只有在cache满了才会被执行
*/
public void remove(Object key) {
Entry node = nodes.get(key);
//在链表中删除
if (node != null) {
if (node.prev != null) {
node.prev.next = node.next;
}
if (node.next != null) {
node.next.prev = node.prev;
}
if (last == node)
last = node.prev;
if (first == node)
first = node.next;
}
//在hashtable中删除
nodes.remove(key);
}
/**
* 删除链表尾部节点,即使用最后 使用的entry
*/
private void removeLast() {
//链表尾不为空,则将链表尾指向null. 删除连表尾(删除最少使用的缓存对象)
if (last != null) {
if (last.prev != null)
last.prev.next = null;
else
first = null;
last = last.prev;
}
}
/**
* 移动到链表头,表示这个节点是最新使用过的
*/
private void moveToHead(Entry node) {
if (node == first)
return;
if (node.prev != null)
node.prev.next = node.next;
if (node.next != null)
node.next.prev = node.prev;
if (last == node)
last = node.prev;
if (first != null) {
node.next = first;
first.prev = node;
}
first = node;
node.prev = null;
if (last == null)
last = first;
}
/*
* 清空缓存
*/
public void clear() {
first = null;
last = null;
currentSize = 0;
}
}
class Entry {
Entry prev;//前一节点
Entry next;//后一节点
Object value;//值
Object key;//键
}Das obige ist der detaillierte Inhalt vonDetaillierte Erläuterung der Verwendung des LRU-Algorithmus in Java. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!