
Heim >Backend-Entwicklung >Python-Tutorial >Einführung in die Verwendung von Numpy und Pandas in Python
Einführung in die Verwendung von Numpy und Pandas in Python
- 巴扎黑Original
- 2017-09-13 10:04:382886Durchsuche
Vor kurzem muss ich eine Reihe von Daten von Jahr zu Jahr vergleichen und für die Berechnung Numpy und Pandas verwenden. Der folgende Artikel führt Sie hauptsächlich in die relevanten Informationen zur Verwendung von Numpy und Pandas in Python ein Lern-Tutorial. Der Artikel stellt es anhand eines Beispielcodes vor. Sehr detailliert, Freunde in Not können sich darauf beziehen.
Vorwort
Dieser Artikel stellt hauptsächlich relevante Informationen über die Verwendung von Numpy und Pandas in Python vor und gibt sie als Referenz und Studium weiter. Unten gibt es nicht viel zu sagen, werfen wir einen Blick auf die ausführliche Einführung.
Was sind sie?
NumPy ist eine Erweiterungsbibliothek für die Python-Sprache. Es unterstützt erweiterte großdimensionale Array- und Matrixoperationen und bietet außerdem eine große Anzahl mathematischer Funktionsbibliotheken für Array-Operationen.
Pandas ist ein auf NumPy basierendes Tool, das zur Lösung von Datenanalyseaufgaben entwickelt wurde. Pandas umfasst eine Reihe von Bibliotheken und einige Standarddatenmodelle, um die erforderlichen Tools für die effiziente Bearbeitung großer Datenmengen bereitzustellen. Pandas stellt eine Vielzahl an Funktionen und Methoden zur Verfügung, mit denen wir Daten schnell und einfach verarbeiten können.
List, Numpy und Pandas
Numpy und List
Gleichheit:
kann auf alle Elemente mithilfe von Indizes zugreifen, z. B. a[0]
-
kann auf alle Elemente durch Slicing zugegriffen werden, z. B. a[1:3]
kann mit einer for-Schleife durchlaufen werden
Der Unterschied:
Jedes Element in Numpy Die Typen muss gleich sein; mehrere Typelemente können in der Liste gemischt werden
Numpy ist bequemer zu verwenden und kapselt viele Funktionen wie Mittelwert, Standard, Summe, Min., Max. usw.
Numpy kann ein mehrdimensionales Array sein
Numpy ist in C implementiert und arbeitet schneller
Pandas ist dasselbe wie Numpy
:
ist dasselbe wie der Zugriff auf Elemente. Sie können Subskripte oder Slices verwenden, um auf
- Sie können eine For-Schleife zum Durchlaufen verwenden
- Es gibt viele praktische Funktionen wie Mittelwert, Standard, Summe, Min., Max. usw.
- Vektoroperationen können ausgeführt werden
- in C implementiert, was schneller ist
Numpy verwenden
1. Grundfunktionen
import numpy as np #创建Numpy p1 = np.array([1, 2, 3]) print p1 print p1.dtype
[1 2 3] int64
#求平均值 print p1.mean()
2.0
#求标准差 print p1.std()
0.816496580928
#求和、求最大值、求最小值 print p1.sum() print p1.max() print p1.min()
6 3 1
#求最大值所在位置 print p1.argmax()
2
2. Vektoroperationen
p1 = np.array([1, 2, 3]) p2 = np.array([2, 5, 7])
#向量相加,各个元素相加 print p1 + p2
[ 3 7 10]
#向量乘以1个常数 print p1 * 2
[2 4 6]
#向量相减 print p1 - p2
[-1 -3 -4]
#向量相乘,各个元素之间做运算 print p1 * p2
[ 2 10 21]
#向量与一个常数比较 print p1 > 2
[False False True]
3. Index-Array
Schauen Sie sich zunächst das Bild unten an, um zu verstehen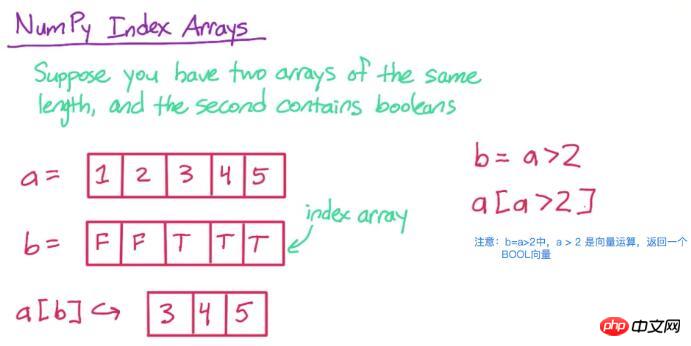
a = np.array([1, 2, 3, 4, 5]) print a
[1 2 3 4 5]
In a[b] , nur die entsprechenden in a werden beibehalten Elemente, deren b-Position wahr ist
b = a > 2 print b
4. In-Place und Non-In-Place
[False False True True True]Schauen wir uns zunächst a an Reihe von Operationen:
print a[b]
[3 4 5]
Wie Sie den obigen Ergebnissen entnehmen können, ändert Out, += das ursprüngliche Array, + jedoch nicht. Dies liegt daran:
a = np.array([1, 2, 3, 4]) b = a a += np.array([1, 1, 1, 1]) print b
+=: Es wird direkt berechnet und erstellt kein neues Array, wodurch Elemente im ursprünglichen Array geändert werden
[2 3 4 5]
+: Es handelt sich um eine nicht-in-place-Berechnung, es wird ein neues Array erstellt und die Elemente im ursprünglichen Array werden nicht verändert
a = np.array([1, 2, 3, 4]) b = a a = a + np.array([1, 1, 1, 1]) print b
[1 2 3 4]
Aus dem Obigen ist ersichtlich, dass sich das Ändern der Elemente im Slice in List nicht auf das ursprüngliche Array auswirkt, während Numpy die Elemente im Slice ändert und sich auch das ursprüngliche Array ändert. Dies liegt daran, dass die Slice-Programmierung von Numpy kein neues Array erstellt und durch das Ändern des entsprechenden Slice auch die ursprünglichen Array-Daten geändert werden. Dieser Mechanismus kann Numpy schneller machen als native Array-Operationen, Sie müssen jedoch beim Programmieren darauf achten.
l1 = [1, 2, 3, 5] l2 = l1[0:2] l2[0] = 5 print l2 print l1
6. Zweidimensionale Array-Operationen
p1 = np.array([[1, 2, 3], [7, 8, 9], [2, 4, 5]]) #获取其中一维数组 print p1[0]
[1 2 3]
#获取其中一个元素,注意它可以是p1[0, 1],也可以p1[0][1] print p1[0, 1] print p1[0][1]
2 2
#求和是求所有元素的和 print p1.sum()
41 [10 14 17]
但,当设置axis参数时,当设置为0时,是计算每一列的结果,然后返回一个一维数组;若是设置为1时,则是计算每一行的结果,然后返回一维数组。对于二维数组,Numpy中很多函数都可以设置axis参数。
#获取每一列的结果 print p1.sum(axis=0)
[10 14 17]
#获取每一行的结果 print p1.sum(axis=1)
[ 6 24 11]
#mean函数也可以设置axis print p1.mean(axis=0)
[ 3.33333333 4.66666667 5.66666667]
Pandas使用
Pandas有两种结构,分别是Series和DataFrame。其中Series拥有Numpy的所有功能,可以认为是简单的一维数组;而DataFrame是将多个Series按列合并而成的二维数据结构,每一列单独取出来是一个Series。
咱们主要梳理下Numpy没有的功能:
1、简单基本使用
import pandas as pd pd1 = pd.Series([1, 2, 3]) print pd1
0 1 1 2 2 3 dtype: int64
#也可以求和和标准偏差 print pd1.sum() print pd1.std()
6 1.0
2、索引
(1)Series中的索引
p1 = pd.Series( [1, 2, 3], index = ['a', 'b', 'c'] ) print p1
a 1 b 2 c 3 dtype: int64
print p1['a']
(2)DataFrame数组
p1 = pd.DataFrame({
'name': ['Jack', 'Lucy', 'Coke'],
'age': [18, 19, 21]
})
print p1age name 0 18 Jack 1 19 Lucy 2 21 Coke
#获取name一列 print p1['name']
0 Jack 1 Lucy 2 Coke Name: name, dtype: object
#获取姓名的第一个 print p1['name'][0]
Jack
#使用p1[0]不能获取第一行,但是可以使用iloc print p1.iloc[0]
age 18 name Jack Name: 0, dtype: object
总结:
获取一列使用p1[‘name']这种索引
获取一行使用p1.iloc[0]
3、apply使用
apply可以操作Pandas里面的元素,当库里面没用对应的方法时,可以通过apply来进行封装
def func(value): return value * 3 pd1 = pd.Series([1, 2, 5])
print pd1.apply(func)
0 3 1 6 2 15 dtype: int64
同样可以在DataFrame上使用:
pd2 = pd.DataFrame({
'name': ['Jack', 'Lucy', 'Coke'],
'age': [18, 19, 21]
})
print pd2.apply(func)age name 0 54 JackJackJack 1 57 LucyLucyLucy 2 63 CokeCokeCoke
4、axis参数
Pandas设置axis时,与Numpy有点区别:
当设置axis为'columns'时,是计算每一行的值
当设置axis为'index'时,是计算每一列的值
pd2 = pd.DataFrame({
'weight': [120, 130, 150],
'age': [18, 19, 21]
})0 138 1 149 2 171 dtype: int64
#计算每一行的值 print pd2.sum(axis='columns')
0 138 1 149 2 171 dtype: int64
#计算每一列的值 print pd2.sum(axis='index')
age 58 weight 400 dtype: int64
5、分组
pd2 = pd.DataFrame({
'name': ['Jack', 'Lucy', 'Coke', 'Pol', 'Tude'],
'age': [18, 19, 21, 21, 19]
})
#以年龄分组
print pd2.groupby('age').groups{18: Int64Index([0], dtype='int64'), 19: Int64Index([1, 4], dtype='int64'), 21: Int64Index([2, 3], dtype='int64')}6、向量运算
需要注意的是,索引数组相加时,对应的索引相加
pd1 = pd.Series( [1, 2, 3], index = ['a', 'b', 'c'] ) pd2 = pd.Series( [1, 2, 3], index = ['a', 'c', 'd'] )
print pd1 + pd2
a 2.0 b NaN c 5.0 d NaN dtype: float64
出现了NAN值,如果我们期望NAN不出现,如何处理?使用add函数,并设置fill_value参数
print pd1.add(pd2, fill_value=0)
a 2.0 b 2.0 c 5.0 d 3.0 dtype: float64
同样,它可以应用在Pandas的dataFrame中,只是需要注意列与行都要对应起来。
总结
这一周学习了优达学城上分析基础的课程,使用的是Numpy与Pandas。对于Numpy,以前在Tensorflow中用过,但是很不明白,这次学习之后,才知道那么简单,算是有一定的收获。
Das obige ist der detaillierte Inhalt vonEinführung in die Verwendung von Numpy und Pandas in Python. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!