
Heim >Betrieb und Instandhaltung >Betrieb und Wartung von Linux >Einführung in Sitzungsverarbeitungsmethoden in einer Linux-Cluster-/verteilten Umgebung
Einführung in Sitzungsverarbeitungsmethoden in einer Linux-Cluster-/verteilten Umgebung
- 巴扎黑Original
- 2017-09-08 09:55:151532Durchsuche
Dieser Artikel führt Sie hauptsächlich in die fünf Strategien für die Sitzungsverarbeitung in einer Linux-Cluster-/verteilten Umgebung ein. Der Artikel stellt sie ausführlich anhand von Beispielcodes und Bildern vor. Er bietet einen gewissen Referenzlernwert für alle, die ihn benötigen Folgen Sie bitte dem Herausgeber, um gemeinsam zu lernen.
Vorwort
Nachdem wir eine Clusterumgebung erstellt haben, müssen wir im Allgemeinen eines der Probleme berücksichtigen, wie mit den vom Benutzer generierten Sitzungen umgegangen wird Zugang. Wenn keine Verarbeitung erfolgt, melden sich Benutzer häufig an. Beispielsweise gibt es zwei Server A und B im Cluster. Wenn der Benutzer die Website zum ersten Mal besucht, leitet Nginx die Benutzeranfrage über seinen Lastausgleich weiter Dies wird der Fall sein. Zu diesem Zeitpunkt erstellt Server A eine Sitzung für den Benutzer. Wenn der Benutzer zum zweiten Mal eine Anfrage sendet, verteilt Nginx die Last der Anfrage an Server B. Zu diesem Zeitpunkt verfügt Server B über keine Sitzung, sodass der Benutzer zur Anmeldeseite weitergeleitet wird. Dies wird die Benutzererfahrung erheblich beeinträchtigen und zum Verlust von Benutzern führen. Diese Situation sollte im Projekt niemals auftreten.
Wir sollten die generierte Sitzung verarbeiten, um die Benutzererfahrung durch Sticky Session, Session Copy oder Session Sharing sicherzustellen.
Im Folgenden erläutere ich 5 Sitzungsverarbeitungsstrategien und analysiere ihre Vor- und Nachteile. Es gibt nicht viel zu sagen, werfen wir einen Blick auf die ausführliche Einführung.
Der erste Typ: Sticky Session
Prinzip: Eine Sticky Session bezieht sich auf die Sperrung des Benutzers an einen bestimmten Server B. im oben genannten Beispiel: Wenn der Benutzer zum ersten Mal eine Anfrage stellt, leitet der Load Balancer die Anfrage des Benutzers an Server A weiter. Wenn der Load Balancer eine Sticky Session einrichtet, wird jede nachfolgende Anfrage des Benutzers an Server A weitergeleitet . Dies entspricht dem Zusammenhalten von Benutzer und Server A. Dies ist der Sticky-Session-Mechanismus.
Vorteile: Einfach, keine Bearbeitung der Sitzung erforderlich.
Nachteile: Mangelnde Fehlertoleranz Wenn der aktuell aufgerufene Server ausfällt und der Benutzer auf den zweiten Server übertragen wird, sind seine Sitzungsinformationen ungültig.
Anwendbare Szenarien: Ein Ausfall hat nur geringe Auswirkungen auf Kunden; ein Serverausfall ist ein Ereignis mit geringer Wahrscheinlichkeit.
Implementierungsmethode: Am Beispiel von Nginx kann eine Sticky-Sitzung durch die Konfiguration des ip_hash-Attributs im Upstream-Modul realisiert werden.
upstream mycluster{
#这里添加的是上面启动好的两台Tomcat服务器
ip_hash;#粘性Session
server 192.168.22.229:8080 weight=1;
server 192.168.22.230:8080 weight=1;
}Zweiter Typ: Serversitzungsreplikation
Prinzip: Wenn sich die Sitzung auf einem Server ändert (Hinzufügen, Löschen oder Ändern), serialisiert der Knoten den gesamten Inhalt der Sitzung und sendet ihn dann an alle anderen Knoten, unabhängig davon, ob andere Server die Sitzung benötigen oder nicht, um die Sitzungssynchronisierung sicherzustellen.
Vorteile: Fehlertolerant, Sitzungen zwischen Servern können in Echtzeit reagieren.
Nachteile: übt einen gewissen Druck auf die Netzwerklast aus. Wenn die Anzahl der Sitzungen groß ist, kann es zu einer Netzwerküberlastung und einer Verlangsamung der Serverleistung kommen.
Implementierungsmethode:
① Stellen Sie Tomcat, server.xml ein, um die Tomcat-Clusterfunktion zu aktivieren
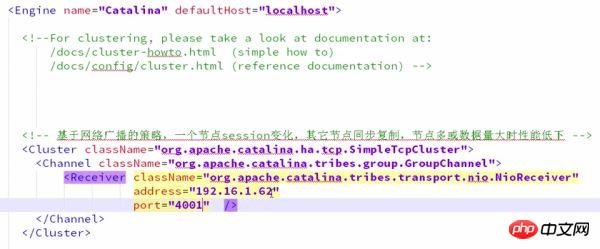
Adresse: Füllen Sie einfach die lokale IP-Adresse aus und legen Sie die Portnummer fest, um Portkonflikte zu vermeiden.
② Informationen zur Anwendung hinzufügen: Benachrichtigen, dass sich die Anwendung derzeit in einer Clusterumgebung befindet und verteilte unterstützt
Optionen in web.xml hinzufügen <distributable></distributable>
Dritter Typ: Sitzungsfreigabemechanismus
Verwenden Sie verteilte Caching-Lösungen wie Memcached und Redis, aber Memcached oder Redis müssen ein Cluster sein.
Es gibt zwei Mechanismen für die Verwendung der Sitzungsfreigabe. Die beiden Situationen sind wie folgt:
① Sticky-Sitzungsverarbeitungsmethode
Prinzip: Unterschiedlicher Tomcat Zugriff auf verschiedene Master-Memcached. Informationen zwischen mehreren Memcached werden synchronisiert, was Master-Slave-Backup und hohe Verfügbarkeit ermöglicht. Wenn ein Benutzer darauf zugreift, erstellt er zunächst eine Sitzung in Tomcat und kopiert die Sitzung dann in das entsprechende Memcah. Memcache spielt nur eine Backup-Rolle und alle Lese- und Schreibvorgänge erfolgen auf Tomcat. Wenn ein bestimmter Tomcat auflegt, ermittelt der Cluster den Zugriff des Benutzers auf den Standby-Tomcat und sucht dann anhand der im Cookie gespeicherten SessionId nach der Sitzung. Wenn er die Sitzung nicht finden kann, geht er zum entsprechenden Memcached, um die Sitzung zu finden . Nachdem es gefunden wurde, wird es in den Standby-Tomcat kopiert.
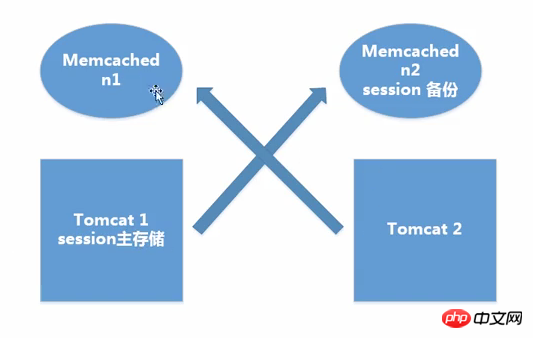
② Non-Sticky-Sitzungsverarbeitungsmethode
Prinzip: memcached führt eine Master-Slave-Replikation durch und schreibt in Sitzungen Beim Slave-Memcached-Dienst werden alle Lesevorgänge aus dem Haupt-Memcached gelesen, Tomcat selbst speichert keine Sitzung
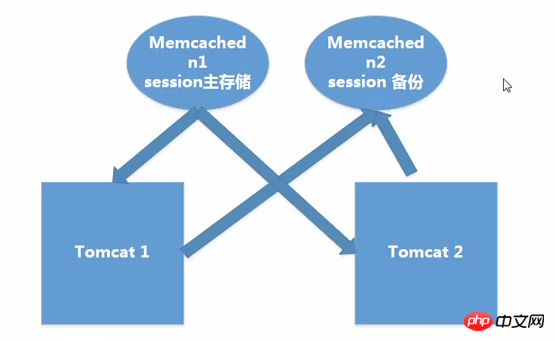
Vorteile: Fehlertolerant, Sitzung antwortet in Echtzeit.
Implementierungsmethode: Verwenden Sie das Open-Source-MSM-Plug-In, um die Sitzungsfreigabe zwischen Tomcats zu lösen: Memcached_Session_Manager (MSM)
a. 复制相关jar包到tomcat/lib 目录下
JAVA memcached客户端:spymemcached.jarmsm项目相关的jar包:1. 核心包,memcached-session-manager-{version}.jar2. Tomcat版本对应的jar包:memcached-session-manager-tc{tomcat-version}-{version}.jar序列化工具包:可选kryo,javolution,xstream等,不设置时使用jdk默认序列化。
b. 配置Context.xml ,加入处理Session的Manager
粘性模式配置:

非粘性配置:

第四种:session持久化到数据库
原理:就不用多说了吧,拿出一个数据库,专门用来存储session信息。保证session的持久化。
优点:服务器出现问题,session不会丢失
缺点:如果网站的访问量很大,把session存储到数据库中,会对数据库造成很大压力,还需要增加额外的开销维护数据库。
第五种terracotta实现session复制
原理:Terracotta的基本原理是对于集群间共享的数据,当在一个节点发生变化的时候,Terracotta只把变化的部分发送给Terracotta服务器,然后由服务器把它转发给真正需要这个数据的节点。可以看成是对第二种方案的优化。
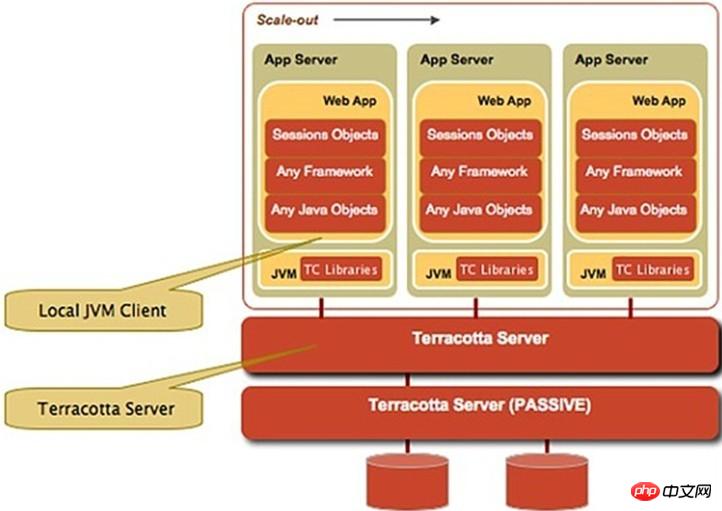
优点:这样对网络的压力就非常小,各个节点也不必浪费CPU时间和内存进行大量的序列化操作。把这种集群间数据共享的机制应用在session同步上,既避免了对数据库的依赖,又能达到负载均衡和灾难恢复的效果。
实现方式:篇幅原因,下篇再论。
小结
以上讲述的就是集群或分布式环境下,session的5种处理策略。其中就应用广泛性而言,第三种方式,也就是基于第三方缓存框架共享session,应用的最为广泛,无论是效率还是扩展性都很好。而Terracotta作为一个JVM级的开源群集框架,不仅提供HTTP Session复制,它还能做分布式缓存,POJO群集,跨越群集的JVM来实现分布式应用程序协调等,也值得学习一下。
Das obige ist der detaillierte Inhalt vonEinführung in Sitzungsverarbeitungsmethoden in einer Linux-Cluster-/verteilten Umgebung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Erfahren Sie, wie Sie den Nginx-Server unter Linux installieren
- Detaillierte Einführung in den wget-Befehl von Linux
- Ausführliche Erläuterung von Beispielen für die Verwendung von yum zur Installation von Nginx unter Linux
- Detaillierte Erläuterung der Worker-Verbindungsprobleme in Nginx
- Detaillierte Erläuterung des Installationsprozesses von Python3 unter Linux