
Heim >Java >javaLernprogramm >Zusammenfassung der Verwendung des Java Collection Frameworks
Zusammenfassung der Verwendung des Java Collection Frameworks

- 黄舟Original
- 2017-09-06 14:36:361484Durchsuche
Dieser Artikel stellt hauptsächlich eine Zusammenfassung des Sammlungsframeworks für die Java-Überprüfung vor. Jetzt werde ich es mit Ihnen teilen und eine Referenz geben. Folgen wir dem Herausgeber, um einen Blick darauf zu werfen
Wie das Sprichwort sagt: Überprüfen Sie das Alte und lernen Sie das Neue. Denken Sie über das Wissen nach, das Sie schon einmal gelernt haben, aber Sie werden es vergessen, wenn Sie es längere Zeit nicht anwenden. Deshalb halte ich es für sehr wichtig, das Wissen, das Sie zuvor gelernt haben, zu überprüfen. In diesem Dokument werden die Grundlagen des Sammlungsframeworks in Java erläutert.
Warum gibt es einen Sammelrahmen?
Normalerweise verwenden wir Arrays, um einige grundlegende Datentypen oder Referenzdatentypen zu speichern, aber die Länge des Arrays ist festgelegt. Wenn die hinzugefügten Elemente die Länge des Arrays überschreiten, muss das Array festgelegt werden Umstrukturiert wäre es zu mühsam, ein Programm zu schreiben, daher stellt Java für uns eine Sammlungsklasse bereit, die jedes Objekt speichern kann. Sie nimmt mit zunehmender Anzahl von Elementen zu und ab . reduzieren.
Arrays können Basisdatentypen oder Referenzdatentypen speichern, Werte speichern, Referenzdatentypen Adressen speichern und Sammlungen können nur Referenzdatentypen (d. h. Objekte) speichern, eigentlich Basisdaten Typen können auch in Sammlungen gespeichert werden, sie werden jedoch automatisch verpackt und beim Speichern in Objekte umgewandelt.
Ein Set zu haben bedeutet nicht, dass wir das Array aufgeben müssen. Wenn die Anzahl der zu speichernden Elemente festgelegt ist, können wir ein Array verwenden und festlegen, wann die Elemente gespeichert werden müssen nicht festgelegt, wir verwenden ein Set.
Arten von Sets
Sets werden in einspaltige Sets und zweispaltige Sets unterteilt. Die Stammschnittstelle einer einspaltigen Sammlung ist Collection, und die Stammschnittstelle einer zweispaltigen Kombination ist Map. Beide Sammlungen verfügen über Sammlungsklassen (HashMap und HashSet), die auf Hashing-Algorithmen basieren. Jetzt haben wir möglicherweise Fragen dazu, ob eine Doppelspaltenkombination vorhanden ist. Basiert die einspaltige Sammlung auf einer einspaltigen Sammlung, oder basiert die einspaltige Sammlung auf einer zweispaltigen Sammlung? Schauen wir uns den Quellcode zum Hinzufügen von Elementen zu den Sammlungen HashMap und HashSet an: >
Aus dem obigen Quellcode können wir erkennen, dass die Add-Methode nicht im Quellcode der Put-Methode der Doppelspaltensammlung vorkommt und die Add-Methode nicht im Quellcode enthalten ist Der Quellcode der einspaltigen Sammlung kann nur auf das Erscheinungsbild von put zurückzuführen sein. Wir können wissen, dass die einspaltige Sammlung auf der Grundlage der zweispaltigen Sammlung implementiert ist. Tatsächlich ist der Grund sehr einfach. Jedes Mal, wenn Sie ein Element zu einer einspaltigen Sammlung hinzufügen, müssen Sie nur einen Schlüssel hinzufügen. Der Schlüssel ist auch die eindeutige Kennung des Elements in der zweispaltigen Sammlung Wird jedes Mal, wenn Sie es hinzufügen, durch ein Objekt ersetzt und ausgeblendet. Das Ausblenden des Werts einer einspaltigen Kombination basiert auf einem zweispaltigen Satz. Wenn dies jedoch der Fall ist Wenn es sich um ein einspaltiges Set handelt, ist es sehr schwierig, es in ein zweispaltiges Set umzuwandeln. Es ist wie bei einem Zauberer, der Zaubertricks ausführt. Bevor Sie etwas ändern, müssen Sie das, was Sie ändern möchten, im Voraus vorbereiten und einfach verstecken. Aber wenn der Zauberer wirklich etwas von Grund auf erschafft, dann ist er wohl ein Gott und kann zaubern, was er will.
/*
*HashMap的put 方法
*/
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
/*
* HashSet 的add 方法
*/
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
// PRESENT是一个Object 对象
private static final Object PRESENT = new Object();Zuerst schauen wir uns das Vererbungsdiagramm der einspaltigen Kombination an. Die Root-Schnittstelle Die einspaltige Sammlung ist Collection, und die Implementierungsklassen von List sind ArrayList, LinkedList und Vector, und die Implementierungsklassen der Set-Schnittstelle sind HashSet und TreeSet.
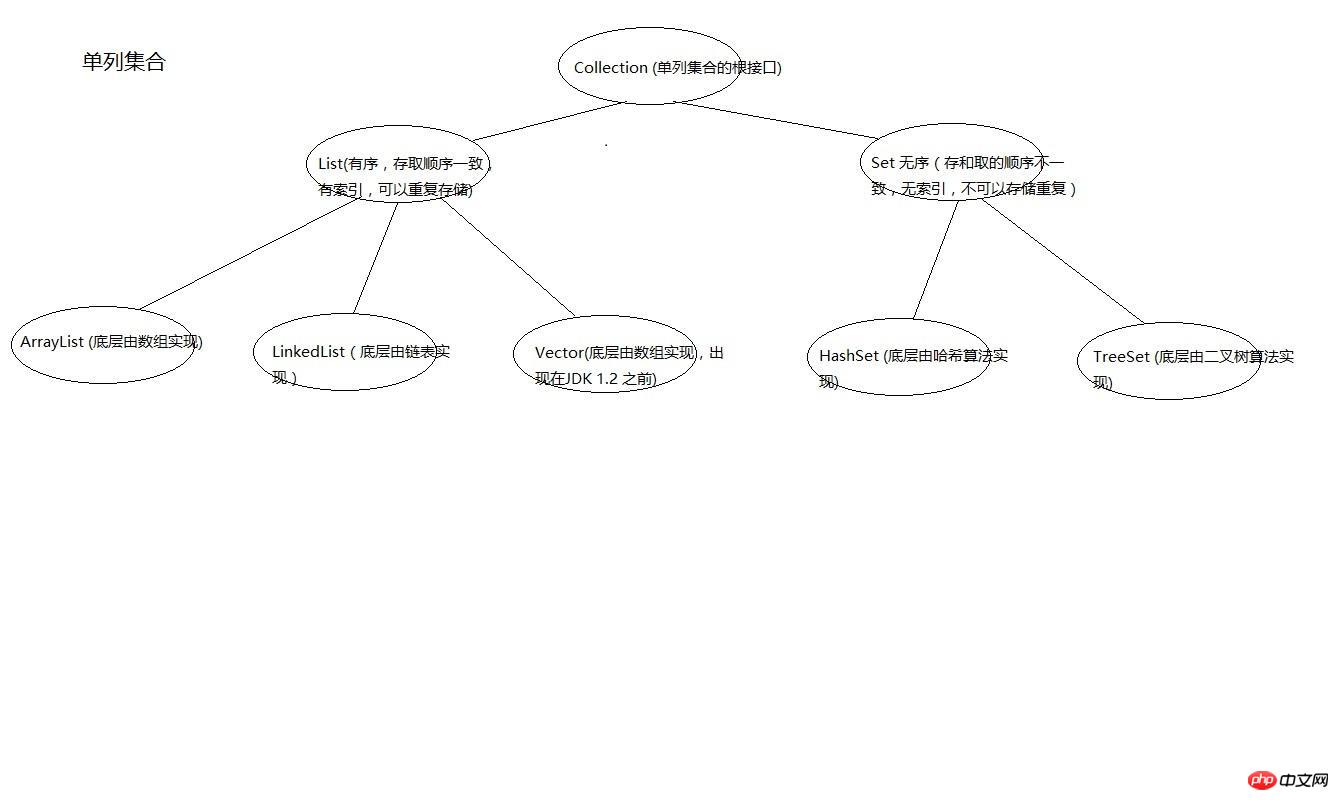 Zweitens werfen wir einen Blick auf die Funktionen jeder Sammlung
Zweitens werfen wir einen Blick auf die Funktionen jeder Sammlung
Überblick über die einzigartigen Funktionen der Listensammlung
* void add(int index,E element) //Element zur Sammlung hinzufügen
* E remove(int index) //Element an der Indexposition in der Sammlung löschen
* E set(int index,E element) Ersetzen Sie das Element an der Indexposition durch element
Spezielle Funktion von die Vektorklasse
* public void addElement(E obj) Element hinzufügen
* public E elementAt(int index) // Element abrufen
Einzigartige Funktionen der LinkedList-Klasse
* public void addFirst(E e) and addLast(E e) //Elemente zum Kopf hinzufügen der Sammlung oder fügen Sie Elemente am Ende der Sammlung hinzu
* public E getFirst() and getLast() // Holen Sie sich das Head-Element und holen Sie sich das Tail-Element
* public E get(int index); // Indexelement abrufen
Gemäß der obigen Funktion von LinkedList können wir das simulieren Stapel, um die Datenstruktur der Warteschlange zu erhalten. Der Stapel ist „First In, Last Out“, und die Warteschlange ist „First In, First Out“.
/**
* 模拟的栈对象
* @author 毛麒添
* 底层还是使用LinkedList实现
* 如果实现队列只需要将出栈变为 removeFirst
*/
public class Stack {
private LinkedList linklist=new LinkedList();
/**
* 进栈的方法
* @param obj
*/
public void in(Object obj){
linklist.addLast(obj);
}
/**
* 出栈
*/
public Object out(){
return linklist.removeLast();
}
/**
* 栈是否为空
* @return
*/
public boolean isEmpty(){
return linklist.isEmpty();
}
}
//集合的三种迭代(遍历集合)删除
ArrayList<String> list=new ArrayList();
list.add("a");
list.add("b");
list.add("c");
list.add("world");
//1,普通for循环删除元素
for(int i=0;i<list,size();i++){//删除元素b
if("b".equals(list.get(i))){
list.remove(i--);// i-- 当集合中有重复元素的时候保证要删除的重复元素被删除
}
}
//2.使用迭代器遍历集合
Iterator<String> it=list.iterator();
while(it.hasNext){
if("b".equals(it.next())){
it.remove();//这里必须使用迭代器的删除方法,而不能使用集合的删除方法,否则会出现并发修改异常(ConcurrentModificationException)
}
}
//使用增强for循环来进行删除
for (String str:list){
if("b".equals(str)){
list.remove("b");//增强for循环底层依赖的是迭代器,而这里删除使用的依旧是集合的删除方法,同理肯定是会出现并发修改异常(ConcurrentModificationException),所以增强for循环一直能用来遍历集合,不能对集合的元素进行删除。
}
}接下里我们看Set集合,我们知道Set 集合存储无序,无索引,不可以存储重复的对象;我们使用Set集合都是需要去掉重复元素的, 如果在存储的时候逐个equals()比较, 效率较低,哈希算法提高了去重复的效率, 降低了使用equals()方法的次数,其中HashSet底层基于哈希算法,当HashSet调用add方法存储对象,先调用对象的hashCode()方法得到一个哈希值, 然后在集合中查找是否有哈希值相同的对象,如果没有哈希值相同的对象就直接存入集合,如果有哈希值相同的对象, 就和哈希值相同的对象逐个进行equals()比较,比较结果为false就存入, true则不存。下面给出HashSet存储自定义对象的一个例子,自定义对象需要重写hashCode()和equals()方法。
/**
* 自定义对象
* @author 毛麒添
* HashSet 使用的bean 重写了equals和HashCode方法
*/
public class Person1 {
private String name;
private int age;
public Person1() {
super();
// TODO Auto-generated constructor stub
}
public Person1(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Person1 [name=" + name + ", age=" + age + "]";
}
//使HashSet存储元素唯一
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
System.out.println("equals调用了");
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Person1 other = (Person1) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
}
public class Demo1_Hashset {
public static void main(String[] args) {
HashSet<Person1> hs=new HashSet<Person1>();
hs.add(new Person1("张三", 23));
hs.add(new Person1("张三", 23));
hs.add(new Person1("李四", 24));
hs.add(new Person1("李四", 24));
hs.add(new Person1("李四", 24));
hs.add(new Person1("李四", 24));
System.out.println(hs);
}运行结果如图,达到了不存储重复自定义对象的目的。其实HashSet的下面还有一个LinkedHashSet,底层是链表实现的,是set中唯一一个能保证怎么存就怎么取的集合对象,是HashSet的子类,保证元素唯一,与HashSet原理一样,这里就不多说了。

最后是TreeSet集合,该集合是用来进行排序的,同样也可以保证元素的唯一,可以指定一个顺序, 对象存入之后会按照指定的顺序排列。
指定排序有两种实现:
Comparable:集合加入自定义对象的时候,自定义对象需要实现Comparable接口,
实现接口的抽象方法中返回0,则集合中只有一个元素
返回正数,则集合中怎么存则怎么取,
返回负数,集合倒序存储
Comparator(比较器):
创建TreeSet的时候可以制定 一个Comparator
如果传入了Comparator的子类对象, 那么TreeSet就会按照比较器中的顺序排序
add()方法内部会自动调用Comparator接口中compare()方法排序
调用的对象是compare方法的第一个参数,集合中的对象是compare方法的第二个参数
原理:
TreeSet底层二叉排序树
返回小的数字存储在树的左边(负数),大的存储在右边(正数),相等则不存(等于0)
在TreeSet集合中如何存取元素取决于compareTo()方法的返回值
下面来看例子:
/**
* 自定义对象 用于TreeSet
* @author 毛麒添
*
*/
public class Person implements Comparable<Person>{
private String name;
private int age;
public Person(){
super();
}
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + "]";
}
@Override
public boolean equals(Object obj) {
Person p=(Person) obj;
return this.name.equals(p.name)&&this.age==p.age;
}
@Override
public int hashCode() {
// TODO Auto-generated method stub
return 1;
}
/*//按照年龄进行排序(TreeSet)
@Override
public int compareTo(Person o) {
int number=this.age-o.age;//年龄是比较的主要条件
//当年龄一样的时候比较名字来确定排序
return number==0?this.name.compareTo(o.name):number;
}*/
//按照姓名进行排序(TreeSet)
@Override
public int compareTo(Person o) {
int number=this.name.compareTo(o.name);//姓名是比较的主要条件
//当姓名一样的时候比年龄来确定排序
return number==0?this.age- o.age:number;
}
//按照姓名长度进行排序(TreeSet)
/*@Override
public int compareTo(Person o) {
int length=this.name.length()-o.name.length();//姓名长度比较的次要条件
int number=length==0?this.name.compareTo(o.name):length;//姓名是比较的次要条件
//比年龄也是次要条件
return number==0?this.age- o.age:number;
}*/
}
/**
*
* @author 毛麒添
* TreeSet集合
* 集合加入自定义对象的时候,自定义对象需要实现Comparable接口,
* 实现接口的抽象方法中返回0,则集合中只有一个元素
* 返回正数,则集合中怎么存则怎么取,
* 返回负数,集合倒序存储
*
* 将字符按照长度来进行排序在TreeSet中,需要使用有比较的构造方法进行比较。
*/
public class Demo_TreeSet {
public static void main(String[] args) {
// TODO Auto-generated method stub
demo1();//整数存取排序
demo2();//自定义对象排序
//将字符按照长度来进行排序在TreeSet中
TreeSet<String> strLenset=new TreeSet<String>(new compareByLen());
strLenset.add("aaaaa");
strLenset.add("lol");
strLenset.add("wrc");
strLenset.add("wc");
strLenset.add("b");
strLenset.add("wnnnnnnnnnnn");
System.out.println(strLenset);
}
private static void demo2() {
TreeSet<Person> ptreeSet=new TreeSet<Person>();
ptreeSet.add(new Person("李四",12));
ptreeSet.add(new Person("李四",16));
ptreeSet.add(new Person("李青",16));
ptreeSet.add(new Person("王五",19));
ptreeSet.add(new Person("赵六",22));
System.out.println(ptreeSet);
}
private static void demo1() {
TreeSet< Integer> treeSet=new TreeSet<Integer>();
treeSet.add(1);
treeSet.add(1);
treeSet.add(1);
treeSet.add(3);
treeSet.add(3);
treeSet.add(3);
treeSet.add(2);
treeSet.add(2);
treeSet.add(2);
System.out.println(treeSet);
}
}
//TreeSet 构造器,实现compare对需要存储的字符串进行比较
class compareByLen implements Comparator<String>{
//按照字符串的长度进行比较,该方法的返回值和继承Comparable的compareTo方法返回值同理。
@Override
public int compare(String o1, String o2) {
int num=o1.length()-o2.length();//以长度为主要条件
return num==0?o1.compareTo(o2):num;//内容为次要条件
}
}下面是运行截图,其中compareTo的实现方法对几种条件排序进行了实现,具体可以查看Person自定义类中的实现。

单列集合复习就到这里吧。
双列集合
同样的,在复习双列结合之前我们先看看双列集合的继承图。

Map集合的功能梳理:
添加功能
V put(K key,V value):添加元素。
如果键是第一次存储,就直接存储元素,返回null
如果键不是第一次存在,就用值把以前的值替换掉,返回以前的值
删除功能
void clear():移除所有的键值对元素
V remove(Object key):根据键删除键值对元素,并把值返回
判断功能
boolean containsKey(Object key):判断集合是否包含指定的键
boolean containsValue(Object value):判断集合是否包含指定的值
boolean isEmpty():判断集合是否为空
获取功能
Set44bf986331d5d9c3931140ad55669b0c> entrySet():
V get(Object key):根据键获取值
Set245c3adc26563b673f7297c0b3777639 keySet():获取集合中所有键的集合
Collectiond94943c0b4933ad8cac500132f64757f values():获取集合中所有值的集合
长度功能
int size():返回集合中的键值对的个数
Map类集合也有三种遍历方式:
使用迭代器进行遍历
使用增强For循环来进行遍历
使用Map.Entry来遍历集合中的元素
下面我们来看看如何实现上面三种遍历方式
/**
*
* @author 毛麒添
* Map 集合的遍历
*/
public class Demo {
public static void main(String[] args) {
Map<String ,Integer> map=new HashMap<String, Integer>();
map.put("张三", 18);
map.put("李四", 19);
map.put("王五", 20);
map.put("赵六", 21);
//使用迭代器进行遍历
/*Set<String> keySet = map.keySet();//获取所有key的集合
Iterator<String> iterator = keySet.iterator();
while(iterator.hasNext()){
String key = iterator.next();
Integer i=map.get(key);
System.out.println(i);
}*/
//使用增强For循环来进行遍历
for (String key :map.keySet()) {
Integer integer = map.get(key);
System.out.println(integer);
}
/*---------------------------使用Map.Entry来遍历集合中的元素--------------------------*/
Set<Map.Entry<String,Integer>> en=map.entrySet();////获取所有的键值对象的集合
/*//使用迭代器来遍历
Iterator<Entry<String, Integer>> iterator = en.iterator();
while(iterator.hasNext()){
Entry<String, Integer> e=iterator.next();//获取键值对对象
String key = e.getKey();//根据键值对对象获取键
Integer value = e.getValue();//根据键值对对象获取值
System.out.print(key);
System.out.println(value);
}*/
//使用增强for循环来遍历
for (Entry<String, Integer> entry : en) {
String key = entry.getKey();
Integer value = entry.getValue();
System.out.print(key);
System.out.println(value);
}
/*---------------------------使用Map.Entry来遍历集合中的元素--------------------------*/
}
}LinkHashMap与LinkHashSet一样,怎么存怎么取,保证元素唯一(key 是唯一判定值),由于保证元素唯一,其性能肯定会低一些,这里就不细说了。
TreeMap是双列集合,其实他和TreeSet是很像的,但是双列集合的键是唯一标识,所以TreeMap排序的是每个元素的键。对于存储自定义对象排序,它也有Comparable和Comparator,下面我们来看例子
/**
*
* @author 毛麒添
* TreeMap
* 通TreeSet 原理,存取自定义对象也需要继承Comparable结构,
* 或者实现比较器Comparator
*/
public class Demo6_TreeMap {
public static void main(String[] args) {
TreeMap<Student, String> tm=new TreeMap<Student, String>(new Comparator<Student>() {
@Override
public int compare(Student s1, Student s2) {
int num=s1.getName().compareTo(s2.getName());//以姓名作为主要比较条件
return num==0?s1.getAge()-s2.getAge():num;
}
});
tm.put(new Student("张三",13),"杭州");
tm.put(new Student("张三",14), "贺州");
tm.put(new Student("王五",15), "广州");
tm.put(new Student("赵六",16), "深圳");
System.out.println(tm);
}
}
/**
* 自定义对象
* @author 毛麒添
* HashMap 存储对象 与 HashSet 同理 需要重写 hashcode 和equals 方法
* TreeMap 实现 Comparable接口
*/
public class Student implements Comparable<Student>{
private int age;
private String name;
public Student(){
super();
}
public Student(String name,int age){
this.name=name;
this.age=age;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Student [age=" + age + ", name=" + name + "]";
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Student other = (Student) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
@Override
public int compareTo(Student o) {
int num =this.age-o.age;//以年龄为主要条件
return num==0?this.name.compareTo(o.name):num;//姓名作为次要条件
}
}到这里,Java集合框架的复习基本完成,最后来一个斗地主的例子对集合框架做一个综合应用,只是实现斗地主洗牌和发牌,至于怎么打牌,逻辑复杂,这里不做实现。
/**
*
* @author 毛麒添
* 模拟斗地主洗牌和发牌,牌排序
* 买一副扑克
* 洗牌
* 发牌
* 看牌
*/
public class Doudizhu_progress {
public static void main(String[] args) {
// TODO Auto-generated method stub
//构造一副扑克牌
String[] number={"3","4","5","6","7","8","9","10","J","Q","K","A","2"};
String[]color={"黑桃","红桃","梅花","方块"};
HashMap<Integer, String> pokerMap=new HashMap<Integer, String>();//存放牌的map
ArrayList<Integer> list=new ArrayList<Integer>();//存放牌的索引
int index=0; //索引
for (String s1 : number) {
for (String s2 : color) {
pokerMap.put(index,s2.concat(s1));
list.add(index);
index++;
}
}
//加入大小王
pokerMap.put(index,"小王");
list.add(index);
index++;
pokerMap.put(index,"大王");
list.add(index);
//洗牌
Collections.shuffle(list);
//System.out.println(list);
//发牌,3个人玩 加上底牌3张 使用TreeSet 来存放索引,并自动对索引排好序
TreeSet<Integer> mao=new TreeSet<Integer>();
TreeSet<Integer> li=new TreeSet<Integer>();
TreeSet<Integer> huang=new TreeSet<Integer>();
TreeSet<Integer> dipai=new TreeSet<Integer>();
for(int i=0;i<list.size();i++){
if(i>=list.size()-3){//最后三张牌,作为底牌
dipai.add(list.get(i));
}else if(i%3==0){
mao.add(list.get(i));
}else if(i%3==1){
li.add(list.get(i));
}else {
huang.add(list.get(i));
}
}
//看牌
lookPoker(pokerMap,mao,"mao");
lookPoker(pokerMap,li,"li");
lookPoker(pokerMap,huang,"huang");
lookPoker(pokerMap,dipai,"底牌");
}
/**
* 看牌的方法
* @param pokerMap 存放牌的map
* @param mao 该玩家的牌的索引集合
* @param name 玩家名字
*/
private static void lookPoker(HashMap<Integer, String> pokerMap,
TreeSet<Integer> mao, String name) {
if(name.equals("底牌")){
System.out.print("地主"+name+"的牌是:");
}else{
System.out.print("玩家"+name+"的牌是:");
}
for (Integer integer : mao) {
System.out.print(pokerMap.get(integer)+" ");
}
System.out.println();
}
}运行截图:

写在最后:
Das obige ist der detaillierte Inhalt vonZusammenfassung der Verwendung des Java Collection Frameworks. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!