
Heim >Java >javaLernprogramm >Detaillierte Erläuterung der Java-Funktion zum Lesen von Dateien und zum Abrufen von Telefonnummern (basierend auf regulären Ausdrücken)
Detaillierte Erläuterung der Java-Funktion zum Lesen von Dateien und zum Abrufen von Telefonnummern (basierend auf regulären Ausdrücken)

- 黄舟Original
- 2017-09-06 14:16:572043Durchsuche
In diesem Artikel werden hauptsächlich das Lesen von Java-Dateien und die Funktion zum Abrufen von Telefonnummern basierend auf regulären Ausdrücken vorgestellt. Er analysiert die relevante Syntax regulärer Abgleichvorgänge sowie die Prinzipien und Implementierungstechniken des Telefonnummernabgleichs im Detail Wer es braucht, kann als Referenz
Das Beispiel in diesem Artikel beschreibt die Funktion zum Lesen von Dateien in Java und zum Abrufen von Telefonnummern basierend auf regulären Ausdrücken. Teilen Sie es als Referenz mit allen. Die Details lauten wie folgt:
1. Regulärer Ausdruck
Regulärer Ausdruck, auch als regulärer Ausdruck bekannt , Repräsentation regulärer Ausdrücke (englisch: Regular Expression, im Code oft als Regex, Regexp oder RE abgekürzt), ein Konzept in der Informatik. Reguläre Ausdrücke verwenden eine einzelne Zeichenfolge, um eine Reihe von Zeichenfolgen zu beschreiben und abzugleichen, die einer bestimmten Syntaxregel entsprechen. In vielen Texteditoren werden häufig reguläre Ausdrücke verwendet, um Text abzurufen und zu ersetzen, der einem bestimmten Muster entspricht.
Bedeutungsanalyse einiger speziell konstruierter regulärer Ausdrücke, die verwendet werden:
? |
Wenn dieses Zeichen unmittelbar auf einen der anderen Qualifizierer (*,+,?, {n}, {n,}, {n,m}) folgt, ist das Übereinstimmungsmuster nicht gierig. Der Non-Greedy-Modus stimmt so wenig wie möglich mit der gesuchten Zeichenfolge überein, während der Standard-Greedy-Modus so viel wie möglich mit der gesuchten Zeichenfolge übereinstimmt. Beispielsweise entspricht für die Zeichenfolge „oooo“ „o+?“ einem einzelnen „o“, während „o+“ allen „o“ entspricht. |
Punkt |
entspricht jedem einzelnen Zeichen außer „rn“. Um ein beliebiges Zeichen einschließlich „rn“ zu finden, verwenden Sie ein Muster wie „[sS]“. |
(Muster) |
Vergleichen Sie Muster und erhalten Sie diese Übereinstimmung. Die erhaltenen Übereinstimmungen können aus der generierten Matches-Sammlung abgerufen werden, indem die SubMatches-Sammlung in VBScript und die $0...$9-Attribute in JScript verwendet werden. Um Klammerzeichen zuzuordnen, verwenden Sie „“. |
(?:pattern) |
stimmt mit dem Muster überein, erhält aber nicht das passende Ergebnis, was bedeutet, dass es sich um ein Muster handelt Nicht-Übereinstimmungen werden abgerufen, ohne sie zur späteren Verwendung zu speichern. Dies ist nützlich, wenn Sie Teile eines Musters mit dem oder-Zeichen „(|)“ kombinieren. Beispielsweise ist „industr(?:y|ies)“ ein einfacherer Ausdruck als „industry|industries“. |
(?=Muster) |
Positive positive Suche, am Anfang eines beliebigen Zeichenfolgenübereinstimmungsmusters. Entspricht der Suche Zeichenfolge. Dies ist eine Nicht-Abruf-Übereinstimmung, d. h. die Übereinstimmung muss nicht zur späteren Verwendung abgerufen werden. Beispielsweise kann „Windows(?=95|98|NT|2000)“ mit „Windows“ in „Windows2000“ übereinstimmen, aber nicht mit „Windows“ in „Windows3.1“. Beim Vorabruf werden keine Zeichen verbraucht, d. h. nach einer Übereinstimmung beginnt die Suche nach der nächsten Übereinstimmung unmittelbar nach der letzten Übereinstimmung und nicht nach dem Zeichen, das den Vorabruf enthält. |
(?!pattern) |
Positiv-Negativ-Suche, beginnend mit einer beliebigen Zeichenfolge, die nicht mit dem Muster übereinstimmt Suchzeichenfolge. Dies ist eine Nicht-Abruf-Übereinstimmung, d. h. die Übereinstimmung muss nicht zur späteren Verwendung abgerufen werden. Beispielsweise kann „Windows(?!95|98|NT|2000)“ mit „Windows“ in „Windows3.1“ übereinstimmen, aber nicht mit „Windows“ in „Windows2000“. |
|
(?5e769f0d22ddc4005190e40690647dc1\D?\d{1,4})? 以上拼装起来就是: "(?:(\\(\\+?86\\))(0[0-9]{2,3}\\-?)?([2-9][0-9]{6,7})+(\\-[0-9]{1,4})?)|" + 4、编码实现 实现功能:读取文件,将其中的电话号码存入一个Set返回。 方法介绍:
①、从一个字符串中获取出其中的电话号码 import java.util.HashSet;
import java.util.Set;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 从字符串中截取出电话号码
* @author zcr
*
*/
public class CheckIfIsPhoneNumber
{
/**
* 获得电话号码的正则表达式:包括固定电话和移动电话
* 符合规则的号码:
* 1》、移动电话
* 86+‘-'+11位电话号码
* 86+11位正常的电话号码
* 11位正常电话号码a
* (+86) + 11位电话号码
* (86) + 11位电话号码
* 2》、固定电话
* 区号 + ‘-' + 固定电话 + ‘-' + 分机号
* 区号 + ‘-' + 固定电话
* 区号 + 固定电话
* @return 电话号码的正则表达式
*/
public static String isPhoneRegexp()
{
String regexp = "";
//能满足最长匹配,但无法完成国家区域号和电话号码之间有空格的情况
String mobilePhoneRegexp = "(?:(\\(\\+?86\\))((13[0-9]{1})|(15[0-9]{1})|(18[0,5-9]{1}))+\\d{8})|" +
"(?:86-?((13[0-9]{1})|(15[0-9]{1})|(18[0,5-9]{1}))+\\d{8})|" +
"(?:((13[0-9]{1})|(15[0-9]{1})|(18[0,5-9]{1}))+\\d{8})";
// System.out.println("regexp = " + mobilePhoneRegexp);
//固定电话正则表达式
String landlinePhoneRegexp = "(?:(\\(\\+?86\\))(0[0-9]{2,3}\\-?)?([2-9][0-9]{6,7})+(\\-[0-9]{1,4})?)|" +
"(?:(86-?)?(0[0-9]{2,3}\\-?)?([2-9][0-9]{6,7})+(\\-[0-9]{1,4})?)";
regexp += "(?:" + mobilePhoneRegexp + "|" + landlinePhoneRegexp +")";
return regexp;
}
/**
* 从dataStr中获取出所有的电话号码(固话和移动电话),将其放入Set
* @param dataStr 待查找的字符串
* @param phoneSet dataStr中的电话号码
*/
public static void getPhoneNumFromStrIntoSet(String dataStr,Set<String> phoneSet)
{
//获得固定电话和移动电话的正则表达式
String regexp = isPhoneRegexp();
System.out.println("Regexp = " + regexp);
Pattern pattern = Pattern.compile(regexp);
Matcher matcher = pattern.matcher(dataStr);
//找与该模式匹配的输入序列的下一个子序列
while (matcher.find())
{
//获取到之前查找到的字符串,并将其添加入set中
phoneSet.add(matcher.group());
}
//System.out.println(phoneSet);
}
}②、读取文件并调用电话号码获取 实现方式:根据文件路径获得文件后,一行行读取,去获取里面的电话号码 import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
/**
* 读取文件操作
*
* @author zcr
*
*/
public class ImportFile
{
/**
* 读取文件,将文件中的电话号码读取出来,保存在Set中。
* @param filePath 文件的绝对路径
* @return 文件中包含的电话号码
*/
public static Set<String> getPhoneNumFromFile(String filePath)
{
Set<String> phoneSet = new HashSet<String>();
try
{
String encoding = "UTF-8";
File file = new File(filePath);
if (file.isFile() && file.exists())
{ // 判断文件是否存在
InputStreamReader read = new InputStreamReader(
new FileInputStream(file), encoding);// 考虑到编码格
BufferedReader bufferedReader = new BufferedReader(read);
String lineTxt = null;
while ((lineTxt = bufferedReader.readLine()) != null)
{
//读取文件中的一行,将其中的电话号码添加到phoneSet中
CheckIfIsPhoneNumber.getPhoneNumFromStrIntoSet(lineTxt, phoneSet);
}
read.close();
}
else
{
System.out.println("找不到指定的文件");
}
}
catch (Exception e)
{
System.out.println("读取文件内容出错");
e.printStackTrace();
}
return phoneSet;
}
}③、测试 public static void main(String argv[])
{
String filePath = "F:\\three.txt";
Set<String> phoneSet = getPhoneNumFromFile(filePath);
System.out.println("电话集合:" + phoneSet);
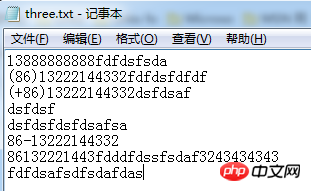
}文件中数据:
结果: 电话集合:[86132221, (86)13222144332, 86-13222144332, 32434343, (+86)13222144332, 13888888888] |
Das obige ist der detaillierte Inhalt vonDetaillierte Erläuterung der Java-Funktion zum Lesen von Dateien und zum Abrufen von Telefonnummern (basierend auf regulären Ausdrücken). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!