
Heim >Web-Frontend >js-Tutorial >Beispiele zur Erläuterung der Interpretation von HTML-Tags in DOM-Knoten
Beispiele zur Erläuterung der Interpretation von HTML-Tags in DOM-Knoten
- 巴扎黑Original
- 2017-09-01 11:54:431499Durchsuche
Der folgende Editor bringt Ihnen einen Artikel [Der Weg zum JS-Meister] über die Interpretation von HTML-Tags in DOM-Knoten. Der Herausgeber findet es ziemlich gut, deshalb werde ich es jetzt mit Ihnen teilen und es allen als Referenz geben. Schauen wir uns den Editor an
Kürzlich habe ich ein Open-Source-Framework geschrieben, das bereits 500 Zeilen geschrieben hat. Es wird auch eine große Anzahl von Tools erweitern Funktionen und MVVM-Zwei-Wege-Treiberfunktionen in der Zukunft. Die Verwendungsmethode ist genau die gleiche wie bei jquery. Warum hat dies etwas mit dem Thema dieses Artikels zu tun? Denn in diesem Artikel geht es um ein Problem, auf das ich beim Schreiben eines Frameworks gestoßen bin. Es kapselt die After-Methode von jquery und unterstützt zwei Verwendungen von DOM- und HTML-Tags. Das HTML-Tag übergibt Parameter in eine DOM-Struktur einfügen.
Zuerst schreiben wir ein allgemeines HTML-Tag:
b57c4b6d14a378d80001558f704e08c2dies ist eine Testzeichenfolge94b3e26ee717c64999d7867364b1b4a3
Dieser HTML-Code enthält Ereignisse, Stile, Attribute und Inhalte.
Wir verwenden dann „regular“. Ausdrücke zum Konvertieren dieses HTML. Um jeden Teil abzugleichen, benötigen wir:
1. Tag-Name, denn beim Erstellen eines Dom-Knotens werden
benötigt muss separat getrennt werden
Um die Erstellung von Dom zu erleichtern, verwenden wir einen JSON, um ihn zu speichern, z. B. dieses Tag. Das Endergebnis, das wir verarbeiten möchten, ist:
{
id:"test
inner:"this is a test string
name:"test"
onclick:"test();"
style:"color:red;background:green;"
tag:"p"
}Wenn wir diese Struktur haben, können Sie es tun, solange Sie die entsprechenden Schlüssel und Werte erhalten und sie zu einem Dom zusammenfügen
var o = document.createElement( obj['tag'] );
o.innerHTML = obj['inner'];
delete obj['inner'];
delete obj['tag'];
for( var key in obj ){
o.setAttribute( key, obj[key] );
}
document.body.appendChild( o );Die Erklärungsidee ist klar, daher müssen wir zuerst jeden Teil des HTML-Tags mit einem regulären Ausdruck
var re = /<(\w+\s*)(\w+[=][\'\"](.*)?[\'\"]\s*)*>(.*)?<\/\w+>/; var str = '<p onclick="test();" name="test" id="test">this is a test string</p>'; var res = str.match(re);
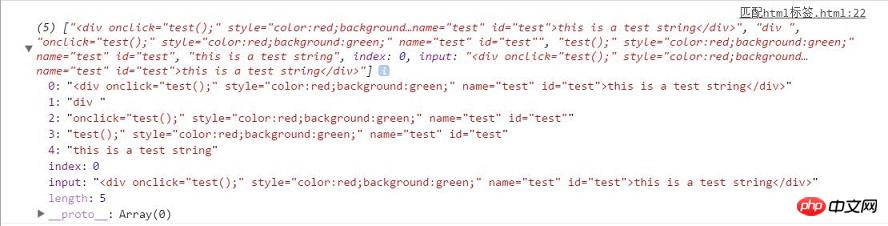
var re = /<(\w+\s*)(\w+[=][\'\"](.*)?[\'\"]\s*)*>(.*)?<\/\w+>/;
var str = '<p onclick="test();" name="test" id="test">this is a test string</p>';
var res = str.match(re);
var tagName = null, attrList = [], arr = [], obj = {};
if( res[1] ) {
tagName = res[1].trim();
obj['tag'] = tagName;
}
if( res[4] ) {
obj['inner'] = res[4];
}
if ( res[2] ) {
attrList = res[2].split( /\s+/ );
for( var i = 0, len = attrList.length; i < len; i++ ){
arr = attrList[i].split("=");
// console.log( arr );
obj[arr[0]] = arr[1].replace( /(^[\'\"]+|[\'\"]$)/g, function(){
return '';
} );
}
}
var o = document.createElement( obj['tag'] );
o.innerHTML = obj['inner'];
delete obj['inner'];
delete obj['tag'];
for( var key in obj ){
o.setAttribute( key, obj[key] );
}
document.body.appendChild( o );Sie können eine Funktion selbst kapseln, ich glaube, Sie können sie leicht kapseln.Das obige ist der detaillierte Inhalt vonBeispiele zur Erläuterung der Interpretation von HTML-Tags in DOM-Knoten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Eine eingehende Analyse der Bootstrap-Listengruppenkomponente
- Detaillierte Erläuterung des JavaScript-Funktions-Curryings
- Vollständiges Beispiel für die Generierung von JS-Passwörtern und die Erkennung der Stärke (mit Download des Demo-Quellcodes)
- Angularjs integriert WeChat UI (weui)
- Wie man mit JavaScript schnell zwischen traditionellem Chinesisch und vereinfachtem Chinesisch wechselt und wie Websites den Wechsel zwischen vereinfachtem und traditionellem Chinesisch unterstützen – Javascript-Kenntnisse