
Heim >Betrieb und Instandhaltung >Betrieb und Wartung von Linux >Eine ausführliche Einführung in die Speicherverwaltung unter Linux
Eine ausführliche Einführung in die Speicherverwaltung unter Linux
- 巴扎黑Original
- 2017-08-23 15:50:171374Durchsuche
Ich habe vor einiger Zeit „Ausführliches Verständnis des Linux-Kernels“ gelesen und viel Zeit mit dem Speicherverwaltungsteil verbracht, aber es gibt immer noch viele Fragen, die ich kürzlich einige Zeit lang überprüft habe Ich habe hier mein Verständnis und einige Ansichten und Kenntnisse zur Speicherverwaltung unter Linux aufgezeichnet.
Ich bevorzuge es, den Entwicklungsprozess einer Technologie selbst zu verstehen. Kurz gesagt geht es darum, wie sich diese Technologie entwickelt hat, welche Technologien es vor dieser Technologie gab, was die Merkmale dieser Technologien sind und warum sie derzeit verwendet werden. Sie wurde durch neue Technologie ersetzt und die aktuelle Technologie hat die Probleme der vorherigen Technologie gelöst. Sobald wir diese verstanden haben, können wir eine bestimmte Technologie besser verstehen. Einige Materialien führen direkt in die Bedeutung und Prinzipien eines bestimmten Konzepts ein, ohne den Entwicklungsprozess und die dahinter stehenden Prinzipien zu erwähnen, als ob die Technologie vom Himmel gefallen wäre. Lassen Sie uns an dieser Stelle über das heutige Thema sprechen, das auf der Entwicklungsgeschichte der Speicherverwaltung basiert.
Zunächst muss ich erklären, dass das Thema dieses Artikels die Segmentierungs- und Paging-Technologie in der Linux-Speicherverwaltung ist.
Werfen wir einen Blick zurück in die Geschichte. In frühen Computern liefen Programme direkt auf dem physischen Speicher. Mit anderen Worten: Alle Programme, auf die während der Ausführung zugegriffen wird, sind physikalische Adressen. Wenn dieses System nur ein Programm ausführt, gibt es kein Problem, solange der von diesem Programm benötigte Speicher den physischen Speicher der Maschine nicht überschreitet, und wir müssen uns nicht um die mühsame Speicherverwaltung kümmern Nur Ihr Programm, das ist alles. Sparen Sie etwas Geld, es liegt an Ihnen, ob Sie genug essen oder nicht. Heutige Systeme unterstützen jedoch Multitasking und Multi-Processing, sodass die Auslastung der CPU und anderer Hardware höher sein wird. Zu diesem Zeitpunkt müssen wir überlegen, wie wir den begrenzten physischen Speicher im System zeitnah und zeitnah zuweisen können Diese Angelegenheit selbst wird als Speicherverwaltung bezeichnet.
Lassen Sie uns ein Beispiel für die Speicherzuteilungsverwaltung in einem frühen Computersystem geben, um das Verständnis für alle zu erleichtern.
Wir haben drei Programme, Programm 1, 2 und 3. Programm 1 benötigt beim Ausführen 10 MB Speicher, Programm 2 benötigt beim Ausführen 100 MB Speicher und Programm 3 benötigt beim Ausführen 20 MB Speicher. Wenn das System die Programme A und B gleichzeitig ausführen muss, sieht der frühe Speicherverwaltungsprozess wahrscheinlich wie folgt aus: Die ersten 10 MB des physischen Speichers werden A und die nächsten 10 bis 110 MB B zugewiesen. Diese Methode der Speicherverwaltung ist relativ einfach. Nehmen wir an, wir möchten, dass Programm C zu diesem Zeitpunkt ausgeführt wird, und gehen davon aus, dass der Speicher unseres Systems nur 128 MB beträgt. Offensichtlich kann Programm C aufgrund unzureichender Speicherkapazität nicht ausgeführt werden Erinnerung. Jeder weiß, dass Sie die virtuelle Speichertechnologie verwenden können, wenn der Speicherplatz nicht ausreicht. Sie können Daten, die vom Programm nicht verwendet werden, in Speicherplatz austauschen, wodurch der Zweck der Erweiterung des Speicherplatzes erreicht wird. Werfen wir einen Blick auf einige der offensichtlicheren Probleme dieser Speicherverwaltungsmethode. Wie am Anfang des Artikels erwähnt, ist es für ein tiefes Verständnis einer Technologie am besten, deren Entwicklungsgeschichte zu verstehen.
1. Der Prozessadressraum kann nicht isoliert werden
Da das Programm direkt auf den physischen Speicher zugreift, ist der vom Programm verwendete Speicherplatz zu diesem Zeitpunkt nicht isoliert. Wie oben erwähnt, liegt der Adressraum von A beispielsweise im Bereich von 0 bis 10 MB. Wenn sich jedoch in A ein Codeabschnitt befindet, der Daten im Adressraum von 10 bis 128 MB verarbeitet, sind dies Programm B und Programm C wahrscheinlich zum Absturz (jedes Programm kann den gesamten Adressraum des Systems belegen). Auf diese Weise können viele Schadprogramme oder Trojaner leicht andere Programme zerstören und die Sicherheit des Systems kann nicht gewährleistet werden, was für Benutzer unerträglich ist.
2. Die Speichernutzung ist ineffizient
Wie oben erwähnt, besteht die einzige Möglichkeit darin, die virtuelle Speichertechnologie zu verwenden, wenn wir die Programme A, B und C gleichzeitig ausführen lassen möchten Um einige Daten zu kombinieren, die vom Programm vorübergehend nicht verwendet werden, werden sie auf die Festplatte geschrieben und bei Bedarf von der Festplatte in den Speicher zurückgelesen. Um Programm C hier auszuführen, ist das Auslagern von A auf die Festplatte offensichtlich nicht möglich, da das Programm einen kontinuierlichen Adressraum benötigt. Programm C benötigt 20 MB Speicher und A verfügt nur über 10 MB Speicherplatz, sodass Programm B auf die Festplatte ausgelagert werden muss . und B ist vollständig 100 MB. Wir können sehen, dass wir 100 MB Daten vom Speicher auf die Festplatte schreiben und diese dann von der Festplatte auf den Speicher lesen müssen. Wir wissen, dass IO ausgeführt werden muss Die Vorgänge sind zeitaufwändig, daher ist die Effizienz dieses Prozesses sehr gering.
3. Die Adresse, an der das Programm ausgeführt wird, kann nicht ermittelt werden.
Jedes Mal, wenn das Programm ausgeführt werden muss, muss es einen ausreichend großen freien Bereich im Speicher zuweisen. Das Problem ist, dass dieser frei ist Standort kann nicht sicher sein, dies führt zu einigen Verschiebungsproblemen. Wenn Sie die Adressen der im Programm referenzierten Variablen und Funktionen nicht verstehen, können Sie die Kompilierungsinformationen überprüfen.
Speicherverwaltung ist nichts anderes als die Suche nach Möglichkeiten zur Lösung der oben genannten drei Probleme, zur Isolierung des Adressraums des Prozesses, zur Verbesserung der Effizienz der Speichernutzung und zur Lösung des Verschiebungsproblems beim Programm läuft?
Hier ist ein Zitat aus einem berühmten Sprichwort der Computerindustrie, das nicht überprüft werden kann: „Jedes Problem in einem Computersystem kann durch die Einführung einer Zwischenschicht gelöst werden.“
Die aktuelle Speicherverwaltungsmethode führt das Konzept des virtuellen Speichers zwischen dem Programm und dem physischen Speicher ein. Der virtuelle Speicher befindet sich zwischen dem Programm und dem internen Speicher. Das Programm kann nur noch den virtuellen Speicher sehen und nicht mehr direkt auf den physischen Speicher zugreifen. Jedes Programm verfügt über einen eigenen unabhängigen Prozessadressraum, wodurch eine Prozessisolation erreicht wird. Der Prozessadressraum bezieht sich hier auf die virtuelle Adresse. Da es sich, wie der Name schon sagt, um eine virtuelle Adresse handelt, handelt es sich um einen virtuellen und nicht um einen realen Adressraum.
Da wir eine virtuelle Adresse zwischen dem Programm und dem physischen Adressraum hinzugefügt haben, müssen wir herausfinden, wie wir die virtuelle Adresse auf die physische Adresse abbilden, da das Programm letztendlich hauptsächlich im physischen Speicher ausgeführt werden muss segmentiert und Paging zwei Technologien.
Segmentierung: Diese Methode ist eine der ersten Methoden, die Menschen verwenden. Die Grundidee besteht darin, den vom Programm benötigten virtuellen Raum des Speicheradressraums einem bestimmten physischen Adressraum zuzuordnen.
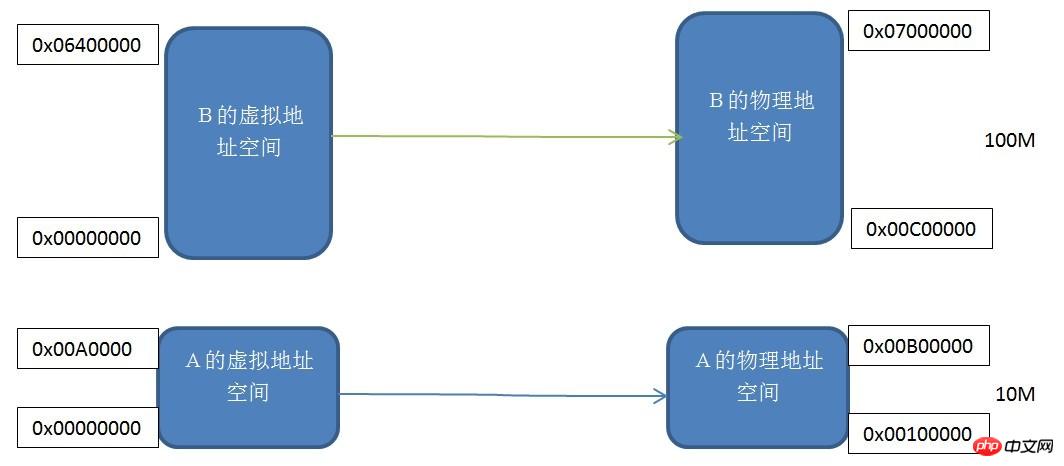
Segmentzuordnungsmechanismus
Jedes Programm verfügt über einen eigenen virtuellen, unabhängigen Prozessadressraum. Sie können die virtuellen Adressen der Programme A und B sehen. Die Leerzeichen sind alle Beginnen Sie bei 0x00000000. Wir ordnen zwei virtuelle Adressräume nacheinander dem tatsächlichen physischen Adressraum zu, dh jedes Byte im virtuellen Adressraum entspricht jedem Byte im tatsächlichen Adressraum. Dieser Zuordnungsprozess wird durch die Software festgelegt. Die eigentliche Konvertierung erfolgt durch Hardware.
Dieser segmentierte Mechanismus löst die drei am Anfang des Artikels genannten Probleme: Isolierung des Prozessadressraums und Verschiebung der Programmadresse. Programm A und Programm B verfügen über eigene unabhängige virtuelle Adressräume, und die virtuellen Adressräume werden nicht überlappenden physischen Adressräumen zugeordnet. Wenn die Adresse, auf die Programm A zugreift, nicht im Bereich von 0x00000000-0x00A00000 liegt Der Kernel lehnt diese Anfrage ab und löst so das Problem der Isolierung des Adressraums. Unsere Anwendung A muss sich nur um ihren virtuellen Adressraum 0x00000000-0x00A00000 kümmern, und wir müssen uns nicht darum kümmern, welcher physischen Adresse sie zugeordnet ist, sodass das Programm Variablen und Code immer ohne Verschiebung entsprechend diesem virtuellen Adressraum platziert.
Auf jeden Fall löst der Segmentierungsmechanismus die beiden oben genannten Probleme, was einen großen Fortschritt darstellt, aber er ist immer noch machtlos, um das Problem der Speichereffizienz zu lösen. Da dieser Speicherzuordnungsmechanismus immer noch auf dem Programm basiert, muss bei unzureichendem Speicher immer noch das gesamte Programm auf die Festplatte ausgelagert werden, sodass die Speichernutzungseffizienz immer noch sehr gering ist. Was gilt also als effiziente Speichernutzung? Tatsächlich wird gemäß dem lokalen Betriebsprinzip des Programms während eines bestimmten Zeitraums während der Ausführung eines Programms nur ein kleiner Teil der Daten häufig verwendet. Wir brauchen also eine detailliertere Methode zur Speicherpartitionierung und -zuordnung. Denken Sie zu diesem Zeitpunkt an den Buddy-Algorithmus und den Slab-Speicherzuweisungsmechanismus in Linux, haha. Eine weitere Möglichkeit, virtuelle Adressen in physische Adressen umzuwandeln, ist der Paging-Mechanismus.
Paging-Mechanismus:
Der Paging-Mechanismus besteht darin, den Speicheradressraum in mehrere kleine Seiten fester Größe aufzuteilen. Die Größe jeder Seite wird durch den Speicher bestimmt, genau wie das ext-Dateisystem Linux Die Aufteilung der Festplatte in mehrere Blöcke erfolgt, um die Speicher- bzw. Festplattennutzung zu verbessern. Stellen Sie sich Folgendes vor: Wenn der Festplattenspeicher in N gleiche Teile unterteilt ist, beträgt die Größe jedes Teils (ein Block) 1 MB. Wenn die Datei, die ich auf der Festplatte speichern möchte, 1 KB groß ist, werden die verbleibenden 999 Byte verschwendet. Daher ist eine differenziertere Festplattenpartitionierungsmethode erforderlich. Dies hängt natürlich von der Größe der gespeicherten Dateien ab. Ich möchte nur sagen, dass das Paging etwas abweicht Mechanismus im Speicher unterscheidet sich von ext. Der Festplattenpartitionierungsmechanismus in Dateisystemen ist sehr ähnlich.
Die allgemeine Seitengröße unter Linux beträgt 4 KB. Wir teilen den Adressraum des Prozesses nach Seiten auf, laden häufig verwendete Daten und Codepages in den Speicher und speichern den weniger häufig verwendeten Code und die Daten auf der Festplatte. Wir wollen es noch anhand eines Beispiels veranschaulichen, wie unten gezeigt:
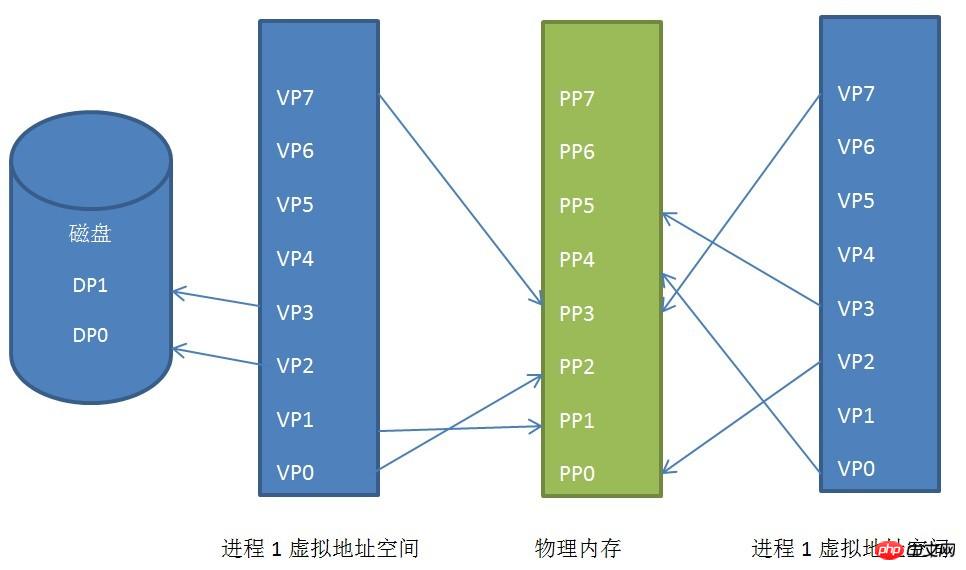
Seitenzuordnungsbeziehung zwischen virtuellem Adressraum, physischem Adressraum und Festplatte des Prozesses
Wir können sehen Die virtuellen Adressräume von Prozess 1 und Prozess 2 werden in diskontinuierliche physische Adressräume abgebildet (dies ist von großer Bedeutung, wenn wir eines Tages nicht genügend kontinuierlichen physischen Adressraum haben, aber es viele diskontinuierliche Adressräume gibt, wenn es keinen solchen gibt). Technologie kann unser Programm nicht ausgeführt werden), auch wenn sie sich einen Teil des physischen Adressraums teilen, der gemeinsam genutzter Speicher ist.
Die virtuellen Seiten VP2 und VP3 von Prozess 1 werden auf die Festplatte verlagert. Wenn das Programm diese beiden Seiten benötigt, generiert der Linux-Kernel eine Seitenfehlerausnahme und das Ausnahmeverwaltungsprogramm liest sie dann ein Erinnerung.
Dies ist das Prinzip des Paging-Mechanismus. Natürlich ist die Implementierung des Paging-Mechanismus in Linux immer noch relativ kompliziert. Er wird über das globale Verzeichnis, das übergeordnete Verzeichnis, das Seitenzwischenverzeichnis und die Seitentabelle implementiert Ebenen des Paging-Mechanismus Ja, aber das grundlegende Funktionsprinzip wird sich nicht ändern.
Die Implementierung des Paging-Mechanismus erfordert eine Hardware-Implementierung. Der Name dieser Hardware ist MMU (Memory Management Unit). Sie ist speziell für die Konvertierung von virtuellen Adressen in physische Adressen verantwortlich, dh für das Auffinden physischer Seiten aus virtuellen Seiten.
Das obige ist der detaillierte Inhalt vonEine ausführliche Einführung in die Speicherverwaltung unter Linux. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Erfahren Sie, wie Sie den Nginx-Server unter Linux installieren
- Detaillierte Einführung in den wget-Befehl von Linux
- Ausführliche Erläuterung von Beispielen für die Verwendung von yum zur Installation von Nginx unter Linux
- Detaillierte Erläuterung der Worker-Verbindungsprobleme in Nginx
- Detaillierte Erläuterung des Installationsprozesses von Python3 unter Linux