
Heim >Backend-Entwicklung >Python-Tutorial >Das einfachste Webcrawler-Tutorial in Python
Das einfachste Webcrawler-Tutorial in Python

- 黄舟Original
- 2017-08-13 10:41:392121Durchsuche
Wenn wir jeden Tag im Internet surfen, sehen wir oft einige gut aussehende Bilder und wir möchten diese Bilder speichern und herunterladen oder sie als Desktop-Hintergrundbilder oder als Designmaterialien verwenden. Der folgende Artikel stellt Ihnen die relevanten Informationen zur Verwendung von Python zur Implementierung des einfachsten Webcrawlers vor. Lassen Sie uns gemeinsam einen Blick darauf werfen.
Vorwort
Webcrawler (in der FOAF-Community auch als Webspider, Webroboter bekannt, allgemeiner als Webcrawler (oder ) ist ein Programm oder Skript, das nach bestimmten Regeln automatisch World Wide Web-Informationen erfasst. In letzter Zeit interessiere ich mich sehr für Python-Crawler. Ich möchte hier meinen Lernpfad teilen und freue mich über Ihre Vorschläge. Wir kommunizieren miteinander und kommen gemeinsam voran. Werfen wir ohne weiteres einen Blick auf die ausführliche Einführung:
1. Entwicklungstools
Der Autor verwendet Das beste Werkzeug ist sublime text3. Es ist kurz und prägnant (vielleicht mögen Männer dieses Wort nicht) und fasziniert mich sehr. Die Verwendung wird natürlich jedem empfohlen. Wenn Ihre Computerkonfiguration gut ist, ist Pycharm möglicherweise besser für Sie geeignet.
Es wird empfohlen, diesen Artikel zu lesen, um eine Python-Entwicklungsumgebung mit Sublime Text3 zu erstellen:
[Einrichten einer Python-Entwicklungsumgebung mit Sublime]
Wie der Name schon sagt, sind Crawler wie Käfer, die im großen Netz des Internets herumkriechen. Auf diese Weise können wir bekommen, was wir wollen.
Da wir im Internet crawlen möchten, müssen wir die URL verstehen, der legale Name ist „Uniform Resource Locator“ und der Spitzname ist „Link“. Seine Struktur besteht hauptsächlich aus drei Teilen:
(1) Protokoll: wie das HTTP-Protokoll, das wir häufig in URLs sehen.
(2) Domänenname oder IP-Adresse: Domänenname, z. B. www.baidu.com, IP-Adresse, d. h. die entsprechende IP nach der Auflösung des Domänennamens.
(3) Pfad: Verzeichnis oder Datei usw.
3. urllib ist der am einfachsten zu entwickelnde Crawler
(1) Einführung in urllib
| Module | Introduce |
|---|---|
| urllib.error | Exception classes raised by urllib.request. |
| urllib.parse | Parse URLs into or assemble them from components. |
| urllib.request | Extensible library for opening URLs. |
| urllib.response | Response classes used by urllib. |
| urllib.robotparser | Load a robots.txt file and answer questions about fetchability of other URLs. |
(2) Entwickeln Sie den einfachsten Crawler
Die Baidu-Homepage ist einfach und elegant, was für unsere Crawler sehr gut geeignet ist.
Der Crawler-Code lautet wie folgt:
from urllib import request
def visit_baidu():
URL = "http://www.baidu.com"
# open the URL
req = request.urlopen(URL)
# read the URL
html = req.read()
# decode the URL to utf-8
html = html.decode("utf_8")
print(html)
if __name__ == '__main__':
visit_baidu()Das Ergebnis ist wie folgt:
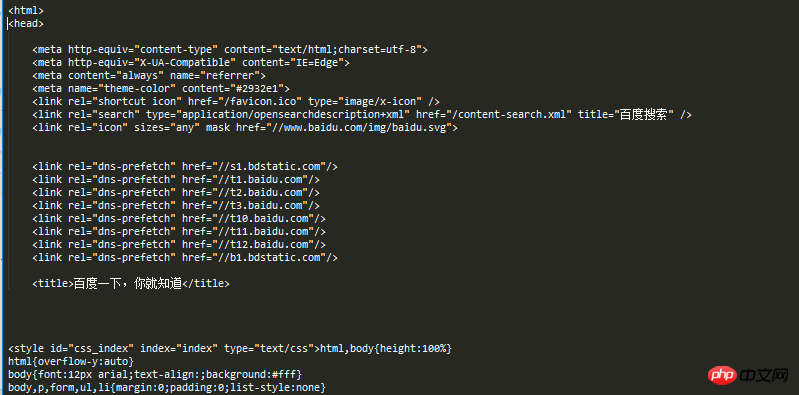
Wir können mit unseren Laufergebnissen vergleichen, indem wir mit der rechten Maustaste auf den leeren Bereich der Baidu-Homepage klicken, um die Bewertungselemente anzuzeigen.
Natürlich kann request auch ein Request-Objekt generieren, das mit der urlopen-Methode geöffnet werden kann.
Der Code lautet wie folgt:
from urllib import request def vists_baidu(): # create a request obkect req = request.Request('http://www.baidu.com') # open the request object response = request.urlopen(req) # read the response html = response.read() html = html.decode('utf-8') print(html) if __name__ == '__main__': vists_baidu()
Das Laufergebnis ist das gleiche wie zuvor.
(3) Fehlerbehandlung
Die Fehlerbehandlung erfolgt über das urllib-Modul. Es gibt hauptsächlich URLError- und HTTPError-Fehler, darunter HTTPError-Fehler ist ein URLError-Fehler. Unterklassen von HTTRPError können auch von URLError abgefangen werden.
HTTPError kann über sein Codeattribut abgefangen werden.
Der Code zur Behandlung von HTTPError lautet wie folgt:
from urllib import request
from urllib import error
def Err():
url = "https://segmentfault.com/zzz"
req = request.Request(url)
try:
response = request.urlopen(req)
html = response.read().decode("utf-8")
print(html)
except error.HTTPError as e:
print(e.code)
if __name__ == '__main__':
Err()Das laufende Ergebnis ist wie in der Abbildung dargestellt:

404 ist der gedruckte Fehlercode. Detaillierte Informationen hierzu erhalten Sie bei Baidu.
URLError kann über sein Reason-Attribut abgefangen werden.
Der Code von chuliHTTPError lautet wie folgt:
from urllib import request
from urllib import error
def Err():
url = "https://segmentf.com/"
req = request.Request(url)
try:
response = request.urlopen(req)
html = response.read().decode("utf-8")
print(html)
except error.URLError as e:
print(e.reason)
if __name__ == '__main__':
Err()Das laufende Ergebnis ist wie in der Abbildung dargestellt:

Um Fehler zu behandeln, ist es am besten, beide Fehler in den Code zu schreiben. Denn je detaillierter der Code, desto klarer. Es ist zu beachten, dass HTTPError eine Unterklasse von URLError ist. Daher muss HTTPError vor URLError platziert werden, andernfalls wird URLError ausgegeben, z. B. 404 als Nicht gefunden.
Der Code lautet wie folgt:
from urllib import request
from urllib import error
# 第一种方法,URLErroe和HTTPError
def Err():
url = "https://segmentfault.com/zzz"
req = request.Request(url)
try:
response = request.urlopen(req)
html = response.read().decode("utf-8")
print(html)
except error.HTTPError as e:
print(e.code)
except error.URLError as e:
print(e.reason)Sie können die URL ändern, um die Ausgabeform verschiedener Fehler anzuzeigen.
Zusammenfassung
Das obige ist der detaillierte Inhalt vonDas einfachste Webcrawler-Tutorial in Python. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!