
Heim >Backend-Entwicklung >PHP-Tutorial >Beispiel für PHP-Parallelität zum Abfragen von MySQL (Bild)
Beispiel für PHP-Parallelität zum Abfragen von MySQL (Bild)

- 黄舟Original
- 2018-05-24 09:21:062191Durchsuche
In diesem Artikel wird hauptsächlich der Beispielcode für die gleichzeitige PHP-Abfrage von MySQL vorgestellt. Der Herausgeber findet ihn recht gut, daher werde ich ihn jetzt mit Ihnen teilen und als Referenz verwenden. Lassen Sie uns dem Editor folgen und einen Blick darauf werfen.
Ich habe kürzlich PHP studiert und bin auf das Problem der gleichzeitigen Abfrage von MySQL gestoßen Weg:
Synchronisationsabfrage
Dies ist unser häufigster Aufrufmodus. Der Client ruft Query[Funktion] auf, initiiert einen Abfragebefehl und wartet auf die Rückgabe des Ergebnisses , liest das Ergebnis; sendet dann den zweiten Abfragebefehl und wartet auf die Rückgabe des Ergebnisses, liest das Ergebnis. Die insgesamt benötigte Zeit ist die Summe der Zeit der beiden Abfragen. Vereinfachen Sie den Prozess beispielsweise wie folgt:
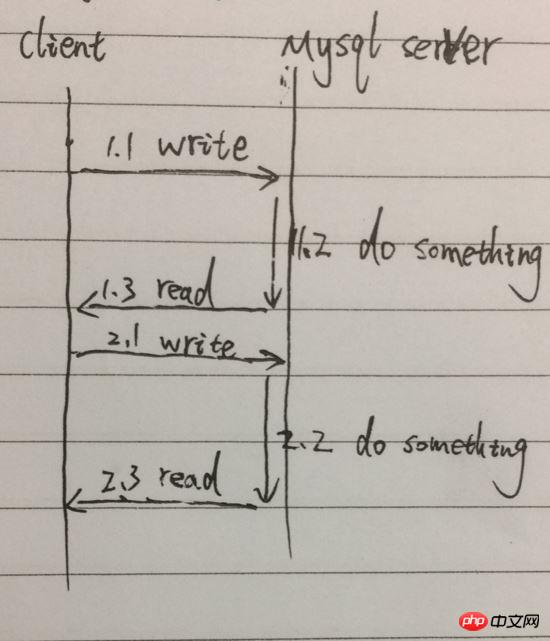
Als Beispiel sind die Aufrufe einer Abfrage [Funktion] von 1.1 bis 1.3. Zwei Abfragen erfordern die Serialisierung von 1.1 , 1.2, 1.3, 2.1, 2.2, 2.3, insbesondere 1.2 und 2.2, blockieren das Warten und der Prozess kann keine anderen Dinge tun.
Der Vorteil des synchronen Aufrufs besteht darin, dass er unserem intuitiven Denken entspricht und einfach aufzurufen und zu verarbeiten ist. Der Nachteil besteht darin, dass der Prozess blockiert ist und auf die Rückgabe des Ergebnisses wartet, was zusätzliche Laufzeit verursacht.
Kann die Wartezeit sinnvoll genutzt werden, um die Verarbeitungskapazität des Prozesses zu verbessern, wenn mehrere Abfrageanfragen vorliegen oder der Prozess andere Dinge zu erledigen hat?
Aufteilen
Jetzt teilen wir die Abfrage [Funktion] in Teile auf. Der Client kehrt sofort nach 1.1 zurück, der Client überspringt 1.2 und es gibt Daten in 1.3 die Daten nach Erreichen. Auf diese Weise wird der Prozess von der ursprünglichen 1.2-Stufe befreit und kann mehr Dinge tun, wie zum Beispiel ... eine weitere SQL-Abfrage initiieren [2.1]. Haben Sie den Prototyp einer gleichzeitigen Abfrage gesehen?
Gleichzeitige Abfrage
Im Vergleich zur synchronen Abfrage wird die nächste Abfrage initiiert, nachdem die vorherige Abfrage abgeschlossen ist. Die gleichzeitige Abfrage kann unmittelbar nach Initiierung der vorherigen Abfrageanforderung initiiert werden . Initiieren Sie die nächste Abfrageanforderung. Vereinfachen Sie den Prozess wie unten gezeigt:
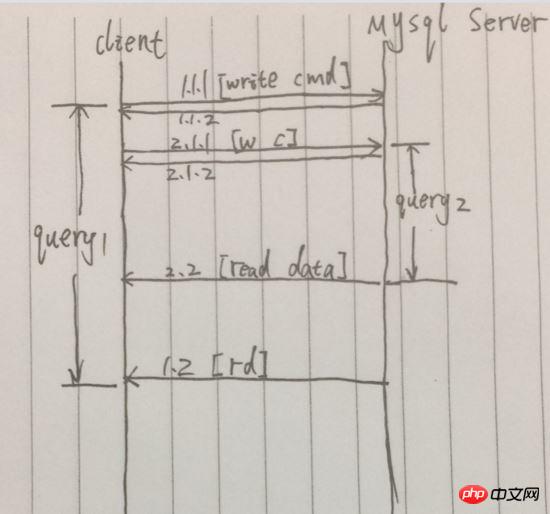
Beispiel: Nach erfolgreichem Senden der Anfrage in 1.1.1 wird [1.1.2] sofort zurückgegeben und das endgültige Abfrageergebnis ist zurückgegeben in Distant 1.2. Allerdings wurde zwischen 1.1.1 und 1.2 eine weitere Abfrageanforderung initiiert. Während dieses Zeitraums kamen zwei Abfrageanforderungen gleichzeitig vor 1.2 an, sodass der Gesamtzeitverbrauch der beiden Abfragen nur gleich war der ersten Abfrage.
Der Vorteil der gleichzeitigen Abfrage besteht darin, dass sie die Auslastungsrate des Prozesses verbessern, das Blockieren des Wartens auf die Verarbeitung der Abfrage durch den Server vermeiden und die Zeit mehrerer Abfragen verkürzen kann. Die Nachteile liegen aber auch auf der Hand. Um N gleichzeitige Abfragen zu initiieren, müssen N Datenbankverbindungen eingerichtet werden. Bei Anwendungen mit Datenbankverbindungspools kann diese Situation vermieden werden.
Degenerieren
Idealerweise möchten wir N Abfragen gleichzeitig ausführen, und der Gesamtzeitverbrauch entspricht der Abfrage mit der längsten Abfragezeit. Es ist aber auch möglich, dass gleichzeitige Abfragen zu synchronen Abfragen [degenerieren]. Was? Wenn im Beispielbild 1.2 vor 2.1.1 zurückgegeben wird, wird die gleichzeitige Abfrage zu [synchroner Abfrage] degenerieren, die Kosten sind jedoch höher als bei der synchronen Abfrage.
Multiplexing
Abfrage1 initiieren
Abfrage2 initiieren
-
Abfrage3 initiieren
......
Warten auf Abfrage1, Abfrage2, Abfrage3
-
Ergebnisse von Abfrage2 lesen
Ergebnisse von Abfrage1 lesen
Ergebnisse von Abfrage3 lesen
So Wie kann man warten und wissen, wann die Abfrageergebnisse zurückgegeben werden und welche Abfrageergebnisse zurückgegeben werden?
Bei jeder Abfrage IO lesen? Wenn es auf blockierende IOs stößt, wird es auf einem IO blockiert, und bei anderen IOs werden Ergebnisse zurückgegeben, die nicht verarbeitet werden können. Wenn es sich also um eine nicht blockierende E/A handelt, besteht kein Grund zur Sorge, dass eine der E/As blockiert wird. Dies ist zwar der Fall, führt jedoch zu kontinuierlichen Abfragen und Beurteilungen und verschwendet CPU-Ressourcen.
In dieser Situation können Sie Multiplexing verwenden, um mehrere IOs abzufragen.
PHP implementiert gleichzeitige Abfragen von MySQL
PHPs mysqli (mysqlnd-Treiber) bietet Multiplex-Polling-E/A (mysqli_poll) und asynchrone Abfragen (MYSQLI_ASYNC, mysqli_reap_async_query). Verwenden Sie diese beiden Funktionen, um Implementieren Sie gleichzeitige Abfragen, Beispielcode:
<?php
$sqls = array(
'SELECT * FROM `mz_table_1` LIMIT 1000,10',
'SELECT * FROM `mz_table_1` LIMIT 1010,10',
'SELECT * FROM `mz_table_1` LIMIT 1020,10',
'SELECT * FROM `mz_table_1` LIMIT 10000,10',
'SELECT * FROM `mz_table_2` LIMIT 1',
'SELECT * FROM `mz_table_2` LIMIT 5,1'
);
$links = [];
$tvs = microtime();
$tv = explode(' ', $tvs);
$start = $tv[1] * 1000 + (int)($tv[0] * 1000);
// 链接数据库,并发起异步查询
foreach ($sqls as $sql) {
$link = mysqli_connect('127.0.0.1', 'root', 'root', 'dbname', '3306');
$link->query($sql, MYSQLI_ASYNC); // 发起异步查询,立即返回
$links[$link->thread_id] = $link;
}
$llen = count($links);
$process = 0;
do {
$r_array = $e_array = $reject = $links;
// 多路复用轮询IO
if(!($ret = mysqli_poll($r_array, $e_array, $reject, 2))) {
continue;
}
// 读取有结果返回的查询,处理结果
foreach ($r_array as $link) {
if ($result = $link->reap_async_query()) {
print_r($result->fetch_row());
if (is_object($result))
mysqli_free_result($result);
} else {
}
// 操作完后,把当前数据链接从待轮询集合中删除
unset($links[$link->thread_id]);
$link->close();
$process++;
}
foreach ($e_array as $link) {
die;
}
foreach ($reject as $link) {
die;
}
}while($process < $llen);
$tvs = microtime();
$tv = explode(' ', $tvs);
$end = $tv[1] * 1000 + (int)($tv[0] * 1000);
echo $end - $start,PHP_EOL;mysqli_poll-Quellcode:
#ifndef PHP_WIN32
#define php_select(m, r, w, e, t) select(m, r, w, e, t)
#else
#include "win32/select.h"
#endif
/* {{{ mysqlnd_poll */
PHPAPI enum_func_status
mysqlnd_poll(MYSQLND **r_array, MYSQLND **e_array, MYSQLND ***dont_poll, long sec, long usec, int * desc_num)
{
struct timeval tv;
struct timeval *tv_p = NULL;
fd_set rfds, wfds, efds;
php_socket_t max_fd = 0;
int retval, sets = 0;
int set_count, max_set_count = 0;
DBG_ENTER("_mysqlnd_poll");
if (sec < 0 || usec < 0) {
php_error_docref(NULL, E_WARNING, "Negative values passed for sec and/or usec");
DBG_RETURN(FAIL);
}
FD_ZERO(&rfds);
FD_ZERO(&wfds);
FD_ZERO(&efds);
// 从所有mysqli链接中获取socket链接描述符
if (r_array != NULL) {
*dont_poll = mysqlnd_stream_array_check_for_readiness(r_array);
set_count = mysqlnd_stream_array_to_fd_set(r_array, &rfds, &max_fd);
if (set_count > max_set_count) {
max_set_count = set_count;
}
sets += set_count;
}
// 从所有mysqli链接中获取socket链接描述符
if (e_array != NULL) {
set_count = mysqlnd_stream_array_to_fd_set(e_array, &efds, &max_fd);
if (set_count > max_set_count) {
max_set_count = set_count;
}
sets += set_count;
}
if (!sets) {
php_error_docref(NULL, E_WARNING, *dont_poll ? "All arrays passed are clear":"No stream arrays were passed");
DBG_ERR_FMT(*dont_poll ? "All arrays passed are clear":"No stream arrays were passed");
DBG_RETURN(FAIL);
}
PHP_SAFE_MAX_FD(max_fd, max_set_count);
// select轮询阻塞时间
if (usec > 999999) {
tv.tv_sec = sec + (usec / 1000000);
tv.tv_usec = usec % 1000000;
} else {
tv.tv_sec = sec;
tv.tv_usec = usec;
}
tv_p = &tv;
// 轮询,等待多个IO可读,php_select是select的宏定义
retval = php_select(max_fd + 1, &rfds, &wfds, &efds, tv_p);
if (retval == -1) {
php_error_docref(NULL, E_WARNING, "unable to select [%d]: %s (max_fd=%d)",
errno, strerror(errno), max_fd);
DBG_RETURN(FAIL);
}
if (r_array != NULL) {
mysqlnd_stream_array_from_fd_set(r_array, &rfds);
}
if (e_array != NULL) {
mysqlnd_stream_array_from_fd_set(e_array, &efds);
}
// 返回可操作的IO数量
*desc_num = retval;
DBG_RETURN(PASS);
}Ergebnisse gleichzeitiger Abfrageoperationen
Um das zu sehen Effekt intuitiver, ich habe eine Tabelle mit einem Datenvolumen von 130 Millionen gefunden, die nicht für den Betrieb optimiert ist.
Gleichzeitige Abfrageergebnisse:

Synchrone Abfrageergebnisse:

Von Von dem Ergebnisse: Der Gesamtzeitverbrauch der synchronen Abfrage ist die Summe der Zeit aller Abfragen, und der Gesamtzeitverbrauch der gleichzeitigen Abfrage ist tatsächlich die Abfrage mit der längsten Zeit (die vierte Abfragezeit der synchronen Abfrage beträgt einige Sekunden). mit dem Gesamtzeitaufwand gleichzeitiger Abfragen) und die Abfragereihenfolge gleichzeitiger Abfragen und die Reihenfolge, in der die Ergebnisse eintreffen, sind unterschiedlich.
Vergleich mehrerer Abfragen mit kürzeren Abfragezeiten
Verwenden Sie mehrere SQL-Abfragen mit kürzeren Abfragezeiten zum Vergleich
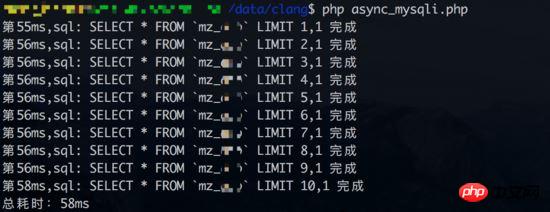
Testen Sie 1 der Ergebnisse gleichzeitiger Abfragen (Datenbank Linkzeit wird ebenfalls gezählt):
Synchrone Abfrageergebnisse (Datenbanklinkzeit wird ebenfalls gezählt):

Gleichzeitig Ergebnisse des Abfragetests 2 (die Datenbankverknüpfungszeit wird nicht gezählt):

Den Ergebnissen nach zu urteilen, hat Test 1 der gleichzeitigen Abfrage keinen Nutzen gebracht. Aus Sicht der synchronen Abfrage dauert jede Abfrage etwa 3-4 ms. Wenn die Datenbankverbindungszeit jedoch nicht in die Statistik einbezogen wird (synchrone Abfragen haben nur eine Datenbankverbindung), können die Vorteile gleichzeitiger Abfragen erneut zum Ausdruck kommen.
Fazit
Hier haben wir die Implementierung der gleichzeitigen Abfrage MySQL in PHP besprochen und anhand der experimentellen Ergebnisse intuitiv die Vor- und Nachteile der gleichzeitigen Abfrage verstanden. Die Zeit zum Aufbau einer Datenbankverbindung macht immer noch einen großen Teil einer optimierten SQL-Abfrage aus. #Es gibt keinen Verbindungspool, was ist Ihr Nutzen
Das obige ist der detaillierte Inhalt vonBeispiel für PHP-Parallelität zum Abfragen von MySQL (Bild). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- Alle Ausdruckssymbole in regulären Ausdrücken (Zusammenfassung)