
Heim >Backend-Entwicklung >PHP-Tutorial >Beispiel-Tutorial der PHP-Bibliothek für maschinelles Lernen php-ml
Beispiel-Tutorial der PHP-Bibliothek für maschinelles Lernen php-ml

- 零下一度Original
- 2018-05-15 15:45:096553Durchsuche
php-ml ist eine in PHP geschriebene Bibliothek für maschinelles Lernen. Obwohl wir wissen, dass Python oder C++ mehr Bibliotheken für maschinelles Lernen bieten, sind die meisten davon tatsächlich etwas kompliziert und die Konfiguration lässt viele Anfänger hoffnungslos erscheinen. Obwohl die Bibliothek für maschinelles Lernen php-ml nicht über besonders fortschrittliche Algorithmen verfügt, verfügt sie über die grundlegendsten Algorithmen für maschinelles Lernen, Klassifizierung und andere. Für unser kleines Unternehmen reicht es aus, einige einfache Datenanalysen, Vorhersagen usw. durchzuführen. Wir streben bei unseren Projekten nach Wirtschaftlichkeit, nicht nach übermäßiger Effizienz und Präzision. Einige Algorithmen und Bibliotheken sehen sehr leistungsfähig aus, aber wenn wir erwägen, schnell online zu gehen und unsere technischen Mitarbeiter keine Erfahrung mit maschinellem Lernen haben, werden komplexer Code und komplexe Konfigurationen unser Projekt tatsächlich in die Länge ziehen. Und wenn wir eine einfache Anwendung für maschinelles Lernen erstellen, sind die Lernkosten für das Studium komplexer Bibliotheken und Algorithmen offensichtlich etwas hoch. Können wir diese außerdem lösen, wenn das Projekt auf seltsame Probleme stößt? Was soll ich tun, wenn sich meine Bedürfnisse ändern? Ich glaube, jeder hat diese Erfahrung gemacht: Während der Arbeit meldete das Programm plötzlich einen Fehler, und ich konnte den Grund nicht herausfinden. Ich habe bei Google oder Baidu nur eine Frage gefunden, die die Bedingungen erfüllte vor Jahren, und dann keine Antwort. . . Daher ist es notwendig, die einfachste, effizienteste und kostengünstigste Methode zu wählen. Die Geschwindigkeit von PHP-ML ist nicht langsam (wechseln Sie schnell zu PHP7) und die Genauigkeit ist auch gut. Schließlich sind die Algorithmen dieselben und PHP basiert auf c. Was Bloggern am wenigsten gefällt, ist der Vergleich der Leistung und des Anwendungsbereichs zwischen Python, Java und PHP. Wenn Sie wirklich Leistung wollen, entwickeln Sie bitte in C. Wenn Sie den Anwendungsbereich wirklich verfolgen möchten, verwenden Sie bitte C oder sogar Assembly. . .
Wenn wir diese Bibliothek nutzen möchten, müssen wir sie zunächst herunterladen. Diese Bibliotheksdatei kann von Github heruntergeladen werden (https://github.com/php-ai/php-ml). Natürlich ist es empfehlenswerter, Composer zu verwenden, um die Bibliothek herunterzuladen und automatisch zu konfigurieren.
Nach dem Herunterladen können wir einen Blick auf die Dokumentation dieser Bibliothek werfen. Bei den Dokumenten handelt es sich um einige einfache Beispiele. Wir können selbst eine Datei erstellen und ausprobieren. Alle sind leicht zu verstehen. Als nächstes testen wir es anhand tatsächlicher Daten. DatensätzeEiner ist der Datensatz der Iris-Staubgefäße, der andere ist auf den Verlust von Aufzeichnungen zurückzuführen, daher weiß ich nicht, worum es bei den Daten geht. . .
Iris-Staubblattdaten haben drei verschiedene Kategorien:
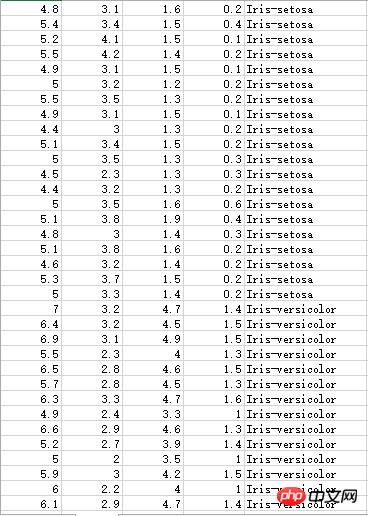
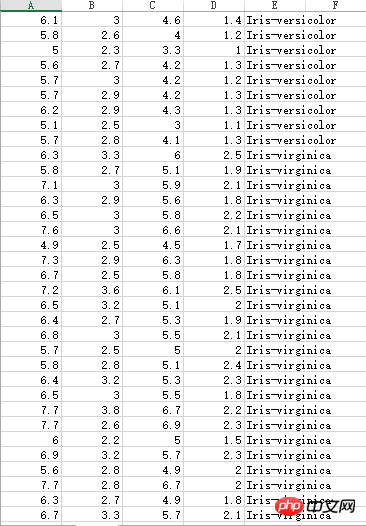
Unbekannter Datensatz, die Dezimalzahl Der Punkt ist als Komma markiert und muss daher während der Berechnung verarbeitet werden:

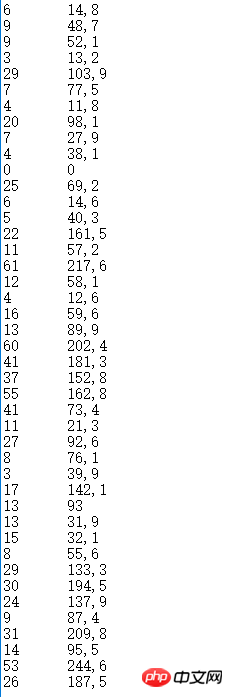
Wir verarbeiten zuerst den unbekannten Datensatz. Erstens lautet der Dateiname unseres unbekannten Datensatzes data.txt. Dieser Datensatz kann zunächst in ein x-y-Liniendiagramm gezeichnet werden. Daher zeichnen wir zunächst die Originaldaten in ein Liniendiagramm ein. Da die x-Achse relativ lang ist, müssen wir nur ihre grobe Form sehen:
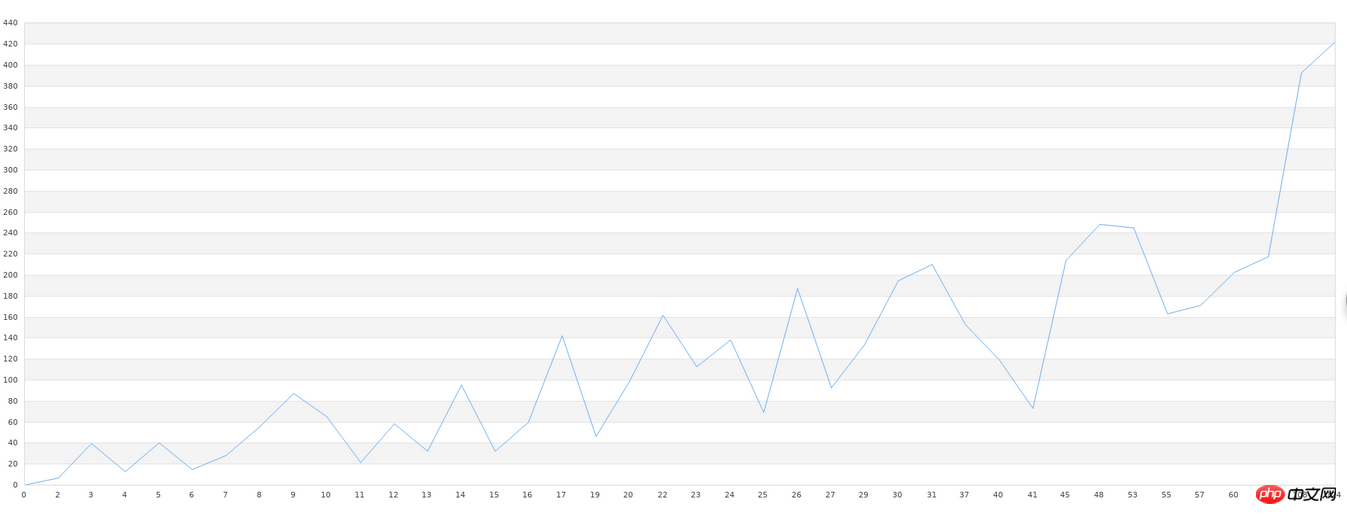
Zeichnung verwendet die jpgraph-Bibliothek von PHP, der Code ist wie folgt:
<?php
include_once './src/jpgraph.php';
include_once './src/jpgraph_line.php';
$g = new Graph(1920,1080);//jpgraph的绘制操作
$g->SetScale("textint");
$g->title->Set('data');
//文件的处理
$file = fopen('data.txt','r');
$labels = array();
while(!feof($file)){
$data = explode(' ',fgets($file));
$data[1] = str_replace(',','.',$data[1]);//数据处理,将数据中的逗号修正为小数点
$labels[(int)$data[0]] = (float)$data[1];//这里将数据以键值的方式存入数组,方便我们根据键来排序
}
ksort($labels);//按键的大小排序
$x = array();//x轴的表示数据
$y = array();//y轴的表示数据
foreach($labels as $key=>$value){
array_push($x,$key);
array_push($y,$value);
}
$linePlot = new LinePlot($y);
$g->xaxis->SetTickLabels($x);
$linePlot->SetLegend('data');
$g->Add($linePlot);
$g->Stroke();Nachdem wir nun dieses Originalbild zum Vergleich haben, werden wir es als nächstes untersuchen. Wir verwenden LeastSquars in PHP-ML zum Lernen. Die Ausgabe unseres Tests muss in einer Datei gespeichert werden, damit wir ein Vergleichsdiagramm erstellen können. Der Lerncode lautet wie folgt:
<?php
require 'vendor/autoload.php';
use Phpml\Regression\LeastSquares;
use Phpml\ModelManager;
$file = fopen('data.txt','r');
$samples = array();
$labels = array();
$i = 0;
while(!feof($file)){
$data = explode(' ',fgets($file));
$samples[$i][0] = (int)$data[0];
$data[1] = str_replace(',','.',$data[1]);
$labels[$i] = (float)$data[1];
$i ++;
}
fclose($file);
$regression = new LeastSquares();
$regression->train($samples,$labels);
//这个a数组是根据我们对原数据处理后的x值给出的,做测试用。
$a = [0,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,20,22,23,24,25,26,27,29,30,31,37,40,41,45,48,53,55,57,60,61,108,124];
for($i = 0; $i < count($a); $i ++){
file_put_contents("putput.txt",($regression->predict([$a[$i]]))."\n",FILE_APPEND); //以追加的方式存入文件
}Danach lesen wir die in der Datei gespeicherten Daten aus, zeichnen ein Diagramm und fügen zunächst das endgültige Rendering ein:
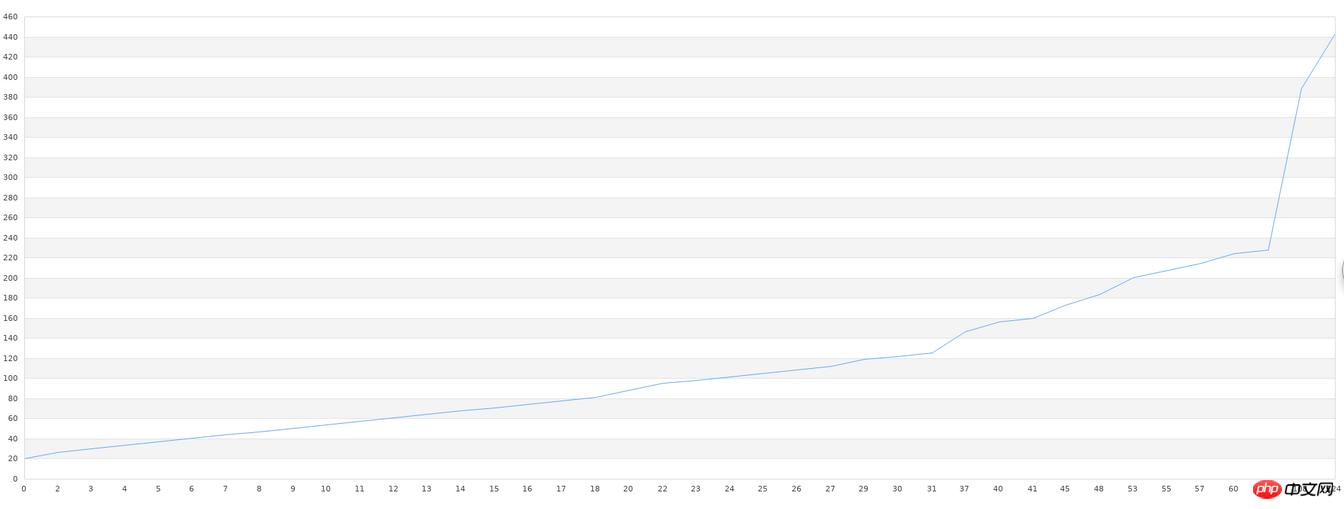
Der Code lautet wie folgt:
<?php
include_once './src/jpgraph.php';
include_once './src/jpgraph_line.php';
$g = new Graph(1920,1080);
$g->SetScale("textint");
$g->title->Set('data');
$file = fopen('putput.txt','r');
$y = array();
$i = 0;
while(!feof($file)){
$y[$i] = (float)(fgets($file));
$i ++;
}
$x = [0,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,20,22,23,24,25,26,27,29,30,31,37,40,41,45,48,53,55,57,60,61,108,124];
$linePlot = new LinePlot($y);
$g->xaxis->SetTickLabels($x);
$linePlot->SetLegend('data');
$g->Add($linePlot);
$g->Stroke();Es lässt sich feststellen, dass die Grafikdiskrepanz immer noch relativ groß ist, insbesondere in den Teilen mit stärker gezackten Grafiken . Allerdings sind es immerhin 40 Datensätze, und wir können sehen, dass die allgemeinen grafischen Trends konsistent sind. Wenn allgemeine Bibliotheken diese Art des Lernens durchführen, ist die Genauigkeit sehr gering, wenn die Datenmenge gering ist. Um eine relativ hohe Genauigkeit zu erreichen, ist eine große Datenmenge erforderlich, und zwar mehr als 10.000 Daten. Wenn dieser Datenbedarf nicht erfüllt werden kann, ist jede von uns genutzte Bibliothek vergebens. Daher liegt die eigentliche Schwierigkeit in der Praxis des maschinellen Lernens nicht in technischen Problemen wie geringer Genauigkeit und komplexer Konfiguration, sondern in unzureichendem Datenvolumen oder zu geringer Qualität (zu viele nutzlose Daten in einem Datensatz). Vor dem maschinellen Lernen ist auch eine Vorverarbeitung der Daten erforderlich.
接下来,我们来对花蕊数据进行测试。一共三种分类,由于我们下载到的是csv数据,所以我们可以使用php-ml官方提供的操作csv文件的方法。而这里是一个分类问题,所以我们选择库提供的SVC算法来进行分类。我们把花蕊数据的文件名定为Iris.csv,代码如下:
<?php require 'vendor/autoload.php'; use Phpml\Classification\SVC; use Phpml\SupportVectorMachine\Kernel; use Phpml\Dataset\CsvDataset; $dataset = new CsvDataset('Iris.csv' , 4, false); $classifier = new SVC(Kernel::LINEAR,$cost = 1000); $classifier->train($dataset->getSamples(),$dataset->getTargets()); echo $classifier->predict([$argv[1],$argv[2],$argv[3],$argv[4]]);//$argv是命令行参数,调试这种程序使用命令行较方便
是不是很简单?短短12行代码就搞定了。接下来,我们来测试一下。根据我们上面贴出的图,当我们输入5 3.3 1.4 0.2的时候,输出应该是Iris-setosa。我们看一下:

看,至少我们输入一个原来就有的数据,得到了正确的结果。但是,我们输入原数据集中没有的数据呢?我们来测试两组:
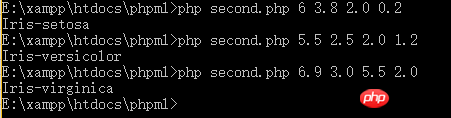
由我们之前贴出的两张图的数据看,我们输入的数据在数据集中并不存在,但分类按照我们初步的观察来看,是合理的。
所以,这个机器学习库对于大多数的人来说,都是够用的。而大多数鄙视这个库鄙视那个库,大谈性能的人,基本上也不是什么大牛。真正的大牛已经忙着捞钱去了,或者正在做学术研究等等。我们更多的应该是掌握算法,了解其中的道理和玄机,而不是夸夸其谈。当然,这个库并不建议用在大型项目上,只推荐小型项目或者个人项目等。
jpgraph只依赖GD库,所以下载引用之后就可以使用,大量的代码都放在了绘制图形和初期的数据处理上。由于库的出色封装,学习代码并不复杂。需要所有代码或者测试数据集的小伙伴可以留言或者私信等,我提供完整的代码,解压即用
Das obige ist der detaillierte Inhalt vonBeispiel-Tutorial der PHP-Bibliothek für maschinelles Lernen php-ml. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- Alle Ausdruckssymbole in regulären Ausdrücken (Zusammenfassung)