
Heim >Backend-Entwicklung >Python-Tutorial >Python: So führen Sie effiziente Operationen mit Pandas durch
Python: So führen Sie effiziente Operationen mit Pandas durch
- 巴扎黑Original
- 2017-07-19 13:38:561353Durchsuche
In diesem Artikel wird ein Vergleichstest zur Betriebseffizienz von Pandas durchgeführt, um herauszufinden, welche Methoden die Betriebseffizienz verbessern können.
Die Testumgebung ist wie folgt:
Windows 7, 64-Bit
Python 3.5
- Erforderlich Es ist zu beachten, dass unterschiedliche Systeme, unterschiedliche Computerkonfigurationen und unterschiedliche Softwareumgebungen zu unterschiedlichen Betriebsergebnissen führen können. Selbst wenn es sich um denselben Computer handelt, sind die Ergebnisse nicht bei jeder Ausführung genau gleich. 1 Testinhalt
- Der Testinhalt besteht darin, drei Methoden zur Berechnung eines einfachen Operationsprozesses zu verwenden, nämlich a*a+b*b. Die drei Methoden sind:
- Pythons for-Schleife
Numpy's ndarray
- Erstellen Sie zunächst einen DataFrame. Die Größe der Datenmenge, dh die Anzahl der Zeilen des DataFrame, beträgt 10, 100, 1000, .... , bis 10.000.000 (eine Million). Verwenden Sie dann im Jupyter-Notebook die folgenden Codes, um die Laufzeit verschiedener Methoden zu testen bzw. zu überprüfen und einen Vergleich durchzuführen.
- Operation ausführen, a*a + b*b
Methode 1: for-Schleife
import pandas as pdimport numpy as np# 100分别用 10,100,...,10,000,000来替换运行list_a = list(range(100))# 200分别用 20,200,...,20,000,000来替换运行list_b = list(range(100,200))
print(len(list_a))
print(len(list_b))
df = pd.DataFrame({'a':list_a, 'b':list_b})
print('数据维度为:{}'.format(df.shape))
print(len(df))
print(df.head())
100 100 数据维度为:(100, 2) 100 a b 0 0 100 1 1 101 2 2 102 3 3 103 4 4 104
- Methode 2: Serie
%%timeit# 当DataFrame的行数大于等于1000000时,请用 %%time 命令for i in range(len(df)): df['a'][i]*df['a'][i]+df['b'][i]*df['b'][i]
100 loops, best of 3: 12.8 ms per loop
Methode 3: ndarray
type(df['a'])
pandas.core.series.Series
%%timeit df['a']*df['a']+df['b']*df['b']
The slowest run took 5.41 times longer than the fastest. This could mean that an intermediate result is being cached. 1000 loops, best of 3: 669 µs per loop2 Testergebnisse
- Die Laufergebnisse lauten wie folgt:
type(df['a'].values)Der Unterschied zwischen Series und Ndarray ist nicht so groß.
numpy.ndarray
%%timeit df['a'].values*df['a'].values+df['b'].values*df['b'].valuesPS: Bei 10 Millionen Zeilen dauert die Ausführung der for-Schleife sehr lange. Wenn Sie sie testen möchten, müssen Sie auf
10000 loops, best of 3: 34.2 µs per loop%%time Befehl (nur einmal testen). Das folgende Diagramm vergleicht die Leistung zwischen Series und Ndarray.
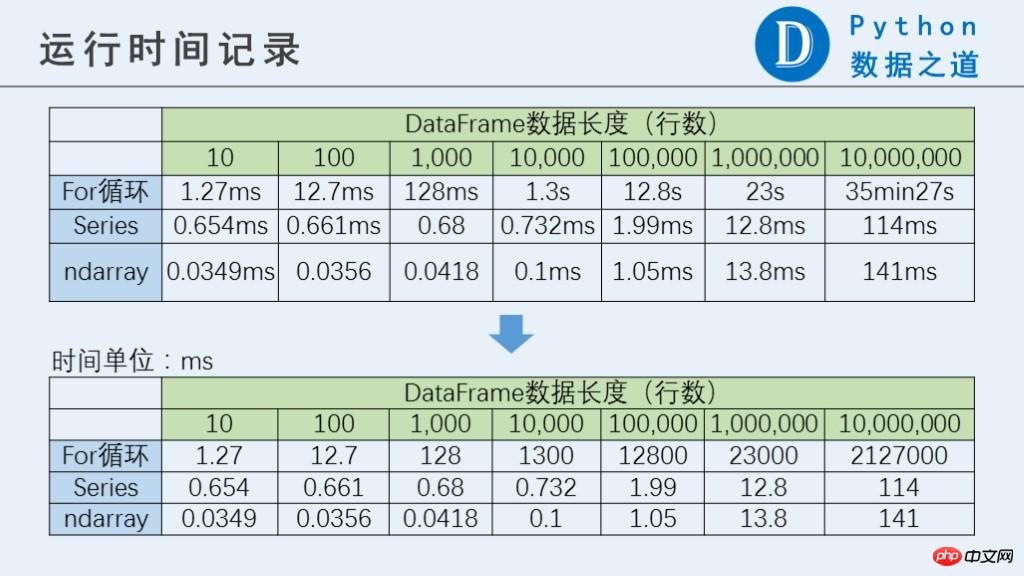
Unter normalen Umständen empfehle ich persönlich, wenn möglich die for-Schleife zu verwenden. Wenn die Anzahl nicht besonders groß ist, wird empfohlen, ndarray
(d. h. df['col '].values) Um Berechnungen durchzuführen, ist die Betriebseffizienz relativ besser.
Das obige ist der detaillierte Inhalt vonPython: So führen Sie effiziente Operationen mit Pandas durch. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
Stellungnahme:
Der Inhalt dieses Artikels wird freiwillig von Internetnutzern beigesteuert und das Urheberrecht liegt beim ursprünglichen Autor. Diese Website übernimmt keine entsprechende rechtliche Verantwortung. Wenn Sie Inhalte finden, bei denen der Verdacht eines Plagiats oder einer Rechtsverletzung besteht, wenden Sie sich bitte an admin@php.cn
Vorheriger Artikel:Zusammenfassung des grundlegenden Python-Lernens (8)Nächster Artikel:Zusammenfassung des grundlegenden Python-Lernens (8)