
Heim >Backend-Entwicklung >Python-Tutorial >Eine kurze Einführung in die Verwendung von Beautifulsoup und Selen
Eine kurze Einführung in die Verwendung von Beautifulsoup und Selen
- 巴扎黑Original
- 2017-07-20 09:42:522194Durchsuche
Einfache Verwendung von Beautifulsoup und Selenium
Überprüfung der Anforderungsbibliothek
Ich habe es schon lange nicht mehr verwendetrequests, da ich später einen einfachen Crawler schreiben werde, also ich Ich werde einfach eine kleine Rezension schreiben.
import requests r = requests.get('https://api.github.com/user', auth=('haiyu19931121@163.com', 'Shy18137803170'))print(r.status_code) # 状态码200print(r.json()) # 返回json格式print(r.text) # 返回文本print(r.headers) # 头信息print(r.encoding) # 编码方式,一般utf-8# 当写入文件比较大时,避免内存耗尽,可以一次写指定的字节数或者一行。# 一次读一行,chunk_size=512为默认值for chunk in r.iter_lines():print(chunk)# 一次读取一块,大小为512for chunk in r.iter_content(chunk_size=512):print(chunk)
Beachten Sie, dass iter_lines und iter_content Byte-Daten zurückgeben. Wenn Sie eine Datei schreiben möchten, sei es Text oder Bild, müssen Sie beginnen mit wb Weg zum Öffnen.
Verwendung von Beautifulsoup
Kommen wir zum Punkt. Ich habe schon lange von dieser berühmten Bibliothek gehört, obwohl es in der Vergangenheit nicht schwierig war, reguläre Ausdrücke zu schreiben , manchmal wäre die Übereinstimmung ungenau. Verwenden Sie Beautifulsoup, um Daten aus HTML-Tags genau zu extrahieren. Obwohl es etwas langsam ist, ist es einfach und leicht zu bedienen.
from bs4 import BeautifulSoup html_doc = """<html><head><title>The Dormouse's story</title></head><body><p class="title"><b>The Dormouse's story</b></p><p class="story">Once upon a time there were three little sisters; and their names were<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;and they lived at the bottom of a well.</p><p class="story">...</p>"""# 就注意一点,第二个参数指定解析器,必须填上,不然会有警告。推荐使用lxmlsoup = BeautifulSoup(html_doc, 'lxml')
Befolgen Sie den obigen Code und sehen Sie sich unten einige einfache Vorgänge an. Durch die Nutzung des Verhaltens von Punktattributen werden die ersten gefundenen Daten abgerufen, die die Bedingungen erfüllen. Es ist die Abkürzung für find Methode.
soup.a soup.find('p')
Die beiden obigen Sätze sind äquivalent.
# soup.body是一个Tag对象。是body标签中所有html代码print(soup.body)
6c04bd5ca3fcae76e30b72ad730ca86d 76541fb5e7b0d5abaf17f6416b10757ba4b561c25d9afb9ac8dc4d70affff419The Dormouse's story0d36329ec37a2cc24d42c7229b69747a94b3e26ee717c64999d7867364b1b4a3 a0d1e8d16fe601bf29354e6acb221fcbOnce upon a time there were three little sisters; and their names were 31602ad08f2e88060105421a6fd98432Elsie5db79b134e9f6b82c0b36e0489ee08ed, 7a2353bc01007f1e0b12a80523342380Lacie5db79b134e9f6b82c0b36e0489ee08ed and de05147b7e6ab3a313271cf7987ced2eTillie5db79b134e9f6b82c0b36e0489ee08ed; and they lived at the bottom of a well.94b3e26ee717c64999d7867364b1b4a3 a0d1e8d16fe601bf29354e6acb221fcb...94b3e26ee717c64999d7867364b1b4a3 36cc49f0c466276486e50c850b7e4956
# 获取body里所有文本,不含标签print(soup.body.text)# 等同于下面的写法soup.body.get_text()# 还可以这样写,strings是所有文本的生成器for string in soup.body.strings:print(string, end='')
The Dormouse's story Once upon a time there were three little sisters; and their names were Elsie, Lacie and Tillie; and they lived at the bottom of a well. ...
# 获得该标签里的文本。print(soup.title.string)
The Dormouse's story
# Tag对象的get方法可以根据属性的名称获得属性的值,此句表示得到第一个p标签里class属性的值print(soup.p.get('class'))# 和下面的写法等同print(soup.p['class'])
['title']
# 查看a标签的所有属性,以字典形式给出print(soup.a.attrs)
{'href': 'http://example.com/elsie', 'class': ['sister'], 'id': 'link1'}
# 标签的名称soup.title.name
title
find_all
Die am häufigsten verwendete Methode ist definitiv die find_all / find-Methode findet alle Daten, die die Bedingungen erfüllen, und wird als Liste zurückgegeben. Letzteres sind die ersten Daten in dieser Liste. find_all verfügt über einen limit-Parameter, der die Länge der Liste begrenzt (d. h. die Anzahl der Daten, die die Suchkriterien erfüllen). Wenn limit=1 tatsächlich zur find-Methode wird.
find_all hat auch Abkürzungen.
soup.find_all('a', id='link1') soup('a', id='link1')
Die beiden oben genannten Schreibweisen sind gleichwertig, und die zweite Schreibweise ist eine Abkürzung.
find_all(self, name=None, attrs={}, recursive=True, text=None,
limit=None, **kwargs)
Name
name ist das Tag, nach dem Sie suchen möchten. Im Folgenden finden Sie beispielsweise alle p-Tags. Sie können nicht nur Zeichenfolgen eingeben, sondern auch reguläre Ausdrücke, Listen, Funktionen und True übergeben. Wenn
# 传入字符串soup.find_all('p')# 传入正则表达式import re# 必须以b开头for tag in soup.find_all(re.compile("^b")):print(tag.name)# body# b# 含有t就行for tag in soup.find_all(re.compile("t")):print(tag.name)# html# title# 传入列表表示,一次查找多个标签soup.find_all(["a", "b"])# [<b>The Dormouse's story</b>,# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>] in True übergeben wird, gibt es keine Begrenzung und alles wird durchsucht.
rekursiv
Beim Aufrufen der find_all()-Methode des Tags ruft Beautiful Soup alle Nachkommenknoten des aktuellen Tags ab. Wenn Sie nur nach den direkten untergeordneten Knoten des Tags suchen möchten, können Sie Folgendes tun: kann den Parameter recursive=False verwenden.
# title不是html的直接子节点,但是会检索其下所有子孙节点soup.html.find_all("title")# [<title>The Dormouse's story</title>]# 参数设置为False,只会找直接子节点soup.html.find_all("title", recursive=False)# []# title就是head的直接子节点,所以这个参数此时无影响a = soup.head.find_all("title", recursive=False)# [<title name="good">The Dormouse's story</title>]Schlüsselwort und Attribute
Verwenden Sie ein Schlüsselwort und fügen Sie eine oder mehrere qualifizierende Bedingungen hinzu, um den Suchbereich einzugrenzen.
# 查看所有id为link1的p标签soup.find_all('a', id='link1')
Wenn Sie nach Klasse suchen, hat Python diese aufgrund des Schlüsselworts „class“ bereits verwendet. Sie können class_ verwenden, keine Schlüsselwörter angeben oder attrs verwenden, um das Wörterbuch auszufüllen.
soup.find_all('p', class_='story')
soup.find_all('p', 'story')
soup.find_all('p', attrs={"class": "story"})Die oben genannten drei Methoden sind gleichwertig. class_Kann Zeichenfolgen, reguläre Ausdrücke, Funktionen und True akzeptieren.
Text
Suche nach Textwert, es scheint, dass die Verwendung des String-Parameters auch das gleiche Ergebnis liefert.
a = soup.find_all(text='Elsie')# 或者,4.4以上版本请使用texta = soup.find_all(string='Elsie')
Der Textparameter kann auch Zeichenfolgen, reguläre Ausdrücke, True und Listen akzeptieren.
CSS-Selektor
Sie können auch den CSS-Selektor verwenden. Verwenden Sie einfach die Select-Methode. Select gibt immer eine Liste zurück.
Listen Sie mehrere gängige Vorgänge auf.
# 所有div标签soup.select('div')# 所有id为username的元素soup.select('.username')# 所有class为story的元素soup.select('#story')# 所有div元素之内的span元素,中间可以有其他元素soup.select('div span')# 所有div元素之内的span元素,中间没有其他元素soup.select('div > span')# 所有具有一个id属性的input标签,id的值无所谓soup.select('input[id]')# 所有具有一个id属性且值为user的input标签soup.select('input[id="user"]')# 搜索多个,class为link1或者link2的元素都符合soup.select("#link1, #link2")Ein kleines Crawler-Beispiel
Das Obige stellt die grundlegende Verwendung von Anfragen und beautifulsoup4 vor. Mit diesen können Sie bereits einige einfache Crawler schreiben. Kommen Sie und probieren Sie es aus.
Dieses Beispiel stammt aus „Get Started Quickly with Python Programming – Automate Cumbersome Work“ [US] AI Sweigart
Dieser Crawler lädt Bilder stapelweise vom XKCD Comics Network herunter . Sie können die Anzahl der herunterzuladenden Seiten angeben.
import osimport requestsfrom bs4 import BeautifulSoup# exist_ok=True,若文件夹已经存在也不会报错os.makedirs('xkcd')
url = 'https://xkcd.com/'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/57.0.2987.98 Safari/537.36'}def save_img(img_url, limit=1):
r = requests.get(img_url, headers=headers)
soup = BeautifulSoup(r.text, 'lxml')try:
img = 'https:' + soup.find('div', id='comic').img.get('src')except AttributeError:print('Image Not Found')else:print('Downloading', img)
response = requests.get(img, headers=headers)with open(os.path.join('xkcd', os.path.basename(img)), 'wb') as f:for chunk in response.iter_content(chunk_size=1024*1024):
f.write(chunk)# 每次下载一张图片,就减1limit -= 1# 找到上一张图片的网址if limit > 0:try:
prev = 'https://xkcd.com' + soup.find('a', rel='prev').get('href')except AttributeError:print('Link Not Exist')else:
save_img(prev, limit)if __name__ == '__main__':
save_img(url, limit=20)print('Done!')Downloading Downloading Downloading Downloading Downloading Downloading Downloading Downloading Downloading ... Done!
Multithread-Download
Die Geschwindigkeit von Single-Thread ist etwas langsam, zum Beispiel kann Multi-Threading verwendet werden, weil Wenn wir prev erhalten, ist es sehr regelmäßig, die URL jeder Webseite zu kennen. Es geht so. Nur die letzte Zahl ist unterschiedlich, sodass wir problemlos range zum Durchqueren verwenden können.
import osimport threadingimport requestsfrom bs4 import BeautifulSoup
os.makedirs('xkcd')
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/57.0.2987.98 Safari/537.36'}def download_imgs(start, end):for url_num in range(start, end):
img_url = 'https://xkcd.com/' + str(url_num)
r = requests.get(img_url, headers=headers)
soup = BeautifulSoup(r.text, 'lxml')try:
img = 'https:' + soup.find('div', id='comic').img.get('src')except AttributeError:print('Image Not Found')else:print('Downloading', img)
response = requests.get(img, headers=headers)with open(os.path.join('xkcd', os.path.basename(img)), 'wb') as f:for chunk in response.iter_content(chunk_size=1024 * 1024):
f.write(chunk)if __name__ == '__main__':# 下载从1到30,每个线程下载10个threads = []for i in range(1, 30, 10):
thread_obj = threading.Thread(target=download_imgs, args=(i, i + 10))
threads.append(thread_obj)
thread_obj.start()# 阻塞,等待线程执行结束都会等待for thread in threads:
thread.join()# 所有线程下载完毕,才打印print('Done!')来看下结果吧。
初步了解selenium
selenium用来作自动化测试。使用前需要下载驱动,我只下载了Firefox和Chrome的。网上随便一搜就能下载到了。接下来将下载下来的文件其复制到将安装目录下,比如Firefox,将对应的驱动程序放到C:\Program Files (x86)\Mozilla Firefox,并将这个路径添加到环境变量中,同理Chrome的驱动程序放到C:\Program Files (x86)\Google\Chrome\Application并将该路径添加到环境变量。最后重启IDE开始使用吧。
模拟百度搜索
下面这个例子会打开Chrome浏览器,访问百度首页,模拟输入The Zen of Python,随后点击百度一下,当然也可以用回车代替。Keys下是一些不能用字符串表示的键,比如方向键、Tab、Enter、Esc、F1~F12、Backspace等。然后等待3秒,页面跳转到知乎首页,接着返回到百度,最后退出(关闭)浏览器。
from selenium import webdriverfrom selenium.webdriver.common.keys import Keysimport time browser = webdriver.Chrome()# Chrome打开百度首页browser.get('https://www.baidu.com/')# 找到输入区域input_area = browser.find_element_by_id('kw')# 区域内填写内容input_area.send_keys('The Zen of Python')# 找到"百度一下"search = browser.find_element_by_id('su')# 点击search.click()# 或者按下回车# input_area.send_keys('The Zen of Python', Keys.ENTER)time.sleep(3) browser.get('https://www.zhihu.com/') time.sleep(2)# 返回到百度搜索browser.back() time.sleep(2)# 退出浏览器browser.quit()
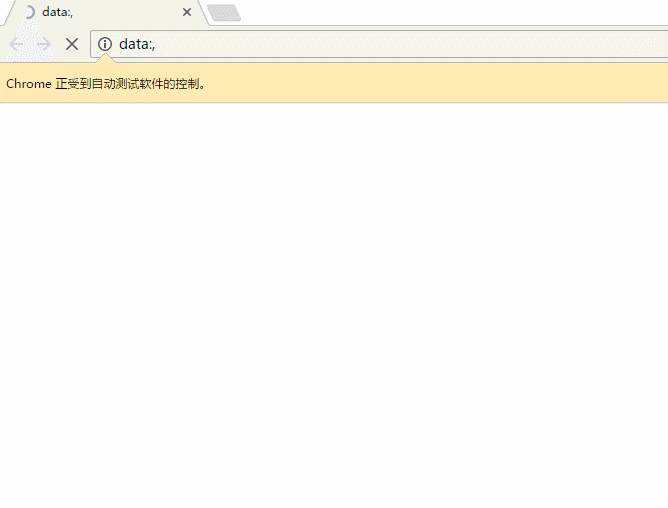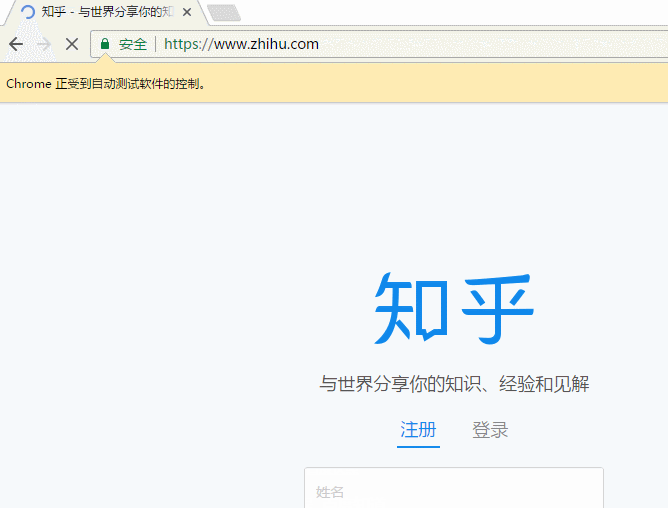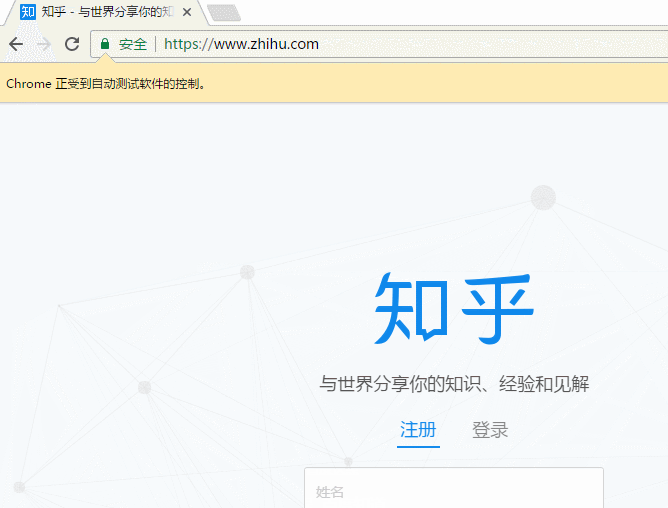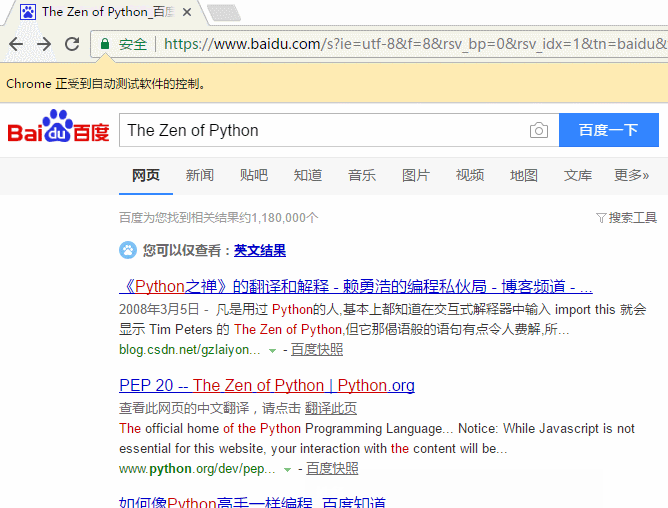
send_keys模拟输入内容。可以使用element的clear()方法清空输入。一些其他模拟点击浏览器按钮的方法如下
browser.back() # 返回按钮browser.forward() # 前进按钮browser.refresh() # 刷新按钮browser.close() # 关闭当前窗口browser.quit() # 退出浏览器
查找方法
以下列举常用的查找Element的方法。
| 方法名 | 返回的WebElement |
|---|---|
| find_element_by_id(id) | 匹配id属性值的元素 |
| find_element_by_name(name) | 匹配name属性值的元素 |
| find_element_by_class_name(name) | 匹配CSS的class值的元素 |
| find_element_by_tag_name(tag) | 匹配标签名的元素,如div |
| find_element_by_css_selector(selector) | 匹配CSS选择器 |
| find_element_by_xpath(xpath) | 匹配xpath |
| find_element_by_link_text(text) | 完全匹配提供的text的a标签 |
| find_element_by_partial_link_text(text) | 提供的text可以是a标签中文本中的一部分 |
登录CSDN
以下代码可以模拟输入账号密码,点击登录。整个过程还是很快的。
browser = webdriver.Chrome() browser.get('https://passport.csdn.net/account/login') browser.find_element_by_id('username').send_keys('haiyu19931121@163.com') browser.find_element_by_id('password').send_keys('**********') browser.find_element_by_class_name('logging').click()
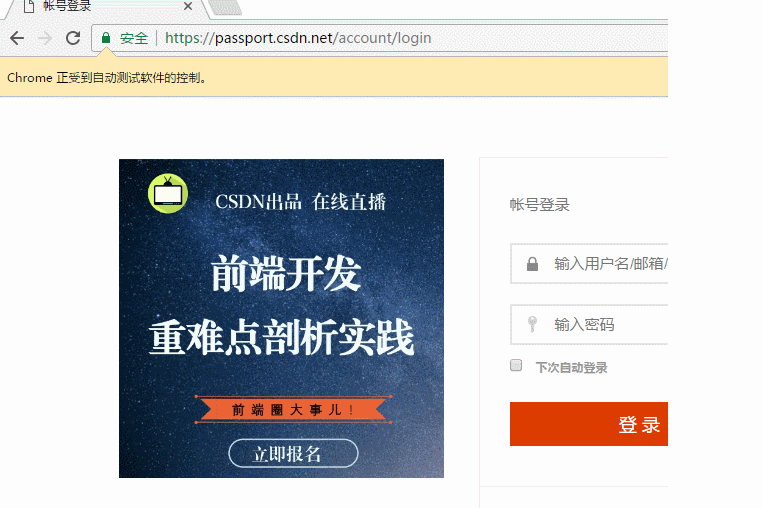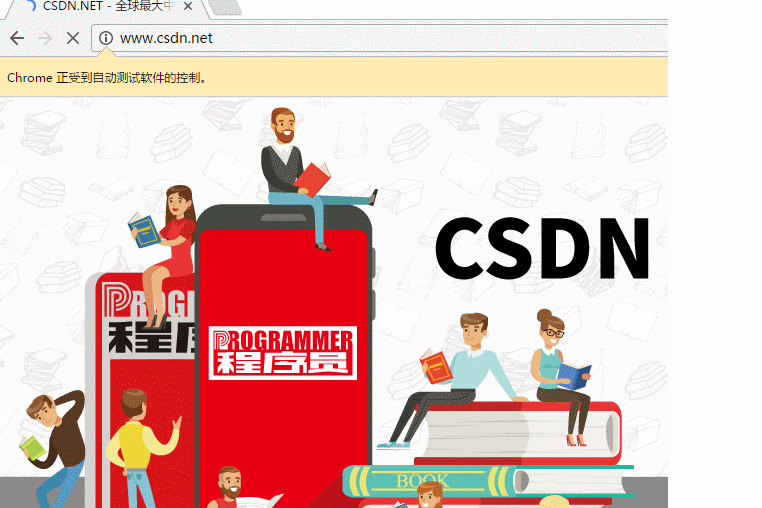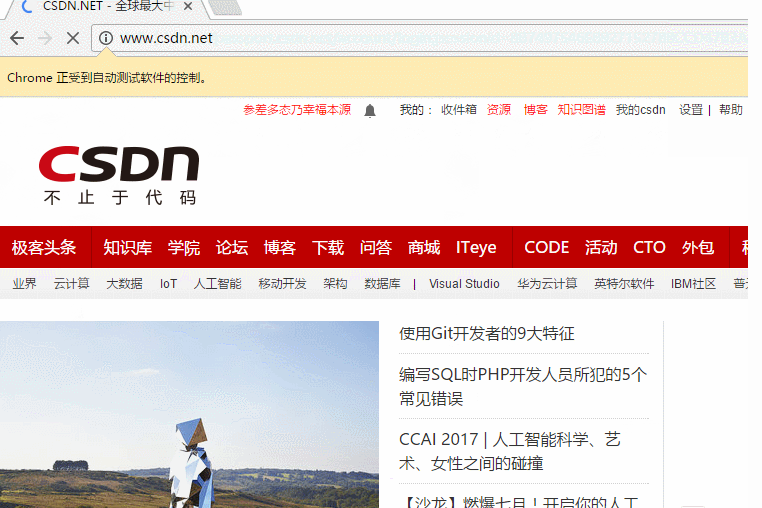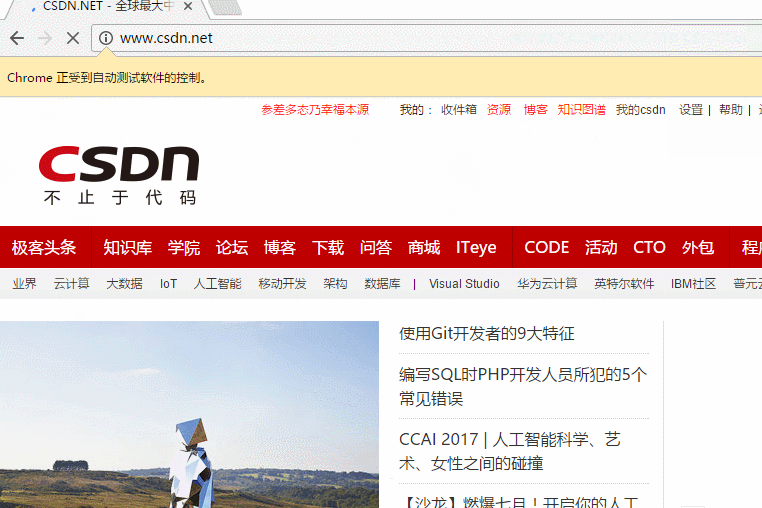
以上差不多都是API的罗列,其中有自己的理解,也有照搬官方文档的。
by @sunhaiyu
2017.7.13
Das obige ist der detaillierte Inhalt vonEine kurze Einführung in die Verwendung von Beautifulsoup und Selen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!