
Heim >Java >javaLernprogramm >Zusammenfassung der JAVA-Sammlungsklassen
Zusammenfassung der JAVA-Sammlungsklassen
- 巴扎黑Original
- 2017-07-20 13:17:111526Durchsuche
1. Sammlungen und Arrays
Arrays (können grundlegende Datentypen speichern) sind ein Container zum Speichern von Objekten, aber die Länge des Arrays ist festgelegt und eignet sich nicht dafür Anzahl der Objekte. Wird verwendet, wenn unbekannt.
Sammlungen (die nur Objekte speichern können und deren Objekttypen unterschiedlich sein können) haben eine variable Länge und können in den meisten Situationen verwendet werden.
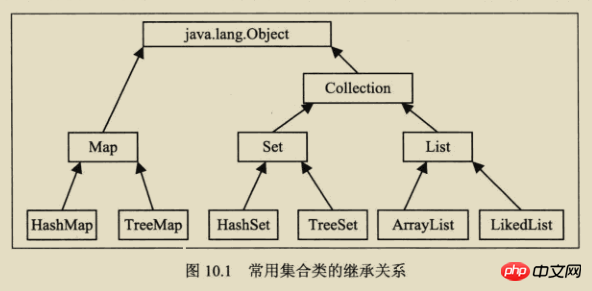
2. Hierarchische Beziehung
Wie in der Abbildung gezeigt: In der Abbildung ist der durchgezogene Linienrand die Implementierungsklasse, der Polylinienrand die abstrakte Klasse und Der gepunktete Rand ist Es ist die Schnittstelle
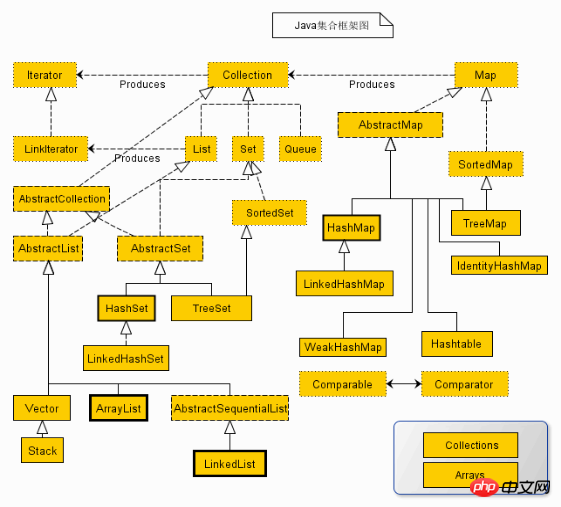
Collection-Schnittstelle ist die Stammschnittstelle der Collection-Klasse ist keine direkte Schnittstelle für diese Schnittstelle in der Java-Implementierungsklasse. Aber es wurde geerbt, um zwei Schnittstellen zu erzeugen, nämlich Set und List. Das Set darf keine doppelten Elemente enthalten. Eine Liste ist eine geordnete Sammlung, die wiederholte Elemente enthalten kann und den Zugriff über einen Index ermöglicht.
Map ist eine weitere Schnittstelle im Java.util-Paket. Sie hat nichts mit der Collection-Schnittstelle zu tun und ist unabhängig voneinander, aber beide sind Teil der Collection-Klasse. Die Karte enthält Schlüssel-Wert-Paare. Die Karte darf keine doppelten Schlüssel enthalten, sie kann jedoch denselben Wert enthalten.
Iterator, alle Sammlungsklassen implementieren die Iterator-Schnittstelle, eine Schnittstelle zum Durchlaufen von Elementen in einer Sammlung. Sie umfasst hauptsächlich die folgenden drei Methoden:
1. Gibt es eine andere Methode? ein Element.
2.next() gibt das nächste Element zurück.
3.remove() löscht das aktuelle Element.
3. Einführung in mehrere wichtige Schnittstellen und Klassen
1. Liste (geordnet, wiederholbar)
Die in der Liste gespeicherten Objekte sind geordnet, und das ist es auch Auch die Liste ist wiederholbar und konzentriert sich auf Indizes. Sie verfügt über eine Reihe von Methoden im Zusammenhang mit Indizes und verfügt über eine schnelle Abfragegeschwindigkeit. Denn wenn Daten in die Listensammlung eingefügt oder gelöscht werden, werden nachfolgende Daten verschoben, und alle Einfügungen und Löschungen von Daten erfolgen langsam.
2. Satz (ungeordnet, nicht wiederholbar)
Die im Satz gespeicherten Objekte sind ungeordnet und können nicht wiederholt werden. Die Objekte im Satz werden nicht auf eine bestimmte Weise sortiert, sondern die Objekte werden einfach hinzugefügt zur Mitte.
3. Map (Schlüssel-Wert-Paare, eindeutige Schlüssel, nicht eindeutige Werte)
Die Map-Sammlung speichert Schlüssel-Wert-Paare, aber Werte können wiederholt werden. Erhalten Sie den Wert entsprechend dem Schlüssel. Rufen Sie beim Durchlaufen der Kartensammlung zunächst die festgelegte Sammlung des Schlüssels ab, durchlaufen Sie die festgelegte Sammlung und erhalten Sie den entsprechenden Wert.
Der Vergleich ist wie folgt:
|
Ob es in Ordnung ist | Ob Elemente wiederholt werden dürfen | |||||||||||||||||||||||||||||||
| Sammlung | Nein | Ja | |||||||||||||||||||||||||||||||
| Liste | ist | ist | |||||||||||||||||||||||||||||||
| Set | AbstractSet | Nein | Nein | ||||||||||||||||||||||||||||||
| HashSet | |||||||||||||||||||||||||||||||||
| TreeSet | Ja (unter Verwendung eines binär sortierten Baums) | tr>||||||||||||||||||||||||||||||||
| Map | AbstractMap | Nein | Verwenden Sie einen Schlüsselwert, um Daten zuzuordnen und zu speichern. Der Schlüssel muss eindeutig sein und der Wert kann wiederholt werden | ||||||||||||||||||||||||||||||
| HashMap | |||||||||||||||||||||||||||||||||
| TreeMap | ist (unter Verwendung eines binär sortierten Baums) | ||||||||||||||||||||||||||||||||
4. Traversal
Die folgenden vier gängigen Ausgabemethoden werden im Klassensatz bereitgestellt:
1) Iterator: iterative Ausgabe, Dies ist die am häufigsten verwendete Ausgabemethode.
2) ListIterator: Es handelt sich um eine Unterschnittstelle von Iterator, die speziell zur Ausgabe des Inhalts von List verwendet wird.
3) foreach-Ausgabe: eine neue Funktion, die nach JDK1.5 bereitgestellt wird und Arrays oder Mengen ausgeben kann.
4) for-Schleife
Das Codebeispiel lautet wie folgt:
Die Form von for: for (int i=0;i
Verwendung von ArrayList und LinkedList Es gibt keinen Unterschied, aber es gibt immer noch einen funktionalen Unterschied. LinkedList wird häufig in Situationen verwendet, in denen es viele Hinzufügungen und Löschungen, aber nur wenige Abfragevorgänge gibt, während ArrayList das Gegenteil ist.
6. Kartensammlung
Implementierungsklassen: HashMap, Hashtable, LinkedHashMap und TreeMap
HashMap HashMap ist am häufigsten Die verwendete Karte speichert Daten gemäß dem HashCode-Wert des Schlüssels, kann ihren Wert direkt gemäß dem Schlüssel abrufen und weist eine sehr schnelle Zugriffsgeschwindigkeit auf. Beim Durchlaufen ist die Reihenfolge, in der die Daten abgerufen werden, völlig zufällig. Da Schlüsselobjekte nicht wiederholt werden können, lässt HashMap nur zu, dass der Schlüssel eines Datensatzes höchstens Null ist, und ermöglicht, dass der Wert mehrerer Datensätze Null ist, was eine asynchrone
Hashtable
Hashtable ist ähnelt HashMap und ist Die threadsichere Version von HashMap unterstützt die Thread-Synchronisation, das heißt, es kann immer nur ein Thread in Hashtable schreiben, was auch dazu führt, dass Hashtale beim Schreiben langsamer ist Der Unterschied besteht darin, dass die Aufzeichnung nicht möglich ist. Der Schlüssel oder Wert ist null und die Effizienz ist gering.
ConcurrentHashMap
Thread-sicher und durch Sperren getrennt. ConcurrentHashMap verwendet intern Segmente, um diese verschiedenen Teile darzustellen. Jedes Segment ist eigentlich eine kleine Hash-Tabelle und sie haben ihre eigenen Sperren. Mehrere Änderungsvorgänge können gleichzeitig ausgeführt werden, solange sie in verschiedenen Segmenten erfolgen.
LinkedHashMap
LinkedHashMap speichert die Einfügereihenfolge von Datensätzen. Wenn Sie LinkedHashMap verwenden, muss der zuerst erhaltene Datensatz beim Durchlaufen langsamer sein Merkmale.
TreeMap
TreeMap implementiert die SortMap-Schnittstelle, die die gespeicherten Datensätze nach Schlüsseln sortieren kann. Standardmäßig wird nach Schlüsselwerten sortiert (natürliche Reihenfolge). Geben Sie auch einen Sortierkomparator an. Wenn der Iterator die TreeMap durchläuft, werden die erhaltenen Datensätze sortiert. Der Schlüsselwert darf nicht leer und nicht synchronisiert sein;
KartendurchquerungDer erste Typ: KeySet()
Speichern Sie alle Schlüssel im In die Set-Sammlung zuordnen. Weil set Iteratoren hat. Alle Schlüssel können iterativ und dann basierend auf der get-Methode abgerufen werden. Rufen Sie den Wert ab, der jedem Schlüssel entspricht. keySet(): Nach der Iteration kann der Schlüssel nur über get() abgerufen werden.Das erhaltene Ergebnis ist nicht in der richtigen Reihenfolge, da beim Abrufen des Primärschlüssels der Datenzeile die Methode HashMap.keySet() verwendet wird und die Daten im von dieser Methode zurückgegebenen Set-Ergebnis nicht in der richtigen Reihenfolge angeordnet sind. Typische Verwendung ist wie folgt: Map map = new HashMap();
map.put("key1","lisi1");map.put("key2","lisi2" );
map.put("key3","lisi3");
map.put("key4","lisi4");
//Zuerst die festgelegte Sammlung aller Schlüssel in der Karte abrufen Sammlung, Schlüsselsatz ()
Iterator it = map.keySet().iterator();
//Den Iterator abrufen
while(it.hasNext()){
Object key = it.next ();
System.out.println(map.get(key));
}
Zweiter Typ: EntrySet()
Set
Typische Verwendung ist wie folgt:
Map map = new HashMap();
map.put("key1","lisi1");
map.put("key3","lisi3");
map.put("key4","lisi4");
//Entfernen Sie die Zuordnungsbeziehung aus dem Kartensatz und speichern Sie sie im Set Set
Iterator it = map.entrySet().iterator();
while(it.hasNext()){
Entry e =(Entry) it.next();
System.out .println("key" + e.getKey () + "The value is " + e.getValue());
}
Es wird empfohlen, die zweite Methode zu verwenden, die Methode enterSet() , was effizienter ist.
Das keySet wird tatsächlich zweimal durchlaufen, einmal, um es in einen Iterator umzuwandeln, und einmal, um den Wert des Schlüssels aus der HashMap abzurufen. Der Eintragssatz durchläuft nur das erste Mal. Er fügt sowohl den Schlüssel als auch den Wert in den Eintrag ein, sodass er schneller ist. Der Unterschied in der Durchlaufzeit zwischen den beiden Durchquerungen ist immer noch offensichtlich.
7. Zusammenfassung der Unterschiede zwischen den Hauptimplementierungsklassen
Vector und ArrayList
1. Vector ist threadsynchron, also auch threadsicher, während Arraylist dies ist Thread-asynchron ist unsicher. Wenn Thread-Sicherheitsfaktoren nicht berücksichtigt werden, ist es im Allgemeinen effizienter, Arraylist zu verwenden.
2. Wenn die Anzahl der Elemente in der Sammlung größer ist als die Länge des aktuellen Sammlungsarrays, beträgt die Vektorwachstumsrate 100 % der aktuellen Arraylänge und die Arraylisten-Wachstumsrate 50 % der aktuellen Arraylänge . Wenn Sie eine relativ große Datenmenge in einer Sammlung verwenden, hat die Verwendung von Vektor bestimmte Vorteile.
3. Wenn Sie an einem bestimmten Ort nach Daten suchen, ist die von vector und arraylist benötigte Zeit gleich. Wenn Sie häufig auf Daten zugreifen, können Sie zu diesem Zeitpunkt sowohl vector als auch arraylist verwenden. Und wenn das Verschieben einer bestimmten Position dazu führt, dass alle nachfolgenden Elemente verschoben werden, sollten Sie zu diesem Zeitpunkt die Verwendung von Linklist in Betracht ziehen, da dadurch die Daten an einer angegebenen Position verschoben werden und andere Elemente nicht verschoben werden.
ArrayList und Vector verwenden Arrays zum Speichern von Daten. Die Anzahl der Array-Elemente ist größer als die tatsächlich gespeicherten Daten, sodass Elemente hinzugefügt und eingefügt werden können. Beide ermöglichen die direkte Seriennummernindizierung von Elementen, das Einfügen von Daten erfordert jedoch Speicheroperationen Das Verschieben von Array-Elementen erfolgt daher schnell, aber das Einfügen von Daten ist langsam. Da Vector die synchronisierte Methode verwendet (Thread-Sicherheit), ist seine Leistung schlechter als bei ArrayList, bei dem die Datenspeicherung seriell erfolgt Die Zahl erfordert einen Vorwärts- oder Rückwärtsdurchlauf, jedoch nur beim Einfügen von Daten. Sie müssen nur die Elemente vor und nach diesem Element aufzeichnen, sodass das mehrmalige Einfügen schneller ist.
Arraylist und Linkedlist
1. ArrayList implementiert eine Datenstruktur basierend auf dynamischen Arrays und LinkedList implementiert eine Datenstruktur basierend auf verknüpften Listen.
2. Für den Direktzugriff zum Abrufen und Festlegen ist ArrayList besser als LinkedList, da LinkedList den Zeiger bewegen muss.
3. Bei den Neu- und Löschvorgängen Hinzufügen und Entfernen hat LinedList den Vorteil, da ArrayList Daten verschieben muss. Dies hängt von der tatsächlichen Situation ab. Wenn Sie nur ein einzelnes Datenelement einfügen oder löschen, ist ArrayList schneller als LinkedList. Wenn Daten jedoch stapelweise nach dem Zufallsprinzip eingefügt und gelöscht werden, ist die Geschwindigkeit von LinkedList viel besser als die von ArrayList, da jedes Mal, wenn ein Datenelement in ArrayList eingefügt wird, der Einfügepunkt und alle Daten danach verschoben werden müssen.
HashMap und TreeMap
1. HashMap verwendet Hashcode, um seinen Inhalt schnell zu durchsuchen, während alle Elemente in TreeMap eine bestimmte feste Reihenfolge beibehalten. Wenn Sie ein geordnetes Ergebnis benötigen, können Sie TreeMap verwenden. die Reihenfolge der Elemente in HashMap ist nicht festgelegt).
2. Um Elemente in Map einzufügen, zu löschen und zu lokalisieren, ist HashMap die beste Wahl. Wenn Sie jedoch Schlüssel in natürlicher oder benutzerdefinierter Reihenfolge durchlaufen möchten, ist TreeMap besser geeignet. Die Verwendung von HashMap erfordert, dass die hinzugefügte Schlüsselklasse die Implementierung von hashCode() und equal() klar definiert.
Die Elemente in den beiden Karten sind gleich, jedoch in unterschiedlicher Reihenfolge, was zu unterschiedlichen hashCode() führt.
Führen Sie den gleichen Test durch:
Wenn in HashMap die Karte mit demselben Wert in einer anderen Reihenfolge vorliegt, ist „equals“ falsch.
Wenn in TreeMap die Karte mit demselben Wert in einer anderen Reihenfolge vorliegt, ist „equals“ falsch wahr. Beachten Sie, dass treeMap während equal() sortiert wird.
HashTable und HashMap
1. Synchronizität: Hashtable ist threadsicher, was bedeutet, dass es synchron ist, während HashMap threadsicher und nicht synchron ist.
2. HashMap erlaubt einen Nullschlüssel und mehrere Nullwerte.
3. Der Schlüssel und der Wert der Hashtabelle dürfen nicht null sein.
Das obige ist der detaillierte Inhalt vonZusammenfassung der JAVA-Sammlungsklassen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!