
Heim >Java >javaLernprogramm >Zeichenkodierung für eine grundlegende Einführung in Java
Zeichenkodierung für eine grundlegende Einführung in Java
- 巴扎黑Original
- 2017-07-21 14:40:031638Durchsuche
1. ASII
Amerikanischer (nationaler) Information Interchange Standard (Code).
Im Computer gibt es nur Zahlen. Alles wird durch Zahlen dargestellt, und die auf dem Bildschirm angezeigten Zeichen bilden da keine Ausnahme.
Die Zahl, die durch ein Byte dargestellt werden kann, ist 0-255, was ausreicht, um alle Zeichen auf der Tastatur anzuzeigen. Beispielsweise ist a 97 und b 98. Diese Kodierungsregel für Zahlen und Zeichen wird als Asc11-Code bezeichnet. Die höchsten Bits des ASC11-Codes sind alle 0, dh die Werte des ASC11-Codes liegen zwischen 0 und 127.
2. GB2312 und GBK (Chinas lokaler Zeichensatz)
Festlandchina verwendet 2 Bytes zur Darstellung jedes chinesischen Schriftzeichens, wobei das erste Zeichen des chinesischen Schriftzeichens das höchste ist Bits jedes Abschnitts sind alle 1. Dieses Codierungsformat wird als nationaler Standardcode (gb2312) bezeichnet. Dann sind die dem gb2312-Code entsprechenden Zahlen negative Zahlen.
Auf der Grundlage von gb2312 werden einige weitere hinzugefügt, wie zum Beispiel traditionelle chinesische Schriftzeichen, genannt GBK
Anhang:
GB18030-Kodierung ist eine Erweiterung, die auf der GBK-Kodierung basiert, weil Es gibt mehr chinesische Schriftzeichen und die alleinige Verwendung einer zweistelligen Kodierung kann die erforderlichen chinesischen Schriftzeichen nicht mehr unterstützen. Daher wird eine 24-Bit-Hybridmethode übernommen, um mehr chinesische Schriftzeichenkodierungen zu unterstützen.
3. ANSI
Um die ASCII-Codierung zur Anzeige der Landessprache zu erweitern, haben verschiedene Länder und Regionen unterschiedliche Standards formuliert, was zu GB2312, BIG5, JIS und andere jeweilige Codierungsstandards. Diese verschiedenen erweiterten Codierungsmethoden für chinesische Zeichen, die 2 Bytes zur Darstellung eines Zeichens verwenden, werden als ANSI-Codierung bezeichnet, auch bekannt als „MBCS (Muilti-Bytes Charecter Set, Multi-Byte-Zeichensatz)“. Unter dem vereinfachten chinesischen System stellt die ANSI-Kodierung die GB2312-Kodierung dar. Unter dem japanischen Betriebssystem stellt die ANSI-Kodierung die JIS-Kodierung dar. Um unter chinesischem Windows nach gb2312 zu transkodieren, muss gbk den Text daher nur als ANSI-Kodierung speichern. Verschiedene ANSI-Kodierungen sind untereinander nicht kompatibel.
4. Lokaler Zeichensatz
Auf den auf dem chinesischen Festland verwendeten Computersystemen werden GBK und GB2312 als lokale Zeichensätze des Systems bezeichnet.
Das chinesische Zeichen für „中国“, die Kodierung auf dem chinesischen Festland ist hexadezimal D6D0, und in Taiwan ist es A4A4. Die Kodierung wird in Taiwan als BIG5-Big-Five-Code bezeichnet. Wenn ein Zeichen im Lokalisierungssystem eines Landes erscheint und per E-Mail an das Lokalisierungssystem eines anderen Landes übermittelt wird, sehen Sie nicht das Originalzeichen, sondern die Zeichen oder verstümmelten Zeichen eines anderen Landes.
5. Unicode-Kodierung
Die ISO-Organisation hat die Symbole weltweit vereinheitlicht und nennt sie Unicode-Kodierung.
Das Symbol „中“ ist weltweit das Hexadezimal 4e2d. Wenn alle Computer die Unicode-Codierung verwenden, wird das Wort „中“ auf Computern auf der ganzen Welt als „中“ angezeigt. Unicode-codierte Zeichen belegen zwei Bytes, was durch den AC11-Code dargestellt wird wobei alle Bits vor dem ursprünglich vom AS11-Code belegten Byte gleich 0 sind. Die Anzahl der dargestellten Zeichen wird 65535 nicht überschreiten. Tatsächlich werden immer noch mehr als 2.000 Werte gespeichert, die nicht für die Codierung verwendet werden.
Unicode hat noch lange keine einheitliche Welt gebildet. Die lokalisierte Zeichenkodierung wird mit der Unicode-Kodierung koexistieren.
Zeichen in Java sind alle Unicode-Kodierung.
Java unterstützt auch lokale Plattformzeichensätze unter der Voraussetzung, plattformübergreifende Funktionen durch Unicode sicherzustellen.
6. UTF-8
Am Entwicklungsprozess der Java-Sprache und anderer Programme, insbesondere XML, ist auch UTF-8 UTF-16 beteiligt. Unicode im weitesten Sinne umfasst auch UTF8 und utf-16
UTF-8
--ASC11-Codezeichen bleiben intakt und belegen nur ein Byte.
--Für Zeichen aus anderen Ländern verwendet UTF-8 zwei oder drei Bytes, um sie darzustellen.
--Bei Verwendung von UTF-8-codierten Dateien verwenden Sie normalerweise EF BB BF als die drei Datenbytes am Anfang der Datei.
7. Konvertierungsregeln zwischen UTF-8 und Unicode-Kodierung
-- 0001-007f (ein Byte)
0xxxxxx
-- 0000 oder seine Zeichen zwischen 0080 und 07ff,
110xxxxx 10xxxxxx (11 gültige Bits) (zwischen 0080-07ff) Ein Unicode hat 16 Bits, tatsächlich gibt es nur 11 gültige Bits, der Rest sind Flags.
--Zeichen zwischen 0800 und ffff, 1110xxxx 10xxxxxx 10xxxxxx (16 signifikante Bits). Die Software kann anhand der festen Bitwerte in der UTF-8-Codierung leicht bestimmen, was ein Zeichen belegt. Ein Byte, zwei Bytes oder drei Bytes.
8. Vorteile von UTF-8
-- ox00 erscheint nicht (in C-Sprache,
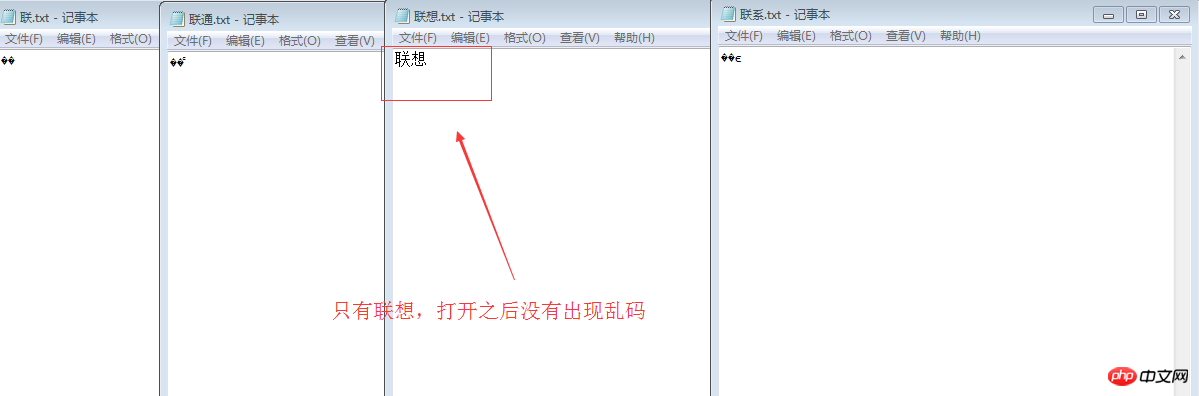
Öffnen Sie mit ue, überprüfen Sie die Hexadezimalzahl, sie sind C1AA CDA8 C1AA CFE8 // Diese verwenden alle die GB2312-Kodierung, es ist D6D0, das heißt, C1AA ist die Link CDA8 ist dasselbe wie CFE8. Die binäre Darstellung davon kann auf folgende Weise erhalten werden:
int x=0xCDA8; System.out.println(Integer.toBinaryString(x) );
//11000001 10101010 Link 11001101 10101000 Über die Datei in
Notepad ist die Standardeinstellung Chinesisch Der Zeichensatz GB2312 wird zum Speichern der Zeichen verwendet, sodass das Zeichen „Lian“ in 1100 0001 1010 1010 analysiert wird und das Zeichen „通“ als 1100 1101 1010 1000 gespeichert wird. Wenn das Notepad-Dokument geöffnet wird, werden diese binären Formen angezeigt Da die Regeln von UTF-8 eingehalten werden, geht das System davon aus, dass es sich um eine UTF-8-kodierte Datei handelt. Die Lösung: Drücken Sie beim Speichern direkt auf UTF-8 Speichern erschien.
10. Verwenden Sie das Programm, um die Zeichenkodierung zu überprüfen
Sehen Sie sich den GB2312-Code der chinesischen Schriftzeichen an
Überprüfen Sie den UTF-8-Code der chinesischen Schriftzeichen
Sehen Sie sich den Unicode-Code chinesischer Schriftzeichen an
public static void main(String[] args) throws UnsupportedEncodingException {
String str="中国"; //查看字符的unicode码,将一个字符转成整数,得到的就是unicode值/* for(int i=0;i<str.length();i++){
int unicodeCode=str.charAt(i);
System.out.println(unicodeCode); // 20013,22269
System.out.println(Integer.toHexString(unicodeCode)); //对应的16进制 4e2d,56fd
}*///查看字符的gb2312码byte [] buff =str.getBytes("gb2312"); for(int i=0;i<buff.length;i++){
System.out.println(buff[i]); // -42,-48, -71,-6System.out.println(Integer.toHexString(buff[i])); //ffffffd6 ,ffffffd0 ffffffb9,fffffffa }
}
Das obige ist der detaillierte Inhalt vonZeichenkodierung für eine grundlegende Einführung in Java. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!