
Heim >Backend-Entwicklung >Python-Tutorial >Wie verwende ich pymysqlpool in der Python-MySQL-Datenbank?
Wie verwende ich pymysqlpool in der Python-MySQL-Datenbank?

- 零下一度Original
- 2017-07-09 11:57:264160Durchsuche
Dieser Artikel führt Sie hauptsächlich in die relevanten Informationen zur Python-MySQL-Datenbank--Verbindungspoolkomponente pymysqlpool ein Schauen wir uns das unten gemeinsam an.
Einführung
pymysqlpool (lokaler Download) ist ein neues Mitglied des Datenbank-Toolkits mit dem Ziel, einen praktischen Datenbankverbindungspool bereitzustellen Middleware, um die häufige Erstellung und Freigabe von Datenbankverbindungsressourcen in der Anwendung zu vermeiden. Der Verbindungspool selbst ist Thread-sicher und kann in einer Multithread-Umgebung verwendet werden, ohne sich Gedanken über die gemeinsame Nutzung von Verbindungsressourcen durch mehrere Threads machen zu müssen.
 Bietet die kompakteste Schnittstelle, die möglich ist
Bietet die kompakteste Schnittstelle, die möglich ist
;Die Verwaltung des Verbindungspools wird innerhalb des Pakets abgeschlossen, und der Client kann die Verbindungsressourcen im Pool über die Schnittstelle abrufen (Rückgabe
);
ist weitestgehend mit dataobj kompatibel und einfach zu verwenden
Der Verbindungspool selbst hat die Funktion Die Anzahl der Verbindungen wird dynamisch erhöht, d. h. max_pool_size und step_size werden verwendet, um die Anzahl der Verbindungen und die maximale Anzahl der Verbindungen zu steuern Der Verbindungspool wird ebenfalls dynamisch erhöht und der Schalter „enable_auto_resize“ muss aktiviert werden. Wenn danach eine Zeitüberschreitung bei der Verbindungserfassung auftritt, wird dies als Strafe aufgezeichnet und max_pool_size um ein bestimmtes Vielfaches erweitert.
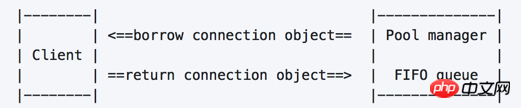
pymysql.ConnectionGrundlegender Arbeitsablauf- Beachten Sie Folgendes: Wenn mehrere Threads gleichzeitig eine Anfrage stellen, wenn der Pool Wenn keine verfügbaren Verbindungsobjekte vorhanden sind, müssen Sie in der Warteschlange warten
- Nach der Initialisierung werden zuerst die Verbindungsobjekte „step_size“ erstellt und im Verbindungspool platziert
Der Client fordert ein Verbindungsobjekt an, und der Verbindungspool wählt ein Verbindungsobjekt aus, das kürzlich nicht verwendet wurde, und gibt es zurück (er prüft auch, ob die Verbindung normal ist);
Verbindungsobjekt. Rufen Sie nach dem Ausführen der entsprechenden Operation die Schnittstelle auf, um das Verbindungsobjekt zurückzugeben. Der Verbindungspool wird recycelt das Verbindungsobjekt und fügt es der Warteschlange im Pool hinzu, damit es von anderen Anforderungen verwendet werden kann.
Parameterkonfiguration
- pool_name: Der Name des Verbindungspools entspricht mehreren verschiedenen Verbindungspoolobjekten, mehreren Singleton-Modus
-
Host: Datenbankadresse
Benutzer: Benutzername des Datenbankservers
|--------| |--------------| | | <==borrow connection object== | Pool manager | | Client | | | | | ==return connection object==> | FIFO queue | |--------| |--------------|
Passwort: Benutzerpasswort
Datenbank: Die standardmäßig ausgewählte Datenbank
- Zeichensatz:
- Zeichensatz
, der Standard ist 'utf8 '
use_dict_cursor: Verwenden Sie das Wörterbuchformat oder Tupel, um Daten zurückzugeben
max_pool_size: Maximale Anzahl von Verbindungen
step_size: Der Verbindungspool erhöht dynamisch die Anzahl der Verbindungen;
-
enable_auto_resize: Ob der Verbindungspool dynamisch erweitert werden soll, d. h. bei max_pool_size wird überschritten, max_pool_size wird automatisch erweitert;
pool_resize_boundary: Diese Konfiguration ist die Obergrenze, die der Verbindungspool schließlich erhöhen kann, und die sofortige Erweiterung kann diesen Wert nicht überschreiten; 🎜>auto_resize_scale: Max_pool_size Gain automatisch erweitern, der Standardwert ist das 1,5-fache der Erweiterung;
wait_timeout: Wie lange maximal gewartet werden soll, wenn auf ein Verbindungsobjekt gewartet wird, wann Der Verbindungspool läuft ab. Versuchen Sie, die aktuelle Anzahl der Verbindungen automatisch zu erweitern. kwargs: Andere Konfigurationsparameter werden an
Verwendungsbeispiel
- 1 Verwenden Sie den Cursor-Kontextmanager (Abkürzung, aber es gilt für a Verbindungsobjekt jedes Mal, wenn es abgerufen wird, daher sind mehrere Aufrufe ineffizient):
- 2. Verwenden Sie den Verbindungskontextmanager:
Bitte testen Sie mehr. Wechseln Sie zu test_example.py.
pymysql.ConnectionAbhängig von
pymysql: Auf dieses Toolkit wird zurückgegriffen, um die Datenbankverbindung und andere Vorgänge abzuschließen ;
Pandas: Pandas wurde beim Testen verwendet.
Das obige ist der detaillierte Inhalt vonWie verwende ich pymysqlpool in der Python-MySQL-Datenbank?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!