
Heim >Datenbank >MySQL-Tutorial >Wie implementiert mongoDB Paging?
Wie implementiert mongoDB Paging?

- 零下一度Original
- 2017-07-03 16:39:201924Durchsuche
Dieser Artikel stellt hauptsächlich die beiden Methoden von mongoDB zur Implementierung von Paging vor. Interessierte Freunde können sich darauf beziehen
MongoDBs Paging query verwendet die drei Funktionen array limit(), skip() und sort(), um eine Paging-Abfrage durchzuführen.
Das Folgende sind meine Testdaten
db.test.find().sort({"age":1});

Die erste Methode
Fragen Sie die Daten auf der ersten Seite ab: db.test.find().sort({"age":1}).limit(2); 🎜>


Die zweite Methode
Fragen Sie die Daten auf der ersten Seite ab: db.test.find().sort({"age":1}).limit( 2);
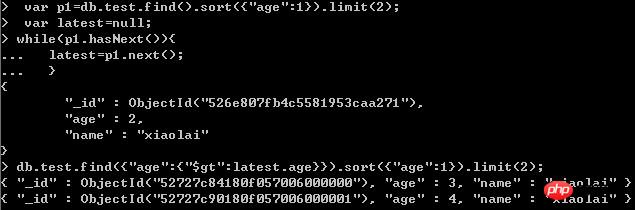
Überspringen überspringt zu viele Datensätze und die Effizienz ist etwas geringNach sorgfältiger Überlegung ist die zweite Methode Es ist in der Tat nicht zum Überspringen von Seiten geeignet und auch nicht sehr effizient.
Für große Datenmengen müssen wir eine spezielle Verarbeitung durchführen
Es gibt die folgenden zwei Methoden
Die erste Methode
 Begrenzen Sie die Anzahl der Paging-Seiten, ähnlich der Paging-Verarbeitung von Baidu, die nur zeigt die vorherigen siebenhundert Datensätze an, so dass es keinen Grund gibt, Leistungsprobleme zu berücksichtigen. Schließlich blättern die meisten Leute einfach auf den ersten zehn Seiten und finden, was sie brauchen.
Begrenzen Sie die Anzahl der Paging-Seiten, ähnlich der Paging-Verarbeitung von Baidu, die nur zeigt die vorherigen siebenhundert Datensätze an, so dass es keinen Grund gibt, Leistungsprobleme zu berücksichtigen. Schließlich blättern die meisten Leute einfach auf den ersten zehn Seiten und finden, was sie brauchen.
Die folgenden statistischen Ergebnisse sollten geschätzt werden über den Anteil dieser gefundenen Datensätze. Schätzen Sie die Gesamtzahl der Datensätze.
Die zweite MethodeVorausgesetzt, es ist sortiert Zur ID können wir der ID folgen. Die Seriennummer der Seite, auf der sich die ID befindet, wird in redis/MemberCached gespeichert,
so, vorausgesetzt, jede Seite hat 10 Datensätze
ID-Seite
1 1
2 1
. . .
10 1
11 2
12 2
. . . .
20 2
Auf diese Weise können wir beim Überprüfen der ersten Seite direkt zehn Datenelemente abrufen
Angenommen, es gibt 100 Millionen Datenelemente, einen Datensatz Die ID belegt 4 Bytes. Andere Informationen belegen ein Byte und ein Datensatz belegt 5 Bytes.
1 0000 0000 *5/(1024*1024)=476 MB
Dieser Ansatz verwendet im Allgemeinen Raum für Zeit Der größte Teil der Datenbankabfragezeit wird für die Verbindung zur Datenbank aufgewendet. Das Einfügen in den Cache kann die Abfrage erheblich beschleunigen
Das obige ist der detaillierte Inhalt vonWie implementiert mongoDB Paging?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!