
Heim >Java >javaLernprogramm >Ausführliche Erläuterung des Thread-Pool-Prinzips ThreadPoolExecutor von JAVA und seiner Beispiele für die Ausführungsmethode
Ausführliche Erläuterung des Thread-Pool-Prinzips ThreadPoolExecutor von JAVA und seiner Beispiele für die Ausführungsmethode

- 怪我咯Original
- 2017-06-30 10:38:362691Durchsuche
Der folgende Editor bringt Ihnen einen Artikel über das Thread-Pool-Prinzip ThreadPoolExecutor und seine Ausführungsmethode (ausführliche Erklärung). Der Herausgeber findet es ziemlich gut, deshalb teile ich es jetzt mit Ihnen und gebe es als Referenz. Kommen Sie und werfen Sie einen Blick mit dem Editor
jdk1.7.0_79
Die meisten Leute verwenden möglicherweise Thread-Pools und wissen auch, warum. Es ist nur so, dass Aufgaben asynchron ausgeführt werden müssen und Threads einheitlich verwaltet werden müssen. In Bezug auf das Abrufen von Threads aus dem Thread-Pool wissen die meisten Leute möglicherweise nur, dass ich die Aufgabe in den Thread-Pool werfen werde, wenn ich einen Thread zum Ausführen einer Aufgabe benötige . Wenn kein Leerlaufthread vorhanden ist, wird er einfach ausgeführt. Tatsächlich ist das Ausführungsprinzip des Thread-Pools weitaus mehr als einfach.
Das Java-Parallelitätspaket stellt eine Thread-Pool-Klasse bereit – ThreadPoolExecutor. Tatsächlich verwenden mehr von uns möglicherweise den von der Executors-Factory-Klasse bereitgestellten Thread-Pool: newFixedThreadPool, newSingleThreadPool, newCachedThreadPool. Diese drei Thread-Pools sind keine Unterklassen Schauen wir uns im Hinblick auf die Beziehung zwischen diesen zunächst den Quellcode an und stellen Sie fest, dass er über insgesamt 4 Konstruktionsmethoden verfügt.
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue)
Beginnen wir zunächst mit diesen Parametern, um das Ausführungsprinzip des Thread-Pools ThreadPoolExecutor zu verstehen.
corePoolSize: Die Anzahl der Threads im Kern-Thread-Pool
maximumPoolSize: Maximale Anzahl von Thread-Pool-Threads
keepAliveTime: Aufbewahrungszeit der Thread-Aktivität nach dem Arbeitsthread von Der Thread-Pool ist inaktiv, es ist Zeit, am Leben zu bleiben.
Einheit: Einheit der Aufbewahrungszeit der Thread-Aktivität.
workQueue: Geben Sie die von der Aufgabenwarteschlange verwendete Blockierungswarteschlange an
Sowohl corePoolSize als auch MaximumPoolSize sind in Der angegebene Thread ist die Anzahl der Threads im Pool. Wenn Sie den Thread-Pool normalerweise verwenden, müssen Sie anscheinend nur einen Parameter der Thread-Pool-Größe übergeben, um einen Thread-Pool zu erstellen. Java stellt uns einige häufig verwendete Thread-Pool-Klassen zur Verfügung , nämlich der oben erwähnte newFixedThreadPool, newSingleThreadExecutor, newCachedThreadPool. Wenn wir selbst einen benutzerdefinierten Thread-Pool erstellen möchten, müssen wir natürlich einige Parameter im Zusammenhang mit dem Thread-Pool selbst „konfigurieren“.
Wenn eine Aufgabe zur Verarbeitung an den Thread-Pool übergeben wird, ist das Ausführungsprinzip des Thread-Pools wie in der folgenden Abbildung dargestellt. Siehe „Die Kunst der gleichzeitigen Java-Programmierung“
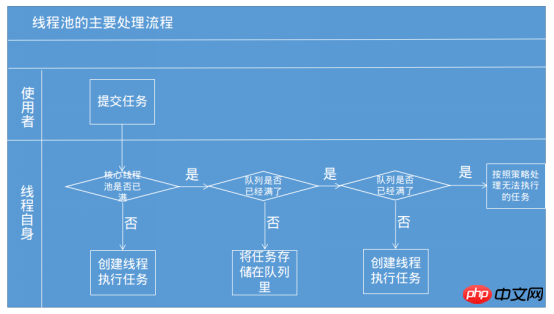
① Zunächst wird ermittelt, ob Threads im Kern-Thread-Pool vorhanden sind, die ausgeführt werden können. Wenn es inaktive Threads gibt, wird ein Thread erstellt, um die Aufgabe auszuführen.
②Wenn im Kern-Thread-Pool keine Threads zur Ausführung verfügbar sind, wird die Aufgabe in die Aufgabenwarteschlange geworfen.
③ Wenn die Aufgabenwarteschlange (begrenzt) ebenfalls voll ist, die Anzahl der laufenden Threads jedoch geringer ist als die Anzahl des maximalen Thread-Pools, wird ein neuer Thread erstellt, um die Aufgabe auszuführen Wenn die Anzahl der Threads die maximale Anzahl an Thread-Pools erreicht hat, können keine Threads zur Ausführung von Aufgaben erstellt werden.
Tatsächlich wirft der Thread-Pool die Aufgabe nicht einfach in den Thread-Pool. Wenn Threads im Thread-Pool vorhanden sind, wird die Aufgabe ausgeführt, und wenn keine Threads vorhanden sind, wartet sie .
Um die Prinzipien von Thread-Pools zu konsolidieren, lernen wir nun die drei oben genannten häufig verwendeten Thread-Pools kennen:
Executors.newFixedThreadPool: Erstellen Sie einen Thread-Pool mit einer festen Anzahl von Threads .
// Executors#newFixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>());
}Sie können sehen, dass die ThreadPoolExecutor-Klasse in newFixedThreadPool aufgerufen wird und der übergebene Parameter corePoolSize= MaximumPoolSize=nThread ist. Rückblickend auf das Ausführungsprinzip des Thread-Pools wird beim Senden einer Aufgabe an den Thread-Pool zunächst festgestellt, ob sich im Kern-Thread-Pool inaktive Threads befinden. Wenn nicht, wird ein Thread erstellt Die Aufgabe wird in die Aufgabenwarteschlange gestellt (hier ist die begrenzte Blockierungswarteschlange LinkedBlockingQueue). Wenn die Aufgabenwarteschlange voll ist, beträgt die maximale Anzahl an Thread-Pools = die Anzahl der Kern-Thread-Pools Die Aufgabenwarteschlange ist ebenfalls voll und neue Threads können nicht erweitert werden, um Aufgaben auszuführen.
Executors.newSingleThreadExecutor: Erstellen Sie einen Thread-Pool, der nur einen Thread enthält.
//Executors# newSingleThreadExecutor
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegateExecutorService(new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()));
}只有一个线程的线程池好像有点奇怪,并且并没有直接将返回ThreadPoolExecutor,甚至也没有直接将线程池数量1传递给newFixedThreadPool返回。那就说明这个只含有一个线程的线程池,或许并没有只包含一个线程那么简单。在其源码注释中这么写到:创建只有一个工作线程的线程池用于操作一个无界队列(如果由于前驱节点的执行被终止结束了,一个新的线程将会继续执行后继节点线程)任务得以继续执行,不同于newFixedThreadPool(1)不会有额外的线程来重新继续执行后继节点。也就是说newSingleThreadExecutor自始至终都只有一个线程在执行,这和newFixedThreadPool一样,但如果线程终止结束过后newSingleThreadExecutor则会重新创建一个新的线程来继续执行任务队列中的线程,而newFixedThreaPool则不会。
Executors.newCachedThreadPool:根据需要创建新线程的线程池。
//Executors#newCachedThreadPool
public static ExecutorService newCachedThreadPool() {
return new ThreadPooExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>());
}可以看到newCachedThread返回的是ThreadPoolExecutor,其参数核心线程池corePoolSize = 0, maximumPoolSize = Integer.MAX_VALUE,这也就是说当任务被提交到newCachedThread线程池时,将会直接把任务放到SynchronousQueue任务队列中,maximumPool从任务队列中获取任务。注意SynchronousQueue是一个没有容量的队列,也就是说每个入队操作必须等待另一个线程的对应出队操作,如果主线程提交任务的速度高于maximumPool中线程处理任务的速度时,newCachedThreadPool会不断创建线程,线程多并不是一件好事,严重会耗尽CPU和内存资源。
题外话:newFixedThreadPool、newSingleThreadExecutor、newCachedThreadPool,这三者都直接或间接调用了ThreadPoolExecutor,为什么它们三者没有直接是其子类,而是通过Executors来实例化呢?这是所采用的静态工厂方法,在java.util.Connections接口中同样也是采用的静态工厂方法来创建相关的类。这样有很多好处,静态工厂方法是用来产生对象的,产生什么对象没关系,只要返回原返回类型或原返回类型的子类型都可以,降低API数目和使用难度,在《Effective Java》中的第1条就是静态工厂方法。
回到ThreadPoolExecutor,首先来看它的继承关系:
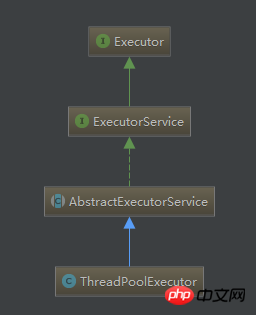
ThreadPoolExecutor它的顶级父类是Executor接口,只包含了一个方法——execute,这个方法也就是线程池的“执行”。
//Executor#execute
public interface Executor {
void execute(Runnable command);
}Executor#execute的实现则是在ThreadPoolExecutor中实现的:
//ThreadPoolExecutor#execute
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
…
}一来就碰到个不知所云的ctl变量它的定义:
private final AtomicInteger ctl = new AtlmicInteger(ctlOf(RUNNING, 0));
这个变量使用来干嘛的呢?它的作用有点类似我们在《ReadWriteLock接口及其实现ReentrantReadWriteLock》中提到的读写锁有读、写两个同步状态,而AQS则只提供了state一个int型变量,此时将state高16位表示为读状态,低16位表示为写状态。这里的clt同样也是,它表示了两个概念:
workerCount:当前有效的线程数
runState:当前线程池的五种状态,Running、Shutdown、Stop、Tidying、Terminate。
int型变量一共有32位,线程池的五种状态runState至少需要3位来表示,故workCount只能有29位,所以代码中规定线程池的有效线程数最多为229-1。
//ThreadPoolExecutor private static final int COUNT_BITS = Integer.SIZE – 3; //32-3=29,线程数量所占位数 private static final int CAPACITY = (1 << COUNT_BITS) – 1; //低29位表示最大线程数,229-1 //五种线程池状态 private static final int RUNNING = -1 << COUNT_BITS; /int型变量高3位(含符号位)101表RUNING private static final int SHUTDOWN = 0 << COUNT_BITS; //高3位000 private static final int STOP = 1 << COUNT_BITS; //高3位001 private static final int TIDYING = 2 << COUNT_BITS; //高3位010 private static final int TERMINATED = 3 << COUNT_BITS; //高3位011
再次回到ThreadPoolExecutor#execute方法:
//ThreadPoolExecutor#execute
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get(); //由它可以获取到当前有效的线程数和线程池的状态
/*1.获取当前正在运行线程数是否小于核心线程池,是则新创建一个线程执行任务,否则将任务放到任务队列中*/
if (workerCountOf(c) < corePoolSize){
if (addWorker(command, tre)) //在addWorker中创建工作线程执行任务
return ;
c = ctl.get();
}
/*2.当前核心线程池中全部线程都在运行workerCountOf(c) >= corePoolSize,所以此时将线程放到任务队列中*/
if (isRunning(c) && workQueue.offer(command)) { //线程池是否处于运行状态,且是否任务插入任务队列成功
int recheck = ctl.get();
if (!isRunning(recheck) && remove(command)) //线程池是否处于运行状态,如果不是则使刚刚的任务出队
reject(command); //抛出RejectedExceptionException异常
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
/*3.插入队列不成功,且当前线程数数量小于最大线程池数量,此时则创建新线程执行任务,创建失败抛出异常*/
else if (!addWorker(command, false)){
reject(command); //抛出RejectedExceptionException异常
}
}上面代码注释第7行的即判断当前核心线程池里是否有空闲线程,有则通过addWorker方法创建工作线程执行任务。addWorker方法较长,筛选出重要的代码来解析。
//ThreadPoolExecutor#addWorker
private boolean addWorker(Runnable firstTask, boolean core) {
/*首先会再次检查线程池是否处于运行状态,核心线程池中是否还有空闲线程,都满足条件过后则会调用compareAndIncrementWorkerCount先将正在运行的线程数+1,数量自增成功则跳出循环,自增失败则继续从头继续循环*/
...
if (compareAndIncrementWorkerCount(c))
break retry;
...
/*正在运行的线程数自增成功后则将线程封装成工作线程Worker*/
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
final ReentrantLock mainLock = this.mainLock; //全局锁
w = new Woker(firstTask); //将线程封装为Worker工作线程
final Thread t = w.thread;
if (t != null) {
mainLock.lock(); //获取全局锁
/*当持有了全局锁的时候,还需要再次检查线程池的运行状态等*/
try {
int c = clt.get();
int rs = runStateOf(c); //线程池运行状态
if (rs < SHUTDOWN || (rs == SHUTDOWN && firstTask == null)){ //线程池处于运行状态,或者线程池关闭且任务线程为空
if (t.isAlive()) //线程处于活跃状态,即线程已经开始执行或者还未死亡,正确的应线程在这里应该是还未开始执行的
throw new IllegalThreadStateException();
workers.add(w); //private final HashSet<Worker> wokers = new HashSet<Worker>();包含线程池中所有的工作线程,只有在获取了全局的时候才能访问它。将新构造的工作线程加入到工作线程集合中
int s = worker.size(); //工作线程数量
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true; //新构造的工作线程加入成功
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
t.start(); //在被构造为Worker工作线程,且被加入到工作线程集合中后,执行线程任务,注意这里的start实际上执行Worker中run方法,所以接下来分析Worker的run方法
workerStarted = true;
}
}
} finally {
if (!workerStarted) //未能成功创建执行工作线程
addWorkerFailed(w); //在启动工作线程失败后,将工作线程从集合中移除
}
return workerStarted;
}在上面第35代码中,工作线程被成功添加到工作线程集合中后,则开始start执行,这里start执行的是Worker工作线程中的run方法。
//ThreadPoolExecutor$Worker,它继承了AQS,同时实现了Runnable,所以它具备了这两者的所有特性
private final class Worker extends AbstractQueuedSynchronizer implements Runnable {
final Thread thread;
Runnable firstTask;
public Worker(Runnable firstTask) {
setState(-1); //设置AQS的同步状态为-1,禁止中断,直到调用runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this); //通过线程工厂来创建一个线程,将自身作为Runnable传递传递
}
public void run() {
runWorker(this); //运行工作线程
}
}ThreadPoolExecutor#runWorker,在此方法中,Worker在执行完任务后,还会循环获取任务队列里的任务执行(其中的getTask方法),也就是说Worker不仅仅是在执行完给它的任务就释放或者结束,它不会闲着,而是继续从任务队列中获取任务,直到任务队列中没有任务可执行时,它才退出循环完成任务。理解了以上的源码过后,往后线程池执行原理的第二步、第三步的理解实则水到渠成。
Das obige ist der detaillierte Inhalt vonAusführliche Erläuterung des Thread-Pool-Prinzips ThreadPoolExecutor von JAVA und seiner Beispiele für die Ausführungsmethode. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!