
Heim >Java >javaLernprogramm >Hash – Einführung in gängige Algorithmen
Hash – Einführung in gängige Algorithmen

- 零下一度Original
- 2017-06-29 11:29:192944Durchsuche
Hash (Hash), auch Hashing genannt, ist ein sehr verbreiteter Algorithmus. Hash wird hauptsächlich in der HashMap-Datenstruktur von Java verwendet. Der Hash-Algorithmus besteht aus zwei Teilen: Hash-Funktion und Hash-Tabelle. Wir können die Eigenschaften unseres Arrays schnell erkennen (O(1)). In einer Hash-Tabelle können wir auch Schlüssel (Hash-Werte) verwenden. Um einen bestimmten Wert schnell zu finden, wird der Hash-Wert über die Hash-Funktion (hash(key) = Adresse) berechnet. Das Element [Adresse] = Wert kann über den Hashwert gefunden werden. Das Prinzip ähnelt dem eines Arrays.
Die beste Hash-Funktion ist natürlich eine, die einen eindeutigen Hash-Wert für jeden Schlüssel-Wert berechnen kann, aber es können oft unterschiedliche sein Schlüssel Hash-Wert, der Konflikte verursacht. Es gibt zwei Aspekte, um zu beurteilen, ob eine Hash-Funktion gut gestaltet ist:
1. Wenige Konflikte.
2. Die Berechnung ist schnell.
Im Folgenden sind einige häufig verwendete Hash-Funktionen aufgeführt, denen alle bestimmte mathematische Prinzipien zugrunde liegen und die viel Übung erfahren haben. Ihre mathematischen Prinzipien werden hier nicht untersucht.
BKDRHash-Funktion (h = 31 * h + c)
Diese Hash-Funktion wird auf die Berechnung des String-Hash-Werts in Java angewendet.
//String#hashCodepublic int hashCode() {int h = hash;if (h == 0 && value.length > 0) {char val[] = value;for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i]; //BKDR 哈希函数,常数可以是131、1313、13131…… }
hash = h;
}return h;
}
DJB2 Hash-Funktion ( h = h << 5 + h + c = h = 33 * h + c)
ElasticSearch nutzt < Die 🎜>DJB2 Hash-Funktion hasht den angegebenen Schlüssel des zu indizierenden Dokuments.
SDBMHash-Funktion (h = h << 6 + h << 16 - h + c = 65599 * h + c)
wird inSDBM (einer einfachen Datenbank-Engine) angewendet.
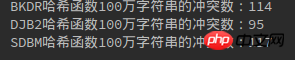
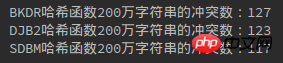
Das Obige ist nur eine Liste von drei Hash-Funktionen. Lassen Sie uns ein Experiment durchführen, um zu sehen, wie sie miteinander in Konflikt stehen.Java
1 package com.algorithm.hash; 2 3 import java.util.HashMap; 4 import java.util.UUID; 5 6 /** 7 * 三种哈希函数冲突数比较 8 * Created by yulinfeng on 6/27/17. 9 */10 public class HashFunc {11 12 public static void main(String[] args) {13 int length = 1000000; //100万字符串14 //利用HashMap来计算冲突数,HashMap的键值不能重复所以length - map.size()即为冲突数15 HashMap<String, String> bkdrMap = new HashMap<String, String>();16 HashMap<String, String> djb2Map = new HashMap<String, String>();17 HashMap<String, String> sdbmMap = new HashMap<String, String>();18 getStr(length, bkdrMap, djb2Map, sdbmMap);19 System.out.println("BKDR哈希函数100万字符串的冲突数:" + (length - bkdrMap.size()));20 System.out.println("DJB2哈希函数100万字符串的冲突数:" + (length - djb2Map.size()));21 System.out.println("SDBM哈希函数100万字符串的冲突数:" + (length - sdbmMap.size()));22 }23 24 /**25 * 生成字符串,并计算冲突数26 * @param length27 * @param bkdrMap28 * @param djb2Map29 * @param sdbmMap30 */31 private static void getStr(int length, HashMap<String, String> bkdrMap, HashMap<String, String> djb2Map, HashMap<String, String> sdbmMap) {32 for (int i = 0; i < length; i++) {33 System.out.println(i);34 String str = UUID.randomUUID().toString();35 bkdrMap.put(String.valueOf(str.hashCode()), str); //Java的String.hashCode就是BKDR哈希函数, h = 31 * h + c36 djb2Map.put(djb2(str), str); //DJB2哈希函数37 sdbmMap.put(sdbm(str), str); //SDBM哈希函数38 }39 }40 41 /**42 * djb2哈希函数43 * @param str44 * @return45 */46 private static String djb2(String str) {47 int hash = 0;48 for (int i = 0; i != str.length(); i++) {49 hash = hash * 33 + str.charAt(i); //h = h << 5 + h + c = h = 33 * h + c50 }51 return String.valueOf(hash);52 }53 54 /**55 * sdbm哈希函数56 * @param str57 * @return58 */59 private static String sdbm(String str) {60 int hash = 0;61 for (int i = 0; i != str.length(); i++) {62 hash = 65599 * hash + str.charAt(i); //h = h << 6 + h << 16 - h + c = 65599 * h + c63 }64 return String.valueOf(hash);65 }66 }1010.000, 10010.000, 20010.000 Konfliktsituationen:

Python3
1 import uuid 2 3 def hash_test(length, bkdrDic, djb2Dic, sdbmDic): 4 for i in range(length): 5 string = str(uuid.uuid1()) #基于时间戳 6 bkdrDic[bkdr(string)] = string 7 djb2Dic[djb2(string)] = string 8 sdbmDic[sdbm(string)] = string 9 10 #BDKR哈希函数11 def bkdr(string):12 hash = 013 for i in range(len(string)):14 hash = 31 * hash + ord(string[i]) # h = 31 * h + c15 return hash16 17 #DJB2哈希函数18 def djb2(string):19 hash = 020 for i in range(len(string)):21 hash = 33 * hash + ord(string[i]) # h = h << 5 + h + c22 return hash23 24 #SDBM哈希函数25 def sdbm(string):26 hash = 027 for i in range(len(string)):28 hash = 65599 * hash + ord(string[i]) # h = h << 6 + h << 16 - h + c29 return hash30 31 length = 10032 bkdrDic = dict() #bkdrDic = {}33 djb2Dic = dict()34 sdbmDic = dict()35 hash_test(length, bkdrDic, djb2Dic, sdbmDic)36 print("BKDR哈希函数100万字符串的冲突数:%d"%(length - len(bkdrDic)))37 print("DJB2哈希函数100万字符串的冲突数:%d"%(length - len(djb2Dic)))38 print("SDBM哈希函数100万字符串的冲突数:%d"%(length - len(sdbmDic)))
Hash-Tabelle ist eine Datenstruktur, die mit Hash-Funktionen verwendet werden muss, um Indizes für die schnelle Suche zu erstellen——"Hinweise zum Algorithmus". Im Allgemeinen handelt es sich um einen Speicherplatz mit fester Länge, wie zum Beispiel HashMapDie Standard-Hash-Tabelle ist eine Hash-Tabelle mit fester Länge von 16Entry Array. Nachdem ein Speicherplatz mit fester Länge vorhanden ist, besteht das verbleibende Problem darin, wie der Wert an welcher Position platziert werden soll. Wenn der Hash-Wert normalerweise m ist, beträgt die Länge n, dann wird dieser Wert an der Position m mod n platziert.
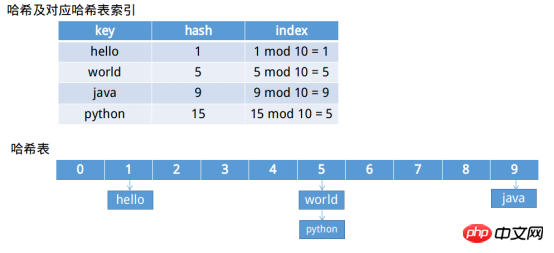
Das Bild oben zeigt den Hash und die Hash-Tabelle, sowie die Lösung des Konflikts (Zipper-Methode). Es gibt viele Möglichkeiten, Konflikte zu lösen, einschließlich eines erneuten Hashings, bis keine Konflikte mehr vorliegen, oder der Verwendung der Zipper-Methode zum Verketten von Elementen an derselben Position mithilfe einer verknüpften Liste, wie in der Abbildung oben dargestellt.
Stellen Sie sich vor, dass die Länge der Hash-Tabelle im obigen Beispiel 10 beträgt, was zu 1 Kollisionen führt Die Tabellenlänge beträgt 20, dann wird es keinen Konflikt geben, aber es wird mehr Platz verschwendet, wenn die Hash-Tabellenlänge 2, invertiert 3 Konfliktsuchen langsamer, spart aber viel Platz. Die Längenauswahl der Hash-Tabelle ist also entscheidend, aber auch ein wichtiges Problem.
Zusätzlich:
Hash hat in vielen Aspekten Anwendungen, zum Beispiel haben unterschiedliche Werte unterschiedliche Hashwerte, aber The Der Hash-Algorithmus kann auch so gestaltet werden, dass ähnliche oder identische Werte ähnliche oder identische Hash-Werte haben. Das heißt, wenn zwei Objekte völlig unterschiedlich sind, dann sind ihre Hash-Werte völlig unterschiedlich; wenn zwei Objekte genau gleich sind, dann sind auch ihre Hash-Werte genau gleich, je ähnlicher die beiden Objekte sind. dann sind auch ihre Hashwerte völlig unterschiedlich, je ähnlicher sie sind. Dies ist eigentlich ein Ähnlichkeitsproblem, was bedeutet, dass diese Idee verallgemeinert und auf Ähnlichkeitsberechnungen (wie das Jaccard-Distanzproblem) und letztendlich auf genaue Werbeplatzierungen, Produktempfehlungen usw. angewendet werden kann.
Darüber hinaus kann beim Lastausgleich auch konsistentes Hashing angewendet werden. Um sicherzustellen, dass jeder Server den Lastdruck gleichmäßig verteilen kann, ist dies auch mit einem guten Hash-Algorithmus möglich.
Das obige ist der detaillierte Inhalt vonHash – Einführung in gängige Algorithmen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!