
Heim >Datenbank >MySQL-Tutorial >SQL Server-Datenträgeranforderungs-Timeout 833 Fehlerursachen und Lösungen_MsSql
SQL Server-Datenträgeranforderungs-Timeout 833 Fehlerursachen und Lösungen_MsSql

- 微波Original
- 2017-06-28 15:41:282496Durchsuche
In diesem Artikel werden hauptsächlich die Ursachen und Lösungen für den 833-Fehler des SQL Server-Festplattenanforderungs-Timeouts vorgestellt. Freunde in Not können sich darauf beziehen.
Kürzlich bin ich auf einen SQL Server-Server gestoßen, der extrem langsam reagierte und Client-Anfragen auftraten. Im Fehlerfall erscheint im Fehlerprotokoll der Datenbank eine Fehlermeldung, dass die Festplattenanforderung länger als 15 Sekunden dauert.
Ist es bei dieser Art von Problem ein Fehler des Speichersystems oder der Festplatte, ein Problem von SQL Server selbst oder wird es durch die Anwendung verursacht? Wie kann man es lösen?
In diesem Artikel wird eine einfache Analyse bestimmter Faktoren durchgeführt, die dieses Problem verursachen. Er kann jedoch nicht alle potenziellen Möglichkeiten abdecken. Daher muss bei ähnlichen Problemen eine spezifische Analyse durchgeführt werden.
Zeitüberschreitung bei Festplattenanforderung in SQL Server
Die englische Version der Fehlermeldung Fehlermeldung lautet wie folgt:
SQL Server hat festgestellt, dass %d E/A-Anforderungen länger als %d Sekunden für die Datei [%ls] in der Datenbank-ID %d benötigten. Das Betriebssystem-Dateihandle ist 0x%p 🎜 > Der Offset der letzten langen E/A ist: %#016I64x
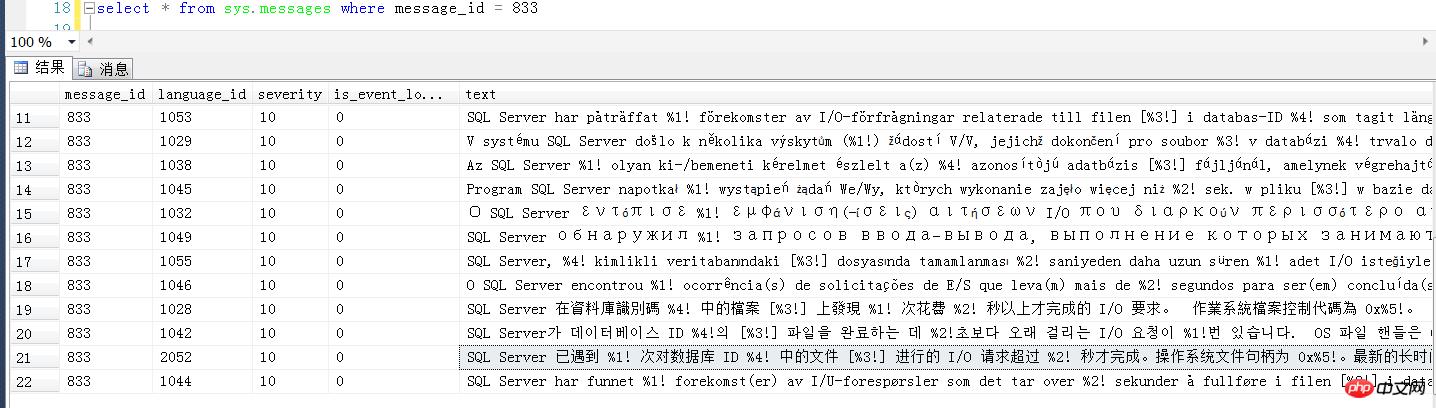
Da es sich bei dem vom Datenbankserver verwendeten Speicher um einen Hochleistungs-SAN-Speicher handelt, ist der Speicher als Dienst vorhanden und wird von mehreren Servern verwendet. Es ist unwahrscheinlich, dass ein bestimmtes Problem auftritt Wenn bei einem Server der Verdacht auf einen „Speicherfehler“ besteht, wird dies einfach als Speicherfehler betrachtet.
Was ist also der Grund?
Die Bedeutung des Datenbank-Engine-Fehlers 833
Schauen wir uns zunächst die spezifische Bedeutung dieses 833-Fehlers an. Ich werde ihn nicht selbst erklären . , es ist in diesem klassischen Buch sehr klar geschrieben. Kurz gesagt bedeutet dies, dass SQL Server beim Anfordern des Lesens und Schreibens der Festplatte auf eine ausgelastete Festplatte oder andere Faktoren stößt und den Vorgang länger als 15 Sekunden nicht abgeschlossen hat.
Zum Beispiel beim Lesen und Schreiben Daten müssen gelesen und auf die Festplatte geschrieben werden. Wenn eine Anfrage initiiert wird, die Festplatte jedoch ausgelastet ist oder andere Probleme vorliegen, ist es zu spät oder die Antwort erfolgt nicht rechtzeitig. Dies wird die Antwortzeit zweifellos erheblich beeinträchtigen des externen Servers von SQL Server. Das Obige ist eine einfache Analyse, da dieses Problem im Allgemeinen nicht auftritt und es unwahrscheinlich ist, dass das Speichersystem Probleme hat. Daher ist es sehr wahrscheinlich, dass die Faktoren des aktuellen Servers selbst lokalisiert werden. Ursachenanalyse
Ursachenanalyse
Da es sich um einen dedizierten SQL Server-Server handelt, gibt es keine Anfragen von anderen Anwendungen Dies hängt höchstwahrscheinlich mit der Anfrage an die SQLServer-Datenbank zusammen. Tatsächlich gab es Warnzeichen, bevor dieses Problem auftrat (CPU übersteigt selten 60 %, Speicher-PLE kann länger als 20 Minuten stabil sein, Festplatten-IO-Latenz ist niedrig usw.). ), aber gelegentlich kommt es für eine Weile zu Krämpfen
Wenn die Krämpfe auftreten, steigt die CPU auf etwa 80 %, der PLE des Speichers wird erheblich reduziert und die E/A-Verzögerung wird erheblich erhöht.
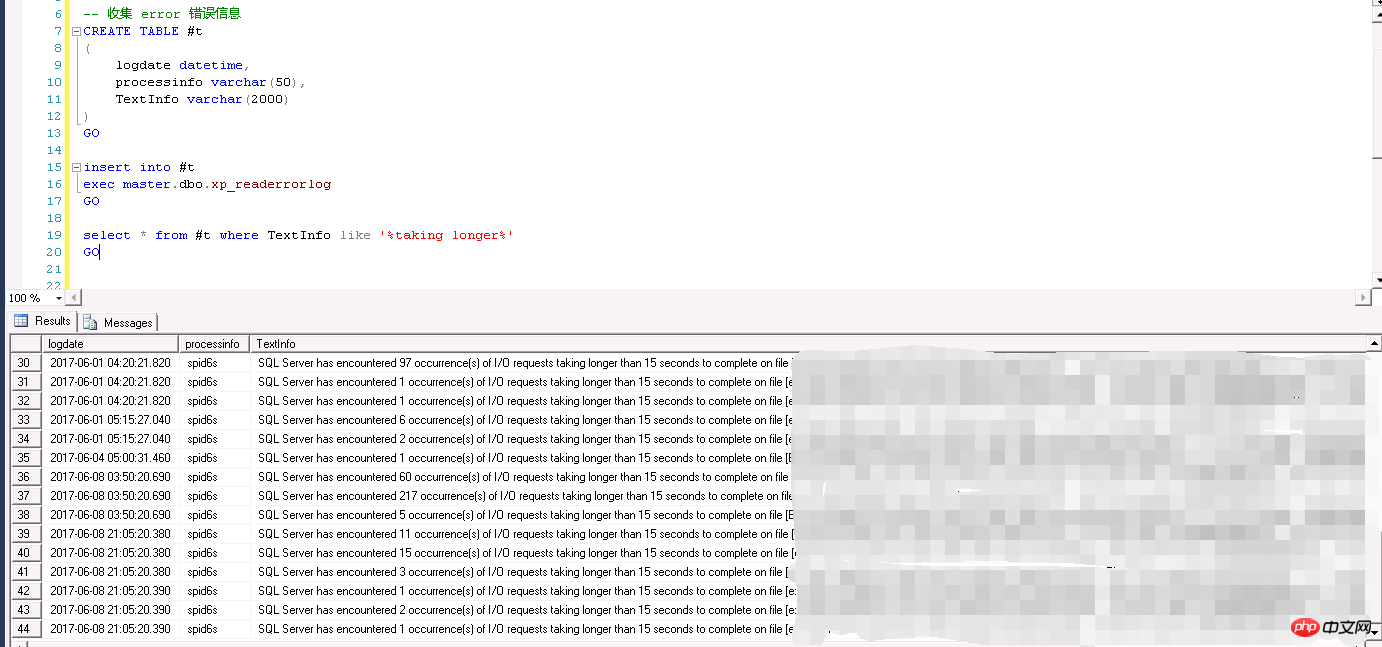
Jetzt können wir nur mit der
Sitzungvon SQL Server beginnen. Bei der Beobachtung der aktiven Sitzung in SQL Server haben wir festgestellt, dass die
Abfragezeitvon einem bestimmten Typ ist Die SQL-Anweisung ist sehr lang. Normalerweise wird diese Art von SQL innerhalb eines bestimmten Zeitraums relativ häufig ausgeführt.
Aber unter normalen Umständen ist die Ausführungseffizienz dieser Art von SQL immer noch relativ hoch. Warum wird sie plötzlich sehr niedrig?
Bei der Überprüfung des entsprechenden Ausführungsplans der aktiven Sitzung haben wir festgestellt, dass der Wartestatus dieser Art von aktiver Sitzung „E/A-Warten“ (PAGEIOLATCH_SH) lautet und die Ausführung von SQL völlig unerwartet ist.
Da ähnliche Abfragen relativ häufig ausgeführt werden, werden solche Sitzungen von verschiedenen Clients initiiert. Sobald die SQL-Ausführungseffizienz sinkt, sammelt sich eine große Anzahl aktiver Sitzungen auf dem Server an
Warum werden SQL-Anweisungen, die normalerweise gut ausgeführt werden, plötzlich sehr langsam?
Der Grund dafür ist, dass SQL Server an einem bestimmten Punkt automatisch die Aktualisierung der statistischen Informationen auslöst, aber das ist relativ große Tabelle, aber das Stichprobenverhältnis zum Aktualisieren der standardmäßigen statistischen Informationen reicht nicht aus. Wenn der Stichprobenprozentsatz nicht ausreicht, sind diese statistischen Informationen vollständig nicht verfügbar.
Sobald die automatische Erfassung statistischer Informationen abgeschlossen ist, wird basierend auf den aktuell erfassten statistischen Informationen eine Methode ausgegeben, die seiner Meinung nach effizient ist (Tabellenscan statt Indexsuche). Methode ist nicht sinnvoll.
Dies führt dazu, dass das entsprechende SQL einen unangemessenen Ausführungsplan zum Implementieren der Abfrage verwendet und gleichzeitig eine Überlastung der Sitzung verursacht. Der Client sendet eine große Anzahl von Sitzungen und führt diese langsam und ineffizient aus Weg. .
Dadurch steigt die CPU-Leistung, die E/A-Latenz nimmt zu und der PLE des Speichers nimmt erheblich ab.
Daraus ist nicht schwer zu verstehen, dass Dutzende abfragende Sitzungen hektisch und unangemessen Anfragen an die Festplatte stellen. Die Festplatte ist mit Datenanfragen von aktiven Sitzungen beschäftigt und kann aufgrund des automatischen Wachstums nicht antworten Anfragen nach Daten oder Index-Dateien verursachen das eingangs erwähnte Problem.
Schließlich wurde das Problem durch Indexrekonstruktion gelöst (Förderung der Aktualisierung statistischer Informationen, natürlich ist auch eine reine Aktualisierung statistischer Informationen möglich). Zur langfristigen Prävention ist es erforderlich, einen Job zur künstlichen Definition des Schwellenwerts zu arrangieren Wert und Stichprobenprozentsatz der Aktualisierung statistischer Informationen.
Zusammenfassung:
Viele Probleme auf dem Datenbankserver sind ein Kettenreaktionsprozess, der einigen der beobachteten Phänomene entspricht Seien Sie so, wie es auf den ersten Blick scheint (Zeitüberschreitung bei der Festplattenanforderung, liegt das Problem im Speicher?)
Eine professionelle Position muss über professionelle Qualitäten verfügen. Beispielsweise dachte der DBA zunächst fälschlicherweise, dass es sich um ein Speicherproblem handelte, und der Speicheringenieur Ich dachte, es handele sich um ein Serverproblem. Es ist ungewöhnlich, dass der Speicher voll ist usw. Tatsächlich ist dies nicht die Hauptursache des Problems.
Wenn wir mit einem Problem konfrontiert werden, müssen wir es bis zu seiner Quelle zurückverfolgen und die grundlegendste Ursache herausfinden. Dies ist der Schlüssel zur Lösung des Problems.
Das obige ist der detaillierte Inhalt vonSQL Server-Datenträgeranforderungs-Timeout 833 Fehlerursachen und Lösungen_MsSql. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!