
Heim >Backend-Entwicklung >Python-Tutorial >Detaillierte Erläuterung der Big-Data-Verarbeitung in Python
Detaillierte Erläuterung der Big-Data-Verarbeitung in Python

- 零下一度Original
- 2017-06-27 10:37:395070Durchsuche
Teilen

Wissenspunkte:
Paketzerlegungszeit schmieren |. POSIXlt
Entscheidungsbaumklassifizierung und Zufallswaldvorhersage verwenden
Logarithmen verwenden für Passform und Exp-Funktion zur Wiederherstellung
Der Trainingssatz stammt aus den Fahrradmietdaten im Kaggle Washington Bicycle Sharing Program und die Beziehung zwischen gemeinsam genutzten Fahrrädern, Wetter, Zeit usw. wird analysiert. Der Datensatz umfasst insgesamt 11 Variablen und mehr als 10.000 Datenzeilen.
Werfen wir zunächst einen Blick auf die offiziellen Daten. Es gibt zwei Tabellen, beide für 2011-2012. Der Unterschied besteht darin, dass die Testdatei alle Daten jedes Monats enthält ist nicht registrierte Benutzer und zufällige Benutzer. Die Train-Datei hat nur 1–20 Tage pro Monat, es gibt jedoch zwei Arten von Benutzern.
Lösung: Vervollständigen Sie die Anzahl der Benutzer von 21 bis 30 in der Train-Datei. Das Bewertungskriterium ist der Vergleich von Prognosen mit tatsächlichen Mengen.

Laden Sie zuerst die Dateien und Pakete
library(lubridate)library(randomForest)library(readr)setwd("E:")
data<-read_csv("train.csv")head(data)Hier bin ich auf eine Falle gestoßen, als ich The verwendet habe Die Standarddatei read.csv der R-Sprache kann das korrekte Dateiformat nicht lesen. Noch schlimmer ist es, wenn sie durch xlsx ersetzt wird. Es wird immer eine seltsame Zahl wie 43045. Ich habe as.Date schon einmal versucht und es kann korrekt konvertiert werden, aber dieses Mal kann ich nur Zeitstempel verwenden, weil es Minuten und Sekunden gibt, aber das Ergebnis ist auch nicht gut.
Schließlich habe ich das Paket „readr“ heruntergeladen und die Anweisung read_csv verwendet, um es reibungslos zu interpretieren.
Da der Testtermin vollständiger ist als der Zugtermin, aber die Anzahl der Nutzer fehlt, müssen Zug und Test zusammengelegt werden.
test$registered=0test$casual=0test$count=0 data<-rbind(train,test)
Zeit extrahieren: Sie können den Zeitstempel verwenden. Die Zeit ist hier relativ einfach, es handelt sich um die Anzahl der Stunden, sodass Sie die Zeichenfolge auch direkt abfangen können.
data$hour1<-substr(data$datetime,12,13) table(data$hour1)
Zählen Sie die Gesamtnutzung pro Stunde, es ist so (warum ist es so ordentlich):

Der nächste Schritt besteht darin, Boxplots zu verwenden, um die Beziehung zwischen Benutzern, Uhrzeit und Wochentagen anzuzeigen. Warum Boxplot anstelle von Hist-Histogramm verwenden? Da Boxplot einen diskreten Punktausdruck hat, wird der Logarithmus verwendet, um die Anpassung zu finden
Wie aus der Abbildung ersichtlich ist, ist die Nutzung durch registrierte Benutzer und nicht registrierte Benutzer zeitlich begrenzt Die Zeit macht einen großen Unterschied.
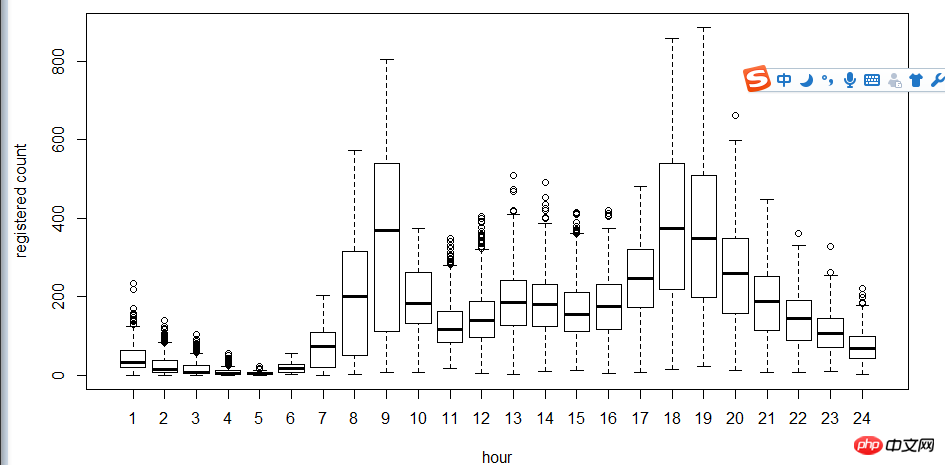
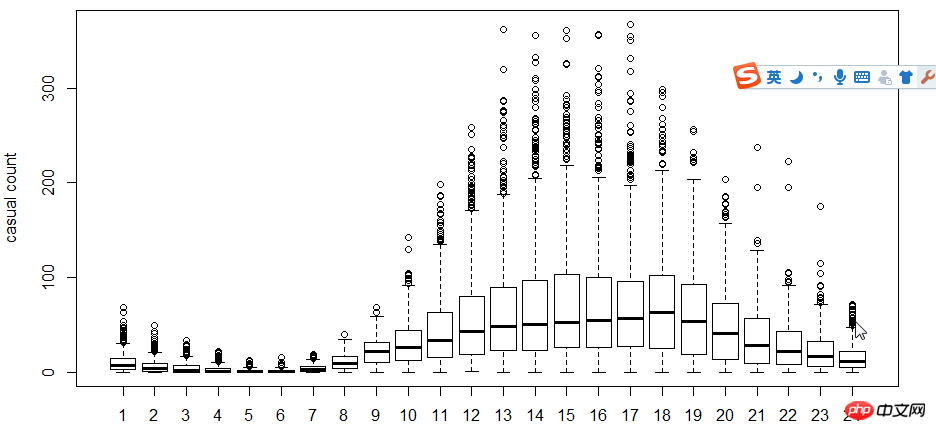
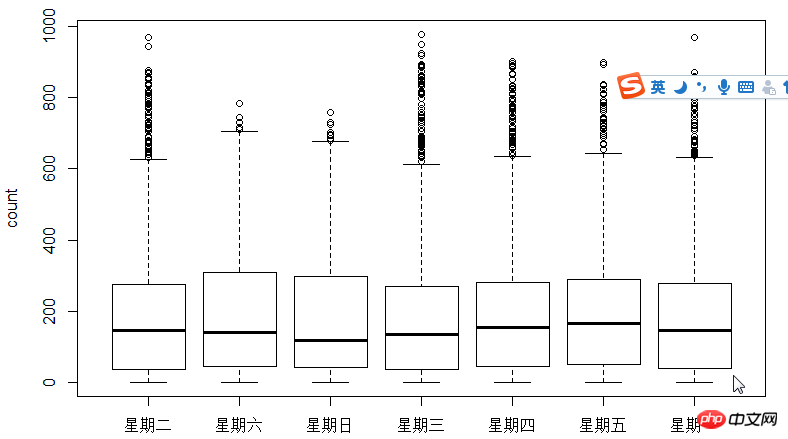
Als nächstes verwenden Sie den Korrelationskoeffizienten cor, um die Beziehung zwischen Benutzer, Temperatur, wahrgenommener Temperatur, Luftfeuchtigkeit und Windgeschwindigkeit.
Korrelationskoeffizient: ein lineares Assoziationsmaß zwischen Variablen, das den Grad der Korrelation zwischen verschiedenen Daten testet.
Der Wertebereich ist [-1, 1]. Je näher an 0, desto weniger relevant ist er.
Aus den Berechnungsergebnissen geht hervor, dass die Anzahl der Nutzer negativ mit der Windgeschwindigkeit korreliert, die einen größeren Einfluss hat als die Temperatur.

Der nächste Schritt besteht darin, Faktoren wie Zeit mithilfe von Entscheidungsbäumen zu klassifizieren und dann zufällige Wälder zur Vorhersage zu verwenden. Algorithmen für Zufallswälder und Entscheidungsbäume. Es hört sich sehr fortgeschritten an, wird aber mittlerweile sehr häufig verwendet, Sie müssen es also lernen.
Das Entscheidungsbaummodell ist ein einfacher und benutzerfreundlicher nichtparametrischer Klassifikator. Es erfordert keine apriorischen Annahmen über die Daten, die Berechnung ist schnell, die Ergebnisse sind leicht zu interpretieren, und es ist robust und hat keine Angst vor verrauschten Daten und fehlenden Daten.
Die grundlegenden Berechnungsschritte des Entscheidungsbaummodells sind wie folgt: Wählen Sie zunächst eine von n unabhängigen Variablen aus, finden Sie den besten Teilungspunkt und teilen Sie die Daten in zwei Gruppen auf. Wiederholen Sie für die gruppierten Daten die obigen Schritte, bis eine bestimmte Bedingung erfüllt ist.
Es gibt drei wichtige Probleme, die bei der Entscheidungsbaummodellierung gelöst werden müssen:
Wie werden die unabhängigen Variablen ausgewählt?
Wie wird der Teilungspunkt ausgewählt?
Bestimmen Sie die Bedingungen zum Stoppen der Teilung.
Entscheidungsbaum der registrierten Benutzer und Stunden erstellen,
train$hour1<-as.integer(train$hour1)d<-rpart(registered~hour1,data=train)rpart.plot(d)
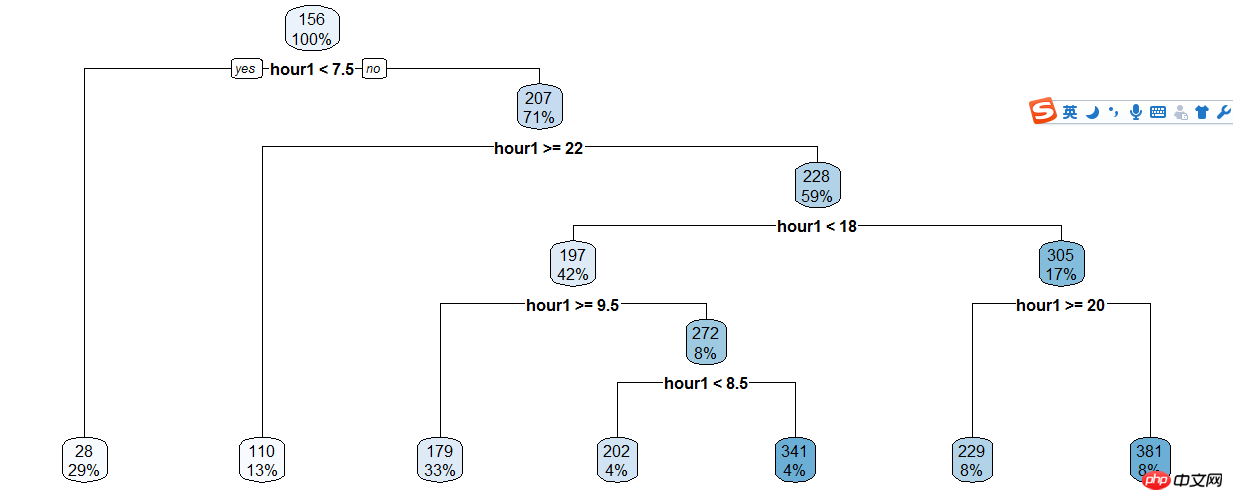
Dann basierend auf dem Entscheidungsbaum Die Ergebnisse werden manuell klassifiziert, sodass der Code immer noch voll ist...
train$hour1<-as.integer(train$hour1)data$dp_reg=0data$dp_reg[data$hour1<7.5]=1data$dp_reg[data$hour1>=22]=2data$dp_reg[data$hour1>=9.5 & data$hour1<18]=3data$dp_reg[data$hour1>=7.5 & data$hour1<18]=4data$dp_reg[data$hour1>=8.5 & data$hour1<18]=5data$dp_reg[data$hour1>=20 & data$hour1<20]=6data$dp_reg[data$hour1>=18 & data$hour1<20]=7
Erstellen Sie auf ähnliche Weise Entscheidungsbäume wie (Stunde | Temperatur).
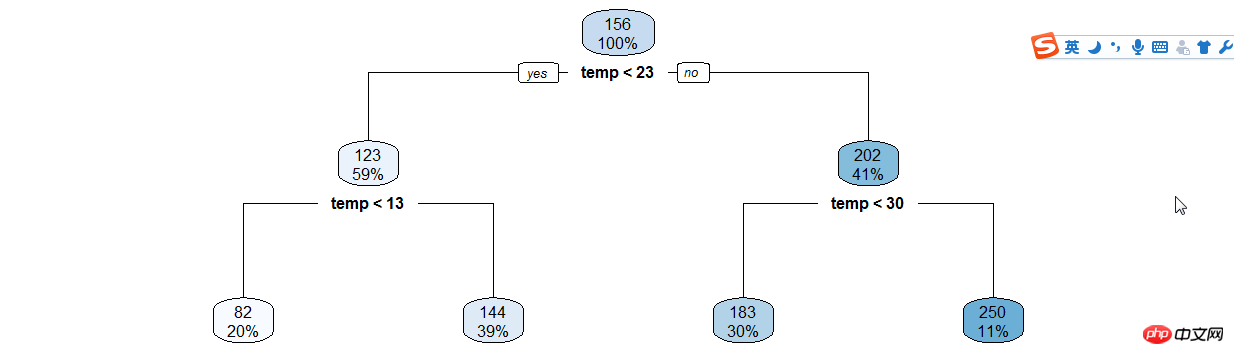
年份月份,周末假日等手动分类
data$year_part=0data$month<-month(data$datatime)data$year_part[data$year=='2011']=1data$year_part[data$year=='2011' & data$month>3]=2data$year_part[data$year=='2011' & data$month>6]=3data$year_part[data$year=='2011' & data$month>9]=4
data$day_type=""data$day_type[data$holiday==0 & data$workingday==0]="weekend"data$day_type[data$holiday==1]="holiday"data$day_type[data$holiday==0 & data$workingday==1]="working day"data$weekend=0data$weekend[data$day=="Sunday"|data$day=="Saturday"]=1
接下来用随机森林语句预测
在机器学习中,随机森林是一个包含多个决策树的分类器, 并且其输出的类别是由个别树输出的类别的众数而定。
随机森林中的子树的每一个分裂过程并未用到所有的待选特征,而是从所有的待选特征中随机选取一定的特征,再在其中选取最优的特征。这样决策树都能够彼此不同,提升系统的多样性,从而提升分类性能。
ntree指定随机森林所包含的决策树数目,默认为500,通常在性能允许的情况下越大越好;
mtry指定节点中用于二叉树的变量个数,默认情况下数据集变量个数的二次方根(分类模型)或三分之一(预测模型)。一般是需要进行人为的逐次挑选,确定最佳的m值—摘自datacruiser笔记。这里我主要学习,所以虽然有10000多数据集,但也只定了500。就这500我的小电脑也跑了半天。
train<-dataset.seed(1234) train$logreg<-log(train$registered+1)test$logcas<-log(train$casual+1) fit1<-randomForest(logreg~hour1+workingday+day+holiday+day_type+temp_reg+humidity+atemp+windspeed+season+weather+dp_reg+weekend+year+year_part,train,importance=TRUE,ntree=250) pred1<-predict(fit1,train) train$logreg<-pred1
这里不知道怎么回事,我的day和day_part加进去就报错,只有删掉这两个变量计算,还要研究修补。
然后用exp函数还原
train$registered<-exp(train$logreg)-1 train$casual<-exp(train$logcas)-1 train$count<-test$casual+train$registered
最后把20日后的日期截出来,写入新的csv文件上传。
train2<-train[as.integer(day(data$datetime))>=20,]submit_final<-data.frame(datetime=test$datetime,count=test$count)write.csv(submit_final,"submit_final.csv",row.names=F)
大功告成!
github代码加群
原来的示例是炼数成金网站的kaggle课程第二节,基本按照视频的思路。因为课程没有源代码,所以要自己修补运行完整。历时两三天总算把这个功课做完了。下面要修正的有:
好好理解三个知识点(lubridate包/POSIXlt,log线性,决策树和随机森林);
用WOE和IV代替cor函数分析相关关系;
用其他图形展现的手段分析
随机树变量重新测试学习过程中遇到什么问题或者想获取学习资源的话,欢迎加入学习交流群
626062078,我们一起学Python!
完成了一个“浩大完整”的数据分析,还是很有成就感的!
Das obige ist der detaillierte Inhalt vonDetaillierte Erläuterung der Big-Data-Verarbeitung in Python. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!