
Heim >Backend-Entwicklung >Python-Tutorial >Module der Python-Serie 5
Module der Python-Serie 5
- 巴扎黑Original
- 2017-06-23 11:46:541456Durchsuche
模块
1. 模块的分类
模块,又称构件,是能够单独命名并独立地完成一定功能的程序语句的集合(即程序代码和数据结构的集合体)。
(1)自定义模块
自己定义的一些可以独立完成某个功能的一段程序语句,可以是一个文件,也可以是一个目录。
(2)第三方模块
是由其他人写的一些程序语句,我们可以用它来实现自己的功能。
(3)内置模块
是由python自己带的一些实现某种特定功能的组件。
2. 模块的导入
(1)python默认的模块寻找路径
当开始导入一个模快的时候,python默认的会先找到第一个路径去看一下是否有这个模块,如果没有接着再到下一个路径中去找,知道最后一个路径。
从这个路径中我们可以知道,只要我们的模块在这个路径中,就可以被导入。


C:\Users\zhou\PycharmProjects\fullstack2\6_19\test C:\python_software\python3.5.2\python35.zip C:\python_software\python3.5.2\DLLs C:\python_software\python3.5.2\lib C:\python_software\python3.5.2C:\python_software\python3.5.2\lib\site-packages
(2)自定义模块的导入
f35d6e602fd7d0f0edfa6f7d103c1b57. 自定义模块在python的默认路径中
第一种方式,导入文件,然后文件去调用函数
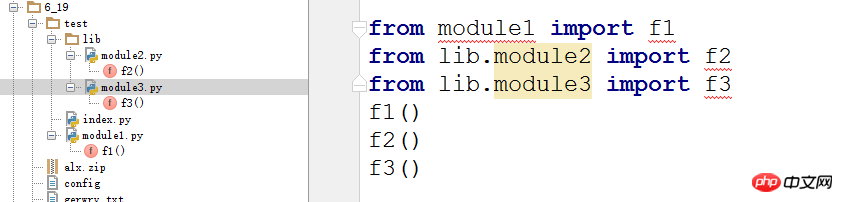
下图左边的为目录树,lib,index和module1在同一目录下,module2,module3在lib目录下,右边的为index文件导入模块的方法。
到操作某个文件的时候, 默认的就会把此文件的路径加入默认路径中。
* module1可以直接导入,因为与index在同一文件夹下
* module2和module3要通过以下方式进行导入,因为他们不在一个目录中,要首先找到与index同级的目录才可以

第二种方式,导入函数
直接调用函数
lib.module2:默认调用函数时,目录之间用点去分割
2cc198a1d5eb0d3eb508d858c9f5cbdb. 自定义模块不在python的默认路径中
我们需要把自定义模块的路径加入到python默认的路径中,然后就可以像上面的的方法一样进行调用了。
# sys模块在后面会有说明,此处的append是把D:路径加入# 然后D盘的所有模块就可以导入了import sys
sys.path.append('D:')for i in sys.path:print(i)(3)内置模块和第三方模块的导入
内置模块的和第三方模块的导入很简单,直接用import 模块名称 就可以了,因为内置模块和自定义模块的的路径其实就是在python的默认寻找路径中,所以可以直接用import导入。
第三方模块的安装:
f35d6e602fd7d0f0edfa6f7d103c1b57. 安装管理工具
pip install requests
2cc198a1d5eb0d3eb508d858c9f5cbdb. 下载源码安装
一. os
1. os模块的作用
os(operating system)操作系统的意思,所以,从名字就可以看出来,此模块主要是和系统级别相关的一些功能。
2. os模块的方法


1 os.join(路径1, 路径2) 把这两个路径合成一个路径 2 # 例题: 3 a = os.path.join('zhou\\PycharmProjects\\fullstack2\\6_1\\6_10','test1.py') 4 print(a) 5 # 结果: 6 zhou\PycharmProjects\fullstack2\6_1\6_10\test1.py 7 8 os.state(路径): 显示当前路径的一些状态信息 如: 大小,uid,gid,修改时间,创建时间 9 os.getcwd(): 不需要参数,就是显示出当前文件所在目录10 os.mkdir(路径, 权限) windows下创建目录,注意是双斜杠11 12 os.rmdir() windows下删除目录, 如果目录不为空,则不能删除13 # 例题: 14 os.mkdir('C:\\Users\\zhou\\PycharmProjects\\fullstack2\\6_1', 640)15 os.rmdir('C:\\Users\\zhou\\PycharmProjects\\fullstack2\\6_1')16 17 os.makedir() 递归创建目录18 os.removedir() 递归删除目录19 # 例题: 6_1目录不存在,递归创建,然后remove递归删除20 os.makedirs('C:\\Users\\zhou\\PycharmProjects\\fullstack2\\6_1\\6_10', 640)21 os.removedirs('C:\\Users\\zhou\\PycharmProjects\\fullstack2\\6_1\\6_10')22 23 os.listdir(路径): 列出当前目录下的所有内容,相当于list24 os.chdir(路径) 改变当前路径,相当于cd25 # 例题:26 os.chdir('C:\\Users\\zhou\\PycharmProjects\\fullstack2\\6_1\\6_10')27 print(os.getcwd())28 29 os.curdir 返回到当前路径30 os.pardir 返回到父目录31 # 例题:32 print(os.curdir)----> .33 print(os.pardir)----> ..34 35 os.rename(旧文件的名字,新文件的名字) 重命名36 # 例题:37 os.rename('C:\\Users\\zhou\\PycharmProjects\\fullstack2\\6_1\\6_10\\test1','C:\\Users\\zhou\\PycharmProjects\\fullstack2\\6_1\\6_10\\test1.py')38 39 os.name 当前操作系统的名称 windows下为"nt", linux下为"posix"40 os.pathsep 用来分割路径的操作符 ";"41 os.linesep 操作系统的换行符,windows下为"\t\n", linux下为"\n"42 os.sep 操作系统特定的路径分隔符,windows下为"\", linux下为"/"43 os.environ 当前操作系统的环境变量44 # 例题:45 print(os.sep)
46 print(os.linesep) 在win下显示为两行空格(此处感觉有点奇怪,按理说应该是一行才对)47 print(os.pathsep)48 print(os.name)49 print(os.environ)50 51 os.basename() 得到路径的基名52 os.dirname() 得到路径的父目录53 os.path.exists() 判断路径是否存在54 os.path.split() 把路径的基名和父目录分割开来55 os.path.abspath() 得到他的绝对路径56 os.path.isabs() 判断是不是绝对路径,如果是返回True,如果不是返回Flase57 # 例题:58 a = os.path.dirname('C:\\Users\\zhou\\PycharmProjects\\fullstack2\\6_1\\6_10')59 b = os.path.basename('C:\\Users\\zhou\\PycharmProjects\\fullstack2\\6_1\\6_10')60 c = os.path.exists('C:\\Users\\zhou\\PycharmProjects\\fullstack2\\6_1\\6_10')61 d = os.path.split('C:\\Users\\zhou\\PycharmProjects\\fullstack2\\6_1\\6_10')62 e = os.path.abspath("test.py")63 64 print(a)65 print(b)66 print(c)67 print(d)68 print(e)69 # 结果:70 C:\Users\zhou\PycharmProjects\fullstack2\6_171 6_1072 True73 ('C:\\Users\\zhou\\PycharmProjects\\fullstack2\\6_1', '6_10')74 C:\Users\zhou\PycharmProjects\fullstack2\6_19\test.py75 76 os.path.isfile() 判断路径是不是一个文件77 os.path.isdir() 判断路径是不是一个目录78 os.path.getatime() 最后存取时间79 os.path.getctime() 最后创建时间80 os.path.getmtime() 最后修改时间81 # 例题:82 f = os.path.isfile('C:\\Users\\zhou\\PycharmProjects\\fullstack2\\6_1\\6_10')83 g = os.path.isdir('C:\\Users\\zhou\\PycharmProjects\\fullstack2\\6_1\\6_10')84 h = os.path.getatime('C:\\Users\\zhou\\PycharmProjects\\fullstack2\\6_1\\6_10')85 i = os.path.getctime('C:\\Users\\zhou\\PycharmProjects\\fullstack2\\6_1\\6_10')86 j = os.path.getmtime('C:\\Users\\zhou\\PycharmProjects\\fullstack2\\6_1\\6_10')87 print(f)88 print(g)89 print(h)90 print(i)91 print(j)92 # 结果:93 False94 True95 1497872812.446774596 1497864841.851299397 1497872812.4467745二. sys
1. sys模块的作用
sys(system)系统的意思,这个模块可供访问由解释器使用或维护的变量和与解释器进行交互的函数。
2. sys模块的使用方法
sys.argv 传入文件的参数 sys.path 默认的模块查询目录 sys.version Python的版本 sys.exit() 退出程序 sys.platform 使用的平台----->win32 sys.stdout.write() 打印不换行
三. json
1. json模块的作用
当我们从网上的到一个网页的时候,一般会得到三种数据(从网站上得到的数据最终都是字符串)
f35d6e602fd7d0f0edfa6f7d103c1b57. html html我们都知道是一种标记语言,具有固定的格式。
2cc198a1d5eb0d3eb508d858c9f5cbdb. json json不是一种语言,但是它具有固定的格式,就是类似字典,元组,列表的格式的字符串,我们可以功过json让其进行相互转换
5bdf4c78156c7953567bb5a0aef2fc53. xml xml是另一种语言,类似于html,也具备固定的格式,有tag,attitude,text等。可以通过xml进行解析
2. json模块的使用方法
1 json.loads() 将字符串格式的字典和元组转换成对应的字典或者元组 2 # 例题: 3 import json 4 s1 = '''{ 5 "name":"hu", 6 "age":1, 7 "gender":"man" 8 }''' 9 a = json.loads(s1)10 print(a, type(a))11 # 结果:12 {'name': 'hu', 'age': 1, 'gender': 'man'} 7b39bef7adea3541ce64f1957f7818aa13 # 注意s1中不能出现单引号14 15 json.dumps() 将字典或者列表转换成字符串16 17 # 例题:18 import json19 s2 = {'age': 1, 'gender': 'man', 'name': 'hu'}20 a = json.dumps(s2)21 print(a, type(a))
22 # 结果: 23 {"gender": "man", "age": 1, "name": "hu"} ad5244f1b92be06a62230599fced433724 25 26 json.dump() 写入中文会是乱码,暂时没有找到转换字符的地方27 # 例题:28 s2 = {29 "name":'zhou',30 "age":12,31 "gender":"woman"32 }33 import json34 json.dump(s2, open('test1', 'a', encoding='utf-8'))35 # 结果: 追加到test1的内容36 {37 "name":"hu",38 "age":1,39 "gender":"man"40 }{"age": 12, "name": "zhou", "gender": "woman"}41 42 43 44 json.load() 将文件中的字符串转换成字典类型45 # 例题: test1 文件中的内容就是下面的字典46 import json47 a = json.load(open('test1', 'r', encoding='utf-8'))48 print(a, type(a))49 # 结果:50 {'name': 'hu', 'gender': 'man', 'age': 1} 7b39bef7adea3541ce64f1957f7818aa 四. re
1. re模块的作用
re是正则表达式,主要用来对字符串的匹配
2. re模块的使用方法
re.match 只在开头进行匹配
re.search 只匹配第一次匹配到的
re.findall 匹配所有匹配到的


# 由结果我们可知,# 因为开头没有hu,所以a的返回值为None# 因为search只会匹配第一个,所以只显示了一次hu# 因为findall会匹配所有的,所以显示了两次import re
s1 = "hello, hu, hhh, hu"a = re.match("hu", s1)
b = re.search("hu", s1).group()
c = re.findall("hu", s1)print(a)print(b)print(c)
结果:
None
hu
['hu', 'hu']分组的概念,如果没有分组,默认的groups和groupdict都是空
group 默认所有的都会放入group中
groups 只有分组的才会放在groups
groupdict 只有是字典的才会放在groupdict


# ?P753813ba5022b5ff08e82adc99414c14是字典的写入形式# 从结果我们可以看出来,groups放的是他的组的信息,和字典没有关系# 而groupdict放的是字典,和groups也没有关系import re
s1 = "huello, hu, hhh, hu"a1 = re.match("(?P8a11bc632ea32a57b3e3693c7987c420h)(u)", s1).group()
a2 = re.match("(?P8a11bc632ea32a57b3e3693c7987c420h)(u)", s1).groups()
a3 = re.match("(?P8a11bc632ea32a57b3e3693c7987c420h)(u)", s1).groupdict()print(a1)print(a2)print(a3)
结果:
hu
('h', 'u')
{'name': 'h'}

# 因为他找的只是第一个,所以和match没有太大的区别,# 他们的结果也是一样的import re
s1 = "huello, hu, hhh, hu"a1 = re.search("(?P8a11bc632ea32a57b3e3693c7987c420h)(u)", s1).group()
a2 = re.search("(?P8a11bc632ea32a57b3e3693c7987c420h)(u)", s1).groups()
a3 = re.search("(?P8a11bc632ea32a57b3e3693c7987c420h)(u)", s1).groupdict()print(a1)print(a2)print(a3)

# findall这个方法本深并没有什么分组不分组的,只是如果有小括号,他只会显示小括号里面的内容,并把他们组合成列表import re
s1 = "huello, hu, hhh, hu"a1 = re.findall("(h)(u)", s1)print(a1)
结果:
[('h', 'u'), ('h', 'u'), ('h', 'u')]

import re
s1 = "huello, hu, hhh, hu"# 只要遇到“hu”字符串,就会进行切分,并且删除此字符串a1 = re.split('hu', s1)# 遇到第一个“hu”字符串,进行切分,并且删除此字符串,把字符串分割成两块a2 = re.split('hu', s1, 1)## 遇到第一个“hu”字符串,进行切分,不会删除此字符串,把字符串分割成三块a3 = re.split('(hu)', s1, 1)print(a1)print(a2)print(a3)
结果:
['', 'ello, ', ', hhh, ', '']
['', 'ello, hu, hhh, hu']
['', 'hu', 'ello, hu, hhh, hu']五. random
1. random模块的作用
random就是为了生成一个随机数
2. random的应用
f35d6e602fd7d0f0edfa6f7d103c1b57. 验证码的生成
1 # 导入random模块 2 # 调用random.randrange()模块生成一个随机数 3 # 拼接字符串 4 5 import random 6 yanzhengma = str() 7 for i in range(6): 8 ran = random.randrange(0, 4) 9 if ran == 0 or ran == 2:10 yanzhengma += chr(random.randrange(65, 91))11 else:12 yanzhengma += str(random.randrange(0, 10))13 print(yanzhengma)
六. hashlib
1. hashlib模块的作用
hashlib主要用来给字符串进行加密。加密的方法有md5, sha1,sha224, sha256,sha384,sha512
md5算法是不能反解的
2. hashlib模块的应用
f35d6e602fd7d0f0edfa6f7d103c1b57. md5的应用
加盐是什么呢?
虽然说md5加密不能反解,但是它只要是同一个密码,用md5生成之后还是一样的,因此,这样的密码还是不安全的,因此我们需要在原来的密码基础上在加上一段只有自己知道的字符,然后生成密码,这样就算是破解了也不会知道自己的密码(这就是我们所说的加盐)
1 import hashlib 2 # 创建对象 加盐 3 hash = hashlib.md5(bytes('lljeg', encoding='utf-8')) 4 # 生成密码 5 hash.update(bytes('hu', encoding='utf-8')) 6 # 显示密码 7 print(hash.hexdigest()) 8 9 #18bd9197cb1d833bc352f47535c0032010 #498e327141378fa4d31e5b4c6543db22七. getpass
1. getpass 模块的作用
getpass主要用来在输入密码的时候不显示,防止密码泄露的。
2. getpass的应用
f35d6e602fd7d0f0edfa6f7d103c1b57. getpass密码隐藏输入
# 导入getpass模块,然后使用getpass方法,就可以使密码隐藏输入# 注意的是有时候getpass模块在pycharm是没有办法使用的,只能在终端使用>>> import getpass>>> a = getpass.getpass("Password: ")
Password:>>> print(a)
legj>>>八. zipfile
1. zipfile模块的作用
zipfile主要用于对文件的压缩和解压。
2. zipfile模块的使用
f35d6e602fd7d0f0edfa6f7d103c1b57. 解压
= zipfile.ZipFile(,
2cc198a1d5eb0d3eb508d858c9f5cbdb. 压缩
import zipfile# 创建一个压缩包,以追加的方式写入压缩包zi = zipfile.ZipFile('我的压缩包.zip', 'a')# 压缩一个文件到压缩包中zi.write('config')
zi.write('log')# 关闭压缩文件zi.close()九. subporcess
1. subprocess模块的作用
subprocess专门用于python执行系统命令
2. subprocess模块的使用方法
1 # 简单命令 2 call() 输入是windows终端命令,当命令执行成功,返回1,结果直接打印在终端上(暂时不太清楚和check_all的区别) 3 check_call() 输入的是windows终端命令,当命令执行成功,返回1,否则返回0
4 check_output() 输入的是windows终端命令,会把结果返回给一个变量
5 # 例题: 6 a = subprocess.call('ipconfig', shell=True) 7 b = subprocess.check_call('ipconfig') 8 c = subprocess.check_output('ipconfig') 9 print(a, b, c)10 # 结果: 11 只有c会有返回值,a和b都是0
12 #复杂命令13 subprocess.Popen 创建一个可执行复杂命令的对象14 subprocess.PIPE 开辟标准输入输出的管道15 # 例题:16 cmd = subprocess.Popen("python", stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE, universal_newlines=True)17 18 cmd.stdin.write('print(1)\n')19 cmd.stdin.write('print(2)')20 cmd.stdin.close()21 22 a = cmd.communicate()23 print(a, type(a))24 25 # 结果:26 ('1\n2\n', '') 3b51453758f94d168c0dc82c1d613570十. logging
1. logging模块的作用
logging模块主要用来规范写入日志的格式和写入日志的时间,防止多线程同时修改日志,从而导致日志不安全。
2. logging的使用方法
# 日志级别CRITICAL = 50FATAL = CRITICAL
ERROR = 40WARNING = 30WARN = WARNING
INFO = 20DEBUG = 10NOTSET = 0
写入同一个日志文件中 logging.basicConfig# 例子:import logging
logging.basicConfig(
filename='logging',
format = '%(asctime)s - %(name)s - %(levelname)s - %(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
level=logging.INFO
)
logging.error('sss')# 结果:2017-06-19 22:18:41 PM - root - ERROR - 652f2a0e4f7d7f1c776c56966f8747f3: 1111写入不同的日志文件中
logging.FileHandler 定义日志文件
logging.Formatter 定义日志文件的格式
logging.Logger 定义日志文件的级别
log.addHandler 添加日志文件
log.critical 写入日志文件# 例子2:import logging# 定义格式file_1 = logging.FileHandler('log1', 'a')
fmt1 = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(module)s: %(message)s')
file_1.setFormatter(fmt1)
file_2 = logging.FileHandler('log2', 'a')
fmt2 = logging.Formatter()
file_2.setFormatter(fmt2)#定义级别log = logging.Logger('lsl', logging.INFO)
log.addHandler(file_1)
log.addHandler(file_2)
log.critical('kjjjj')十一. xml
1. xml模块的作用
由上面的介绍可知,我们去访问一下网站的时候,一般会返回给我们是三种数据,一个就是html,一个是json,一个就是xml,其实xml本身是一门语言,他具有特定的格式,比如tag(标签),attribute(属性),text(内容),基本上也就是这样的格式。下面的就是这样的一种xml语言


#a8093152e673feb7aba1828c43532094中间的第一个单词被称为tag,tag后面的都是属性# 没有被a8093152e673feb7aba1828c43532094包裹的就是text1d029f6197b5a3eb8a3fdf0a088ddf55 651698deed2017662f01cab654d75346 a021580c9ab671ec95fc2f263f4a36a22df33aed4b2ff5c2ecbdfe19bf9c5bc79 3bbe66da62dec7e69c0050064bde4a4e2022a7352e740fd5758807b26011438f1c65 5cf2884fb54649b58103398da0ce831f14110af7d493c36d8fe9866b77c555ace84dd 1dc08c13e298f753c6e877c077b8e9c4 6035e1a3e6ce9499d7f65bd05787aaf9 a021580c9ab671ec95fc2f263f4a36a22df33aed4b2ff5c2ecbdfe19bf9c5bc79 3bbe66da62dec7e69c0050064bde4a4e2022a7352e740fd5758807b26011438f1c65 5cf2884fb54649b58103398da0ce831f14110af7d493c36d8fe9866b77c555ace84dd 1dc08c13e298f753c6e877c077b8e9c4 e573d9dc342ccd201b13bcad5d5d50f8 a021580c9ab671ec95fc2f263f4a36a22df33aed4b2ff5c2ecbdfe19bf9c5bc79 3bbe66da62dec7e69c0050064bde4a4e2022a7352e740fd5758807b26011438f1c65 5cf2884fb54649b58103398da0ce831f14110af7d493c36d8fe9866b77c555ace84dd 1dc08c13e298f753c6e877c077b8e9c4 598ede4b0f3f063f2ec1163969584d03 598ede4b0f3f063f2ec1163969584d03 598ede4b0f3f063f2ec1163969584d03 bb5d9437cdfca4f6b8bb6682365dc866 bd25e8202dcb51cbb259159240db0eed d98ca7951c814b9263d12f482df06c69 bb5d9437cdfca4f6b8bb6682365dc866 bd25e8202dcb51cbb259159240db0eed d98ca7951c814b9263d12f482df06c69 2f960bd95a3f0b5c0a1c2065cc7483fd 00868af8e8435b6137e1dab17a98b716 b37ee3a665ec2d57188cdb88849d5246 07b4fdd0136efc154b4b9d48cfcbbb9d
2. xml模块的使用方法
f35d6e602fd7d0f0edfa6f7d103c1b57. xml模块对文档的解析
a. 读取文件得到字符串进行解析
.tag 得到节点的标签
.attrib 得到节点的属性
.text 得到节点的内容


# 导入模块from xml.etree import ElementTree as ET# 读取xml文件内容result = open('xml', 'r', encoding='utf-8').read()# 解析文件内容, 得到root节点的对象root = ET.XML(result)# 通过循环遍历root节点下的节点,得到第一层的标签,属性,和内容for node in root:print(node.tag, node.attrib, node.find("rank").text)
结果:
country {'name': 'Liechtenstein'} 2country {'name': 'Hu'} 2country {'name': 'Zhou'} 2b. 直接打开文件进行解析
.parse 直接打开文件进行解析
.iter 寻找内容并进行迭代
.set 设置节点的属性
.write 写入


# 导入模块from xml.etree import ElementTree as ET# 通过parse创建一颗树tree = ET.parse('xml')# 通过树找到其根节点root = tree.getroot()# 通过循环遍历root节点下的节点,得到第一层的标签,属性,和内容for node in root:print(node.tag, node.attrib, node.find("rank").text)
结果:
country {'name': 'Liechtenstein'} 2country {'name': 'Hu'} 2country {'name': 'Zhou'} 2

# 导入模块from xml.etree import ElementTree as ET# 通过parse创建一颗树tree = ET.parse('xml')# 通过树找到其根节点root = tree.getroot()# 通过循环遍历root节点下的节点,得到第一层的标签,属性,和内容for node in root.iter("year"):# print(node.tag, node.attrib, node.find("rank").text)print(node)
new_year = int(node.text) + 1node.text = str(new_year)
node.set("name", "hu")
tree.write("xml")2cc198a1d5eb0d3eb508d858c9f5cbdb. xml模块创建xml文档


from xml.etree import ElementTree as ET# 创建几个节点ele = ET.Element('man', {'hu':'sb'})
son = ET.Element('woman', {'zhou':'sbsb'})
ele.append(son)# 创建一个tree,指向跟节点tree = ET.ElementTree(ele)
tree.write('outer.xml')

from xml.etree import ElementTree as ET# 创建几个节点ele = ET.Element('man', {'hu':'sb'})
son = ele.makeelement('woman', {'zhou':'sbsb'})
ele.append(son)# 创建一个tree,指向跟节点tree = ET.ElementTree(ele)
tree.write('outer.xml')

from xml.etree import ElementTree as ET
root = ET.Element('data', {'sb':'sb'})
ET.SubElement(root, 'root', {'sb':'sb'})
tree = ET.ElementTree(root)
tree.write('outer2')
tree.write('outer2', encoding='utf-8', xml_declaration=True)
Das obige ist der detaillierte Inhalt vonModule der Python-Serie 5. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!