
Heim >Backend-Entwicklung >Python-Tutorial >Was ist der Entscheidungsbaumalgorithmus?
Was ist der Entscheidungsbaumalgorithmus?

- PHP中文网Original
- 2017-06-20 10:11:184939Durchsuche
Englischer Name: Entscheidungsbaum
Der Entscheidungsbaum ist eine typische Klassifizierungsmethode. Die Daten werden zunächst verarbeitet, der induktive Algorithmus wird verwendet, um lesbare Regeln und Entscheidungsbäume zu generieren, und dann wird die Entscheidung zur Analyse verwendet neue Daten. Im Wesentlichen ist ein Entscheidungsbaum der Prozess der Klassifizierung von Daten anhand einer Reihe von Regeln.
Der Entscheidungsbaum ist eine überwachte Lernmethode, die hauptsächlich zur Klassifizierung und Regression verwendet wird. Das Ziel des Algorithmus besteht darin, ein Modell zu erstellen, das die Zielvariable vorhersagt, indem es Datenmerkmale ableitet und Entscheidungsregeln lernt.
Ein Entscheidungsbaum ähnelt einer If-Else-Struktur. Das Ergebnis ist, dass Sie einen Baum generieren möchten, der von der Wurzel des Baums bis zu den Blattknoten kontinuierlich beurteilen und auswählen kann. Die If-Else-Beurteilungsbedingungen werden hier jedoch nicht manuell festgelegt, sondern automatisch vom Computer basierend auf dem von uns bereitgestellten Algorithmus generiert.
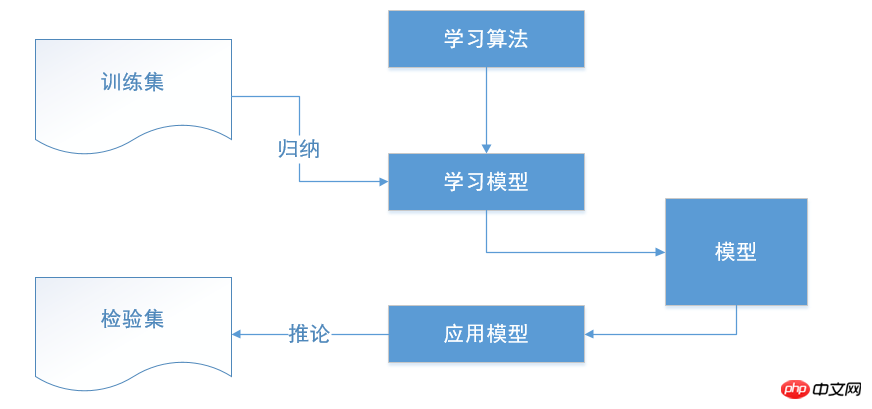
Die Elemente des Entscheidungsbaums
Der Entscheidungspunkt
ist ein Reaktion auf mehrere Möglichkeiten Die Wahl des Plans ist am Ende der beste Plan. Wenn es sich bei der Entscheidung um eine mehrstufige Entscheidung handelt, kann es in der Mitte des Entscheidungsbaums mehrere Entscheidungspunkte geben, und der Entscheidungspunkt an der Wurzel des Entscheidungsbaums ist der endgültige Entscheidungsplan.
Zustandsknoten
stellt den wirtschaftlichen Effekt (Erwartungswert) der Alternative dar, indem der wirtschaftliche Effekt jedes Zustandsknotens verglichen wird Anhand bestimmter Entscheidungskriterien kann die beste Lösung ausgewählt werden. Die von den Zustandsknoten abgeleiteten Zweige werden Wahrscheinlichkeitszweige genannt. Die Anzahl der Wahrscheinlichkeitszweige stellt die Anzahl der möglichen natürlichen Zustände dar. Die Wahrscheinlichkeit des Auftretens des Zustands muss auf jedem Zweig notiert werden.
Ergebnisknoten
Markieren Sie den Gewinn- und Verlustwert jedes Plans unter verschiedenen natürlichen Zuständen am rechten Ende des Ergebnisknotens
Vor- und Nachteile der Entscheidungsbaumgruppe
Vorteile des Entscheidungsbaums
Einfach und leicht zu verstehen, klare Prinzipien, Entscheidungsbaum kann visualisiert werden
Der Argumentationsprozess ist leicht zu verstehen und der Entscheidungsprozess kann in der Wenn-Sonst-Form ausgedrückt werden
Der Argumentationsprozess hängt vollständig davon ab die Werteigenschaften von Attributvariablen
Kann Attributvariablen, die keinen Beitrag zur Zielvariablen leisten, automatisch ignorieren und auch eine Referenz für die Beurteilung der Bedeutung von Attributvariablen und die Reduzierung der Anzahl der Variablen bereitstellen
Nachteile von Entscheidungsbäumen
können zu übermäßig komplexen Regeln, also einer Überanpassung, führen.
Entscheidungsbäume sind manchmal instabil, da geringfügige Änderungen in den Daten völlig unterschiedliche Entscheidungsbäume erzeugen können.
Das Erlernen des optimalen Entscheidungsbaums ist ein NP-vollständiges Problem. Daher basieren tatsächliche Lernalgorithmen für Entscheidungsbäume auf heuristischen Algorithmen, z. B. gierigen Algorithmen, die an jedem Knoten lokal optimale Werte erzielen. Ein solcher Algorithmus kann nicht garantieren, dass ein global optimaler Entscheidungsbaum zurückgegeben wird. Dieses Problem kann durch das Training mehrerer Entscheidungsbäume durch zufällige Auswahl von Merkmalen und Stichproben gemildert werden.
Manche Probleme sind sehr schwer zu lernen, weil Entscheidungsbäume schwer auszudrücken sind. Zum Beispiel: XOR-Problem, Paritätsprüfung oder Multiplexerproblem
Wenn einige Faktoren dominieren, ist der Entscheidungsbaum verzerrt. Daher wird empfohlen, die Einflussfaktoren der Daten abzuwägen, bevor der Entscheidungsbaum angepasst wird.
Gemeinsame Algorithmen für Entscheidungsbäume
Es gibt viele Algorithmen für Entscheidungsbäume, einschließlich CART, ID3, C4.5, C5.0 usw. Darunter ID3 , C4.5, C5.0 basieren auf Informationsentropie, während CART einen der Entropie ähnlichen Index als Klassifizierungsentscheidung verwendet. Nachdem der Entscheidungsbaum gebildet wurde, muss er beschnitten werden.
Entropie: Der Grad der Unordnung des Systems
ID3-Algorithmus
Der ID3-Algorithmus ist ein Klassifizierungs-Entscheidungsbaum-Algorithmus. Schließlich klassifizierte er die Daten anhand einer Reihe von Regeln in Form eines Entscheidungsbaums, und die Grundlage der Klassifizierung war die Entropie.
Der ID3-Algorithmus ist ein klassischer Entscheidungsbaum-Lernalgorithmus, der von Quinlan vorgeschlagen wurde. Die Grundidee des ID3-Algorithmus besteht darin, die Informationsentropie als Maß für die Attributauswahl von Entscheidungsbaumknoten zu verwenden. Jedes Mal wird zuerst das Attribut mit den meisten Informationen ausgewählt, dh das Attribut, das den Entropiewert minimieren kann Konstruieren Sie einen Entropiewert. Der am schnellsten absteigende Entscheidungsbaum hat einen Entropiewert von 0 für den Blattknoten. Zu diesem Zeitpunkt gehören die Instanzen im Instanzsatz, die jedem Blattknoten entsprechen, derselben Klasse an.
Nutzen Sie den ID3-Algorithmus, um eine Frühwarnanalyse der Kundenabwanderung zu realisieren und die Merkmale der Kundenabwanderung herauszufinden, um Telekommunikationsunternehmen dabei zu helfen, Kundenbeziehungen gezielt zu verbessern und Kundenabwanderung zu vermeiden
Nutzen Sie die Entscheidung Die Baummethode zur Durchführung von Data Mining umfasst im Allgemeinen die folgenden Schritte: Datenvorverarbeitung, Entscheidungsbaum-Mining-Operationen, Musterbewertung und -anwendung.
C4.5-Algorithmus
C4.5 ist eine weitere Erweiterung von ID3, die die Einschränkungen von Funktionen durch Diskretisierung kontinuierlicher Attribute beseitigt. C4.5 wandelt den Trainingsbaum in eine Reihe von Wenn-Dann-Grammatikregeln um. Die Genauigkeit dieser Regeln kann bestimmt werden, um zu bestimmen, welche übernommen werden sollten. Wenn die Genauigkeit durch Entfernen einer Regel verbessert werden kann, sollte eine Beschneidung implementiert werden.
Der Kernalgorithmus von C4.5 und ID3 ist derselbe, aber die verwendete Methode ist unterschiedlich. C4.5 verwendet die Informationsgewinnrate als Grundlage für die Division, wodurch das Problem der Verwendung von Informationen in ID3 überwunden wird Der Gain-Partitionierung bewirkt, dass die Attributauswahl Attribute mit mehr Werten bevorzugt.
C5.0-Algorithmus
C5.0 verwendet weniger Speicher als C4.5, legt kleinere Entscheidungsregeln fest und ist genauer.
CART-Algorithmus
Klassifizierungs- und Regressionsbaum (CART – Classification And Regression Tree)) ist eine sehr interessante und sehr effektive nichtparametrische Klassifizierungs- und Regressionsmethode. Vorhersagezwecke werden durch die Erstellung eines Binärbaums erreicht. Das Klassifikations- und Regressionsbaum-CART-Modell wurde erstmals von Breiman et al. vorgeschlagen und wird häufig im Bereich der Statistik und Data-Mining-Technologie verwendet. Es erstellt Vorhersagekriterien auf völlig andere Weise als herkömmliche Statistiken. Es wird in Form eines Binärbaums bereitgestellt, der leicht zu verstehen, zu verwenden und zu interpretieren ist. Der durch das CART-Modell erstellte Vorhersagebaum ist in vielen Fällen genauer als die durch häufig verwendete statistische Methoden erstellten algebraischen Vorhersagekriterien, und je komplexer die Daten und je mehr Variablen vorhanden sind, desto bedeutender wird die Überlegenheit des Algorithmus. Der Schlüssel zum Modell liegt in der genauen Erstellung von Vorhersagekriterien. Definition: Bei der Klassifizierung und Regression werden zunächst bekannte multivariate Daten verwendet, um Vorhersagekriterien zu erstellen, und dann wird eine Variable basierend auf den Werten anderer Variablen vorhergesagt. Bei der Klassifizierung führen Menschen häufig zunächst verschiedene Messungen an einem Objekt durch und bestimmen dann anhand bestimmter Klassifizierungskriterien, zu welcher Kategorie das Objekt gehört. Anhand der Identifikationsmerkmale eines bestimmten Fossils können Sie beispielsweise vorhersagen, zu welcher Familie, Gattung oder sogar Art das Fossil gehört. Ein weiteres Beispiel ist die Vorhersage, ob es in dem Gebiet Mineralien gibt, basierend auf den geologischen und geophysikalischen Informationen eines bestimmten Gebiets. Die Regression unterscheidet sich von der Klassifizierung dadurch, dass sie zur Vorhersage eines bestimmten Werts eines Objekts und nicht zur Klassifizierung des Objekts verwendet wird. Sagen Sie beispielsweise anhand der Eigenschaften der Bodenschätze in einem bestimmten Gebiet die Menge der Ressourcen in dem Gebiet vorher.
CART ist C4.5 sehr ähnlich, unterstützt jedoch numerische Zielvariablen (Regression) und generiert keine Entscheidungsregeln. CART verwendet Funktionen und Schwellenwerte, um an jedem Knoten einen maximalen Informationsgewinn für den Aufbau eines Entscheidungsbaums zu erzielen.
scikit-learn verwendet den CART-Algorithmus
Beispielcode:
#! /usr/bin/env python#-*- coding:utf-8 -*-from sklearn import treeimport numpy as np# scikit-learn使用的决策树算法是CARTX = [[0,0],[1,1]] Y = ["A","B"] clf = tree.DecisionTreeClassifier() clf = clf.fit(X,Y) data1 = np.array([2.,2.]).reshape(1,-1)print clf.predict(data1) # 预测类别 print clf.predict_proba(data1) # 预测属于各个类的概率
Okay, das ist es, ich hoffe es hilft.
Die Github-Adresse dieses Artikels:
20170619_Decision Tree Algorithm.md
Ergänzungen sind willkommen
Das obige ist der detaillierte Inhalt vonWas ist der Entscheidungsbaumalgorithmus?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!