
Heim >Backend-Entwicklung >Python-Tutorial >Scrapy erfasst Beispiele von College-Nachrichtenberichten
Scrapy erfasst Beispiele von College-Nachrichtenberichten

- PHP中文网Original
- 2017-06-21 10:47:111791Durchsuche
Fangen Sie alle Nachrichtenanfragen von der offiziellen Website der Sichuan University School of Public Administration () ab.
Experimenteller Prozess
1. Bestimmen Sie das Crawling-Ziel.
2 .
3. Crawling-Regeln zum Schreiben/Debuggen.
4. Crawling-Daten ermitteln
Das Ziel, das wir dieses Mal crawlen müssen, ist Sichuan Alle Neuigkeiten und Informationen über die School of Public Policy and Management der Universität. Daher müssen wir die Layoutstruktur der offiziellen Website der School of Public Policy and Management kennen.
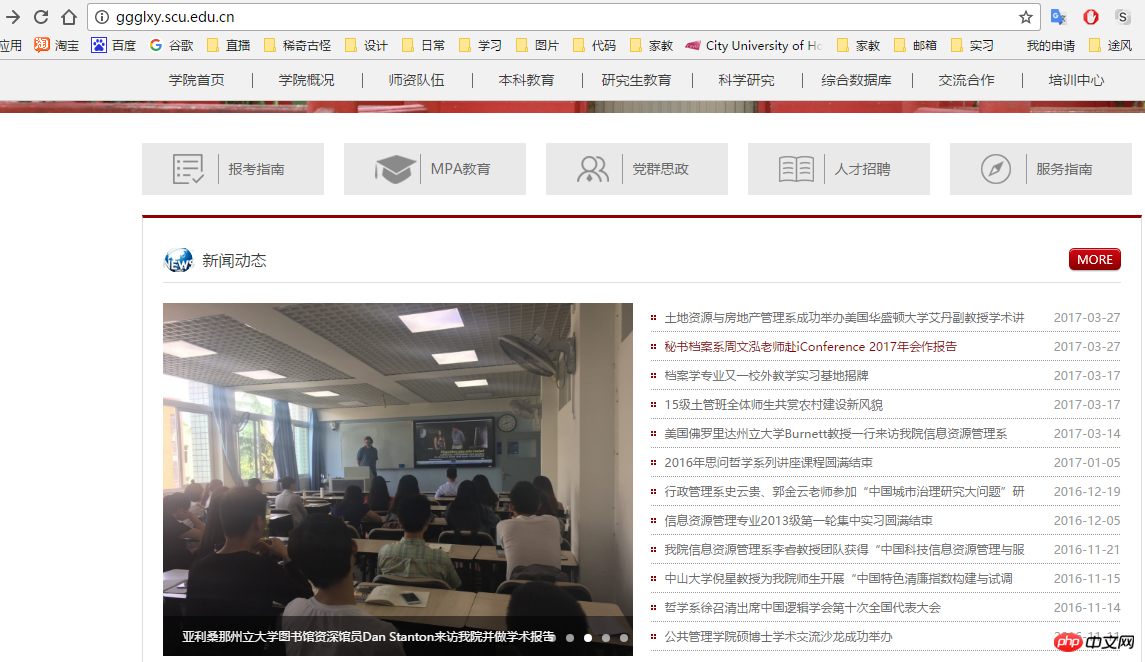 WeChat-Screenshot_20170515223045.png
WeChat-Screenshot_20170515223045.pngHier stellen wir fest, dass wir nicht alle Nachrichteninformationen direkt auf der Startseite der offiziellen Website erfassen können. Zum Aufrufen müssen wir auf „Mehr“ klicken die allgemeine Nachrichtenspalte.
 Paste_Image .png
Paste_Image .png2. Crawling-Regeln formulieren

Das ist für uns offensichtlich nicht schwierig
 Wir können den Seitensprung-Button unten sehen Nachrichtenspalte. Dann können wir alle Nachrichten über die Schaltfläche „Nächste Seite“ abrufen.
Wir können den Seitensprung-Button unten sehen Nachrichtenspalte. Dann können wir alle Nachrichten über die Schaltfläche „Nächste Seite“ abrufen.Um unsere Gedanken zu ordnen, können wir uns eine offensichtliche Crawling-Regel ausdenken:
Fangen Sie alle Nachrichtenlinks unter „Nachrichten“ ab Abschnitt“ und gehen Sie zum Link „Nachrichtendetails“, um alle Nachrichteninhalte zu crawlen.
3. Crawl-Regeln „Schreiben/Debuggen“
Im Crawler werde ich die folgenden Funktionspunkte implementieren:
1. Alle News-Links unter der News-Spalte auf einer Seite aussteigen
3. Crawlen Sie alle Nachrichten durch eine Schleife sind:3. Alle Daten auf der Webseite durch eine Schleife durchforsten .2. Die gecrawlten Daten zweimal durchforsten.
1. Die Basisdaten unter einer Seite herauskriechen.
Ohne weitere Umschweife, fangen wir jetzt an.Paste_Image.png
3.1 Alle News-Links unter der News-Spalte auf einer Seite ausklimmen

Paste_Image.png
 Den Code schreiben
Den Code schreibenTesten und bestehen!
import scrapyclass News2Spider(scrapy.Spider):
name = "news_info_2"
start_urls = ["http://ggglxy.scu.edu.cn/index.php?c=special&sid=1&page=1",
]def parse(self, response):for href in response.xpath("//div[@class='newsinfo_box cf']"):
url = response.urljoin(href.xpath("div[@class='news_c fr']/h3/a/@href").extract_first())3.2 Geben Sie die Nachrichtendetails über den gecrawlten Nachrichtenlink ein, um die zu crawlen Erforderliche Daten (hauptsächlich Nachrichteninhalte)  Jetzt habe ich eine Reihe von URLs erhalten und muss nun jede URL eingeben, um den Titel, die Zeit und den Inhalt zu erfassen, die ich benötige. Die Code-Implementierung ist ebenfalls recht einfach Der Originalcode erfasst eine URL, ich muss nur die URL eingeben und die entsprechenden Daten erfassen. Sie müssen also nur eine weitere Crawling-Methode schreiben, um die Nachrichtendetailseite aufzurufen, und sie mit scapy.request aufrufen >
Jetzt habe ich eine Reihe von URLs erhalten und muss nun jede URL eingeben, um den Titel, die Zeit und den Inhalt zu erfassen, die ich benötige. Die Code-Implementierung ist ebenfalls recht einfach Der Originalcode erfasst eine URL, ich muss nur die URL eingeben und die entsprechenden Daten erfassen. Sie müssen also nur eine weitere Crawling-Methode schreiben, um die Nachrichtendetailseite aufzurufen, und sie mit scapy.request aufrufen >Code schreiben
Test, bestanden!
#进入新闻详情页的抓取方法
def parse_dir_contents(self, response):item = GgglxyItem()item['date'] = response.xpath("//div[@class='detail_zy_title']/p/text()").extract_first()item['href'] = responseitem['title'] = response.xpath("//div[@class='detail_zy_title']/h1/text()").extract_first()
data = response.xpath("//div[@class='detail_zy_c pb30 mb30']")item['content'] = data[0].xpath('string(.)').extract()[0]
yield item Paste_Image.png
import scrapyfrom ggglxy.items import GgglxyItemclass News2Spider(scrapy.Spider):
name = "news_info_2"
start_urls = ["http://ggglxy.scu.edu.cn/index.php?c=special&sid=1&page=1",
]def parse(self, response):for href in response.xpath("//div[@class='newsinfo_box cf']"):
url = response.urljoin(href.xpath("div[@class='news_c fr']/h3/a/@href").extract_first())#调用新闻抓取方法yield scrapy.Request(url, callback=self.parse_dir_contents)#进入新闻详情页的抓取方法 def parse_dir_contents(self, response):
item = GgglxyItem()
item['date'] = response.xpath("//div[@class='detail_zy_title']/p/text()").extract_first()
item['href'] = response
item['title'] = response.xpath("//div[@class='detail_zy_title']/h1/text()").extract_first()
data = response.xpath("//div[@class='detail_zy_c pb30 mb30']")
item['content'] = data[0].xpath('string(.)').extract()[0]yield itemZu diesem Zeitpunkt fügen wir eine Schleife hinzu:
 Zum Originalcode hinzufügen:
Zum Originalcode hinzufügen:Test:
NEXT_PAGE_NUM = 1
NEXT_PAGE_NUM = NEXT_PAGE_NUM + 1if NEXT_PAGE_NUM<11:next_url = 'http://ggglxy.scu.edu.cn/index.php?c=special&sid=1&page=%s' % NEXT_PAGE_NUM
yield scrapy.Request(next_url, callback=self.parse)Paste_Image.png
import scrapyfrom ggglxy.items import GgglxyItem
NEXT_PAGE_NUM = 1class News2Spider(scrapy.Spider):
name = "news_info_2"
start_urls = ["http://ggglxy.scu.edu.cn/index.php?c=special&sid=1&page=1",
]def parse(self, response):for href in response.xpath("//div[@class='newsinfo_box cf']"):
URL = response.urljoin(href.xpath("div[@class='news_c fr']/h3/a/@href").extract_first())yield scrapy.Request(URL, callback=self.parse_dir_contents)global NEXT_PAGE_NUM
NEXT_PAGE_NUM = NEXT_PAGE_NUM + 1if NEXT_PAGE_NUM<11:
next_url = 'http://ggglxy.scu.edu.cn/index.php?c=special&sid=1&page=%s' % NEXT_PAGE_NUMyield scrapy.Request(next_url, callback=self.parse) def parse_dir_contents(self, response):
item = GgglxyItem()
item['date'] = response.xpath("//div[@class='detail_zy_title']/p/text()").extract_first()
item['href'] = response
item['title'] = response.xpath("//div[@class='detail_zy_title']/h1/text()").extract_first()
data = response.xpath("//div[@class='detail_zy_c pb30 mb30']")
item['content'] = data[0].xpath('string(.)').extract()[0] yield item抓到的数量为191,但是我们看官网发现有193条新闻,少了两条.
为啥呢?我们注意到log的error有两条:
定位问题:原来发现,学院的新闻栏目还有两条隐藏的二级栏目:
比如:

对应的URL为

URL都长的不一样,难怪抓不到了!
那么我们还得为这两条二级栏目的URL设定专门的规则,只需要加入判断是否为二级栏目:
if URL.find('type') != -1: yield scrapy.Request(URL, callback=self.parse)
组装原函数:
import scrapy
from ggglxy.items import GgglxyItem
NEXT_PAGE_NUM = 1class News2Spider(scrapy.Spider):
name = "news_info_2"
start_urls = ["http://ggglxy.scu.edu.cn/index.php?c=special&sid=1&page=1",
]def parse(self, response):for href in response.xpath("//div[@class='newsinfo_box cf']"):
URL = response.urljoin(href.xpath("div[@class='news_c fr']/h3/a/@href").extract_first())if URL.find('type') != -1:yield scrapy.Request(URL, callback=self.parse)yield scrapy.Request(URL, callback=self.parse_dir_contents)
global NEXT_PAGE_NUM
NEXT_PAGE_NUM = NEXT_PAGE_NUM + 1if NEXT_PAGE_NUM<11:
next_url = 'http://ggglxy.scu.edu.cn/index.php?c=special&sid=1&page=%s' % NEXT_PAGE_NUMyield scrapy.Request(next_url, callback=self.parse) def parse_dir_contents(self, response):
item = GgglxyItem()
item['date'] = response.xpath("//div[@class='detail_zy_title']/p/text()").extract_first()
item['href'] = response
item['title'] = response.xpath("//div[@class='detail_zy_title']/h1/text()").extract_first()
data = response.xpath("//div[@class='detail_zy_c pb30 mb30']")
item['content'] = data[0].xpath('string(.)').extract()[0] yield item测试:

我们发现,抓取的数据由以前的193条增加到了238条,log里面也没有error了,说明我们的抓取规则OK!
4.获得抓取数据
<code class="haxe"> scrapy crawl <span class="hljs-keyword">new<span class="hljs-type">s_info_2 -o <span class="hljs-number">0016.json</span></span></span></code><br/><br/>
Das obige ist der detaillierte Inhalt vonScrapy erfasst Beispiele von College-Nachrichtenberichten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!