
Heim >Betrieb und Instandhaltung >Betrieb und Wartung von Linux >ext-Dateisystemmechanismus
ext-Dateisystemmechanismus
- 巴扎黑Original
- 2017-06-23 14:19:292348Durchsuche
Verzeichnis dieses Artikels:
4.1 Komponenten des Dateisystems
4.2 Die vollständige Struktur des Dateisystems
4.3 Datenblock
4.4 Inode-Grundlagen
4.5 Inode im Detail
4.6 Prinzipien von Dateioperationen in einem einzelnen Dateisystem
4.7 Zuordnung mehrerer Dateisysteme
4.8 Protokollfunktion des ext3-Dateisystems
4.9 ext4-Dateisystem
4.10 ext Nachteile des Klassendateisystems
4.11 Virtuelles Dateisystem VFS
Partitionieren Sie die Festplatte und teilen Sie die Festplatte physisch in Zylinder auf. Nachdem Sie die Partition geteilt haben, müssen Sie sie formatieren und dann mounten, bevor sie verwendet werden kann (andere Methoden werden nicht berücksichtigt). Beim Formatieren einer Partition wird eigentlich ein Dateisystem erstellt.
Es gibt viele Arten von Dateisystemen, wie z. B. ext2/ext3/ext4, das standardmäßig unter CentOS 5 und CentOS 6 verwendet wird, xfs, das standardmäßig unter CentOS 7 verwendet wird, NTFS unter Windows, CD-ROM-Dateisystem ISO9660, Hybrides Dateisystem HFS auf MAC, Netzwerkdateisystem NFS, von Oracle entwickeltes Btrfs und altmodisches FAT/FAT32 usw.
In diesem Artikel wird das Dateisystem der Ext-Familie sehr umfassend und detailliert vorgestellt. Es gibt ext2/ext3/ext4, eine verbesserte Version von ext2 mit Protokollen, die im Vergleich zu ext3 viele Verbesserungen vorgenommen hat. Obwohl Dateisysteme wie xfs/btrfs unterschiedlich sind, unterscheiden sie sich nur in ihren Implementierungsmethoden und ihren eigenen Eigenschaften.
4.1 Komponenten des Dateisystems
4.1.1 Die Entstehung von Blöcken
Die Lese- und Schreib-E/A der Festplatte ist ein Sektor 512 auf einmal Bytes Wenn Sie eine große Anzahl von Dateien lesen und schreiben möchten, ist die Verwendung von Sektoren als Einheiten definitiv sehr langsam und verbraucht Leistung. Daher verwendet Linux „Block“ als Lese- und Schreibeinheit durch das Dateisystem Kontrolle. Auf aktuellen Dateisystemen beträgt die Blockgröße im Allgemeinen 1024 Byte (1 KB) oder 2048 Byte (2 KB) oder 4096 Byte (4 KB). Wenn beispielsweise ein oder mehrere Blöcke gelesen werden müssen, teilt der E/A-Manager des Dateisystems dem Festplattencontroller mit, welche Datenblöcke gelesen werden müssen. Der Festplattencontroller liest diese Blöcke nach Sektoren und überträgt sie dann über den Die Daten werden vom Festplattencontroller wieder zusammengesetzt und an den Computer zurückgegeben.
Die Entstehung von Blöcken verbessert die Lese- und Schreibleistung auf Dateisystemebene erheblich und reduziert die Fragmentierung erheblich. Der Nebeneffekt ist jedoch, dass dadurch Platz verschwendet werden kann. Da das Dateisystem Blöcke als Lese- und Schreibeinheiten verwendet, belegt die gespeicherte Datei, selbst wenn sie nur 1 KB groß ist, einen Block und der verbleibende Speicherplatz wird vollständig verschwendet. Unter bestimmten Geschäftsanforderungen kann es sein, dass eine große Anzahl kleiner Dateien gespeichert wird, wodurch viel Platz verschwendet wird.
Obwohl es Mängel aufweist, liegen seine Vorteile auf der Hand. In der heutigen Zeit der billigen Festplattenkapazität und des Strebens nach Leistung ist die Verwendung von Block ein Muss.
4.1.2 Das Erscheinungsbild von Inode
Was passiert, wenn eine gespeicherte Datei eine große Anzahl von Blocklesevorgängen erfordert? Wenn die Blockgröße 1 KB beträgt, sind zum Speichern einer 10-MB-Datei 10240 Blöcke erforderlich, und diese Blöcke sind wahrscheinlich nicht zusammenhängend (nicht benachbart). Müssen wir beim Lesen der Datei die gesamte Datei von vorne nach hinten scannen? des Dateisystems und dann herausfinden, welche Blöcke zu dieser Datei gehören? Offensichtlich sollten Sie dies nicht tun, da es zu langsam und dumm ist. Denken Sie noch einmal darüber nach: Ist das Lesen einer Datei, die nur einen Block belegt, vorbei, nachdem nur ein Block gelesen wurde? Nein, es scannt weiterhin alle Blöcke im gesamten Dateisystem, da es nicht weiß, wann es gescannt wird, und es weiß nicht, ob die Datei nach dem Scannen vollständig ist und keine anderen Blöcke scannen muss.
Darüber hinaus verfügt jede Datei über Attribute (wie Berechtigungen, Größe, Zeitstempel usw.). Wo werden die Metadaten dieser Attributklassen gespeichert? Wird es auch in Blöcken mit dem Datenteil der Datei gespeichert? Wenn eine Datei mehrere Blöcke belegt, muss dann jeder zur Datei gehörende Block Dateimetadaten speichern? Aber wenn das Dateisystem nicht in jedem Block Metadaten speichert, wie kann es dann wissen, ob ein bestimmter Block zur Datei gehört? Aber offensichtlich ist das Speichern einer Kopie der Metadaten in jedem Datenblock eine Platzverschwendung.
Dateisystemdesigner wissen sicherlich, dass diese Speichermethode nicht ideal ist, daher müssen sie die Speichermethode optimieren. Wie optimieren? Die Lösung für dieses ähnliche Problem besteht darin, einen Index zu verwenden, um die entsprechenden Daten durch Scannen des Index zu finden, und der Index kann einen Teil der Daten speichern.
Im Dateisystem ist die Indizierungstechnologie als Indexknoten verkörpert, und ein Teil der auf dem Indexknoten gespeicherten Daten sind die Attributmetadaten der Datei und andere kleine Informationsmengen. Im Allgemeinen ist der von einem Index belegte Speicherplatz viel kleiner als der der von ihm indizierten Dateidaten. Das Scannen ist viel schneller als das Scannen der gesamten Daten, andernfalls hat der Index keine Bedeutung. Damit sind alle bisherigen Probleme gelöst.
In der Dateisystemterminologie wird ein Indexknoten als Inode bezeichnet. Im Inode werden Metadateninformationen wie Inode-Nummer, Dateityp, Berechtigungen, Dateieigentümer, Größe, Zeitstempel usw. gespeichert. Das Wichtigste ist, dass beim Lesen auch der Zeiger auf den zur Datei gehörenden Block gespeichert wird Mit dem Inode können Sie die zur Datei gehörenden Blöcke finden, diese Blöcke dann lesen und die Daten der Datei abrufen. Da später zur Vereinfachung der Benennung und Unterscheidung eine Art Zeiger eingeführt wird, wird der Zeiger, der auf den Dateidatenblock in diesem Inode-Datensatz zeigt, vorerst als Blockzeiger bezeichnet.
Im Allgemeinen beträgt die Inode-Größe 128 Byte oder 256 Byte, was viel kleiner ist als die in MB oder GB berechneten Dateidaten. Sie sollten jedoch auch wissen, dass die Größe einer Datei kleiner sein kann als der Inode Größe, zum Beispiel nur Eine Datei, die 1 Byte belegt.
4.1.3 bmap erscheint
Beim Speichern von Daten auf der Festplatte muss das Dateisystem wissen, welche Blöcke frei und welche belegt sind. Die dümmste Methode besteht natürlich darin, von vorne nach hinten zu scannen, einen Teil des freien Blocks zu speichern, wenn er darauf stößt, und mit dem Scannen fortzufahren, bis alle Daten gespeichert sind.
Natürlich kann die Optimierungsmethode auch die Verwendung von Indizes in Betracht ziehen, aber nur ein 1-G-Dateisystem hat insgesamt 1 KB-Blöcke, 1024 * 1024 = 1048576. Was ist, wenn es 100 G, 500 G oder sogar ist? Größer? Die Anzahl und der Speicherplatzverbrauch allein durch die Verwendung von Indizes werden enorm sein. Zu diesem Zeitpunkt erscheint eine Optimierungsmethode auf höherer Ebene: die Verwendung von Block-Bitmaps (Bitmaps werden als Bmaps bezeichnet).
Die Bitmap verwendet nur 0 und 1, um zu identifizieren, ob der entsprechende Block frei oder belegt ist. Die Positionen von 0 und 1 in der Bitmap entsprechen der Position des Blocks die zweite Die Einerstelle markiert den zweiten Block und so weiter, bis alle Blöcke markiert sind.
Überlegen Sie, warum Block-Bitmaps optimaler sind. Es gibt 8 Bits in 1 Byte in der Bitmap, die 8 Blöcke identifizieren können. Für ein Dateisystem mit einer Blockgröße von 1 KB und einer Kapazität von 1 GB beträgt die Anzahl der Blöcke 1024 * 1024, sodass 1024 * 1024 Bits in der Bitmap verwendet werden, insgesamt 1024 * 1024/8 = 131072 Bytes = 128 KB. Das ist 1G. Die Datei benötigt nur 128 Blöcke als Bitmaps, um die Eins-zu-Eins-Korrespondenz zu vervollständigen. Durch das Scannen dieser mehr als 100 Blöcke können Sie feststellen, welche Blöcke frei sind, und die Geschwindigkeit wird erheblich verbessert.
Bitte beachten Sie jedoch, dass die bmap-Optimierung auf die Schreiboptimierung abzielt, da nur beim Schreiben der freie Block gefunden und zugewiesen werden muss. Beim Lesen kann die CPU die Adresse des Blocks auf der physischen Festplatte schnell berechnen, solange die Position des Blocks ermittelt wird nahezu vernachlässigbar, daher ist die Lesegeschwindigkeit grundsätzlich von der Leistung der Festplatte selbst abhängig und hat nichts mit dem Dateisystem zu tun.
Obwohl bmap das Scannen stark optimiert hat, gibt es immer noch einen Engpass: Was ist, wenn das Dateisystem 100 G groß ist? Ein 100G-Dateisystem verwendet 128*100=12800 1-KB-Blöcke, was 12,5 MB Speicherplatz beansprucht. Stellen Sie sich vor, dass es einige Zeit dauern wird, 12.800 Blöcke, die wahrscheinlich diskontinuierlich sind, vollständig zu scannen. Obwohl es schnell ist, kann es den enormen Aufwand für das Scannen jedes Mal, wenn eine Datei gespeichert wird, nicht ertragen.
Es muss also noch einmal optimiert werden. Kurz gesagt, das Dateisystem ist in Blockgruppen unterteilt. Die Einführung von Blockgruppen erfolgt später.
4.1.4 Die Entstehung der Inode-Tabelle
Sehen wir uns die Inode-bezogenen Informationen an: Inode speichert Inode-Nummer, Dateiattribut-Metadaten und Zeiger auf den von der Datei belegten Block. Jeder Inode belegt 128 Wörter Abschnitt oder 256 Bytes.
Jetzt gibt es ein weiteres Problem. Es kann unzählige Dateien in einem Dateisystem geben, und jede Datei entspricht einem Inode von nur 128 Bytes. Das ist so eine Platzverschwendung.
Eine bessere Möglichkeit besteht darin, mehrere Inodes zu kombinieren und in einem Block zu speichern. Bei einem 128-Byte-Inode speichert ein Block 8 Inodes. Bei einem 256-Byte-Inode speichert ein Block 4 Inodes. Dadurch wird sichergestellt, dass nicht jeder Block, der einen Inode speichert, verschwendet wird.
Im ext-Dateisystem werden diese Blöcke, die Inodes physisch speichern, kombiniert, um logisch eine Inode-Tabelle zu bilden, um alle Inodes aufzuzeichnen.
Zum Beispiel muss jede Familie ihre Haushaltsregistrierungsinformationen bei der Polizei registrieren. Die Haushaltsadresse kann aus dem Haushaltsregistrierungsbuch bekannt sein, und die Polizeistation in jeder Stadt oder Straße integriert alle Haushaltsregistrierungen in der Stadt oder Wenn Sie die Adresse eines bestimmten Haushalts herausfinden möchten, können Sie diese schnell auf der Polizeistation finden. Der Inode-Tisch ist hier die Polizeistation. Der Inhalt ist unten aufgeführt.
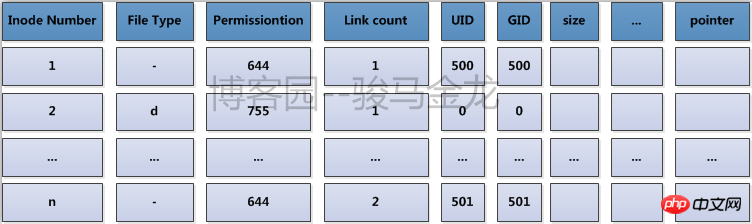
Tatsächlich wurden nach der Erstellung des Dateisystems alle Inode-Nummern zugewiesen und in der Inode-Tabelle aufgezeichnet, mit der Ausnahme, dass die Zeile, in der die Inode-Nummer verwendet wird, dort ist Es handelt sich auch um Metadateninformationen zu Dateiattributen und Blockspeicherortinformationen. Die nicht verwendete Inode-Nummer enthält nur eine Inode-Nummer und keine weiteren Informationen.
Wenn Sie sorgfältig darüber nachdenken, können Sie feststellen, dass ein großes Dateisystem immer noch eine große Anzahl von Blöcken zum Speichern von Inodes belegt. Allerdings ist auch das Auffinden eines Inode-Datensatzes mit großem Aufwand verbunden Sie wurden als logische Tabelle erstellt, können jedoch nicht damit umgehen, dass die Tabelle zu groß ist und zu viele Datensätze enthält. Daher muss auch die Optimierungsmethode für das schnelle Auffinden des Inodes darin bestehen, die Blöcke des Dateisystems in Gruppen zu unterteilen.
4.1.5 Die Entstehung von imap
Wie bereits erwähnt, ist Bmap eine Block-Bitmap, mit der identifiziert wird, welche Blöcke im Dateisystem frei und welche belegt sind.
Das Gleiche gilt für Inodes (alles in Linux ist eine Datei), Sie müssen ihnen eine Inode-Nummer zuweisen. Allerdings sind nach der Formatierung und Erstellung des Dateisystems alle Inode-Nummern voreingestellt und in der Inode-Tabelle gespeichert, sodass sich die Frage stellt: Welche Inode-Nummer soll der Datei zugewiesen werden? Wie kann festgestellt werden, ob eine bestimmte Inode-Nummer zugewiesen wurde?
Da es sich um die Frage „ob er belegt ist“ handelt, ist die Verwendung einer Bitmap die beste Lösung, so wie bmap die Belegung des Blocks aufzeichnet. Die Bitmap, die angibt, ob die Inode-Nummer zugewiesen ist, wird Inodemap oder kurz IMAP genannt. Um zu diesem Zeitpunkt einer Datei eine Inode-Nummer zuzuweisen, scannen Sie einfach die IMAP, um festzustellen, welche Inode-Nummer frei ist.
imap hat die gleichen Probleme, die gelöst werden müssen wie bmap und inode table: Wenn das Dateisystem relativ groß ist, ist imap selbst sehr groß und jedes Mal, wenn eine Datei gespeichert wird, muss sie gescannt werden. was zu einer unzureichenden Effizienz führen wird. In ähnlicher Weise besteht die Optimierungsmethode darin, die vom Dateisystem belegten Blöcke in Blockgruppen aufzuteilen, und jede Blockgruppe verfügt über einen eigenen IMAP-Bereich.
4.1.6 Die Entstehung von Blockgruppen
Die oben erwähnte Optimierungsmethode besteht darin, die vom Dateisystem belegten Blöcke in Blockgruppen zu unterteilen, um das Problem von Bmap, Inode-Tabelle und IMAP zu lösen zu groß. Große Frage.
Die Unterteilung auf der physischen Ebene besteht darin, die Festplatte basierend auf Zylindern in mehrere Partitionen zu unterteilen, dh in mehrere Dateisysteme. Die Unterteilung auf der logischen Ebene besteht darin, das Dateisystem in Blockgruppen zu unterteilen. Jedes Dateisystem enthält mehrere Blockgruppen, und jede Blockgruppe enthält mehrere Metadatenbereiche und Datenbereiche: Der Metadatenbereich ist der Bereich, in dem Bmap, Inode-Tabelle, IMAP usw. gespeichert sind . Beachten Sie, dass Blockgruppen ein logisches Konzept sind und daher nicht tatsächlich in Spalten, Sektoren, Spuren usw. auf der Festplatte unterteilt sind.
4.1.7 Aufteilung der Blockgruppen
Die Blockgruppe wurde nach der Erstellung des Dateisystems aufgeteilt, d. h. der Block wird vom Metadatenbereich Bmap, Inode-Tabelle, IMAP belegt und andere Informationen. Und die vom Datenbereich belegten Blöcke wurden aufgeteilt. Woher weiß das Dateisystem also, wie viele Blöcke ein Blockmetadatenbereich enthält und wie viele Blöcke der Datenbereich enthält?
Es muss nur ein Datenelement bestimmt werden – die Größe jedes Blocks, und dann berechnet werden, wie die Blockgruppe aufgeteilt werden soll basierend auf dem Standard, dass bmap höchstens einen vollständigen belegen kann Block. Wenn das Dateisystem sehr klein ist und nicht alle Bmaps insgesamt einen Block belegen können, kann nur der Bmap-Block freigegeben werden.
Die Größe jedes Blocks kann beim Erstellen des Dateisystems manuell angegeben werden. Wenn kein Wert angegeben wird, gibt es einen Standardwert.
Wenn die aktuelle Blockgröße 1 KB beträgt, kann eine Bmap, die einen Block vollständig einnimmt, 1024 * 8 = 8192 Blöcke identifizieren (natürlich sind diese 8192 Blöcke insgesamt 8192 Datenbereiche und Metadatenbereiche, da die Metadaten Bereich Der zugewiesene Block muss auch durch bmap identifiziert werden. Jeder Block ist 1 KB groß und jede Blockgruppe ist 8192 KB oder 8 MB groß. Das Erstellen eines 1G-Dateisystems erfordert die Aufteilung von 1024/8 = 128 Blockgruppen. 128+12,8=128+13=141 Blockgruppen.
Die Anzahl der Blöcke in jeder Gruppe wurde aufgeteilt, aber wie viele Inode-Nummern sind für jede Gruppe festgelegt? Wie viele Blöcke belegt die Inode-Tabelle? Dies muss vom System ermittelt werden, da uns der Indikator „wie vielen Blöcken im Datenbereich eine Inode-Nummer zugeordnet ist“ standardmäßig nicht bekannt ist. Natürlich kann dieser Indikator bzw. Prozentsatz auch manuell beim Erstellen einer Datei angegeben werden System. Siehe „Inode-Tiefe“ unten.
Mit dumpe2fs können Sie alle Dateisysteminformationen der ext-Klasse anzeigen. Natürlich repariert bmap einen Block für jede Blockgruppe und muss nicht angezeigt werden. imap ist kleiner als bmap, sodass es nur 1 einnimmt Block und muss nicht angezeigt werden.
Das Bild unten zeigt einen Teil der Informationen eines Dateisystems. Hinter diesen Informationen verbergen sich die Informationen jeder Blockgruppe.
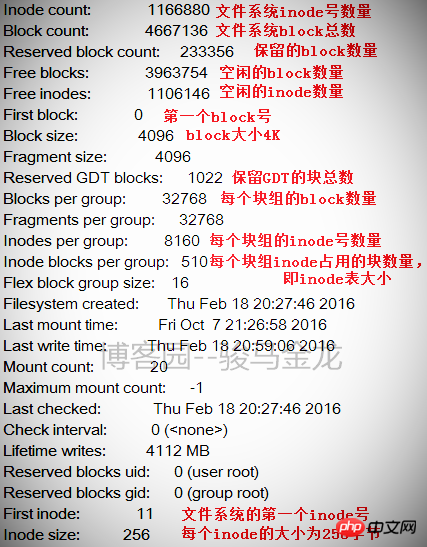
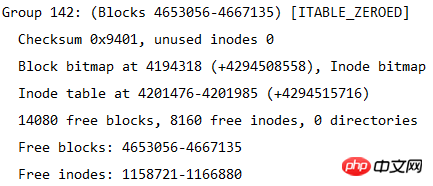
Die Größe des Dateisystems kann aus dieser Tabelle berechnet werden. Das Dateisystem hat insgesamt 4667136 Blöcke, und jeder Block ist 4 KB groß, also die Größe des Dateisystems ist 4667136*4/ 1024/1024=17,8 GB.
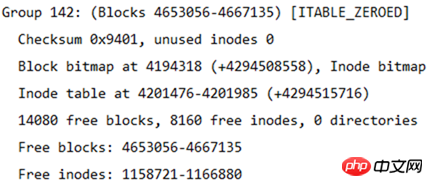
Sie können auch berechnen, wie viele Blockgruppen unterteilt sind, da die Anzahl der Blöcke in jeder Blockgruppe 32768 beträgt, sodass die Anzahl der Blockgruppen 4667136/32768 = 142,4 beträgt, was 143 Blockgruppen entspricht. Da Blockgruppen beginnend mit 0 nummeriert werden, ist die letzte Blockgruppennummer Gruppe 142. Wie in der folgenden Abbildung dargestellt, sind die Informationen der letzten Blockgruppe dargestellt.
4.2 Die vollständige Struktur des Dateisystems
Fügen Sie Bmap, Inode-Tabelle, IMAP und Datenbereich ein Die oben beschriebenen Konzepte von Blöcken und Blockgruppen werden zu einem Dateisystem zusammengefasst. Natürlich handelt es sich hierbei nicht um ein vollständiges Dateisystem. Das vollständige Dateisystem ist unten dargestellt.
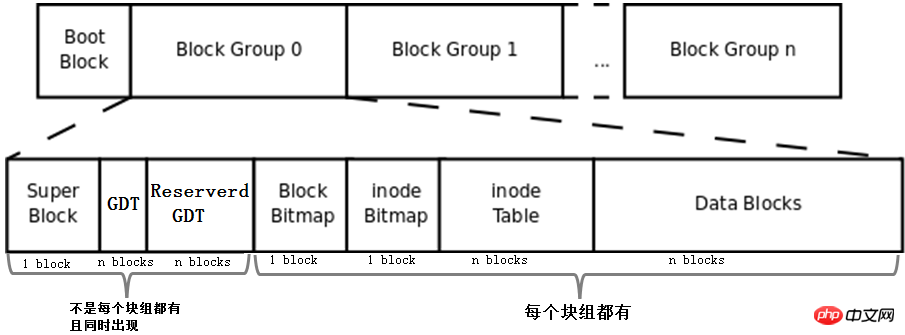
Zunächst werden dem Bild die Konzepte Boot Block, Super Block, GDT und Reserve GDT hinzugefügt. Sie werden im Folgenden gesondert vorgestellt.
Dann gibt die Zahl die Anzahl der Blöcke an, die von jedem Teil in der Blockgruppe belegt werden, mit Ausnahme von Superblock, Bmap und IMAP, die so bestimmt werden können, dass sie 1 Block belegen, für die anderen Teile kann nicht bestimmt werden, wie viele Blöcke, die sie besetzen.
Schließlich zeigt die Abbildung, dass Superblock, GDT und Reserved GDT gleichzeitig erscheinen und nicht unbedingt in jeder Blockgruppe vorhanden sind. Sie zeigt auch an, dass sich in jedem Block Bmap-, IMAP-, Inode-Tabellen- und Datenblöcke befinden Gruppe. Alle.
4.2.1 Boot-Block
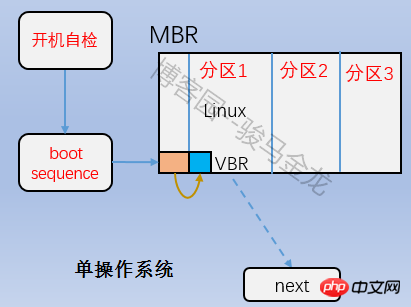
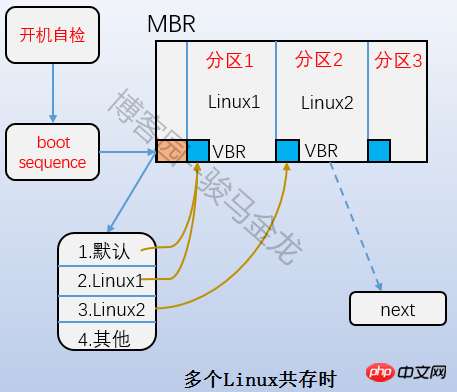
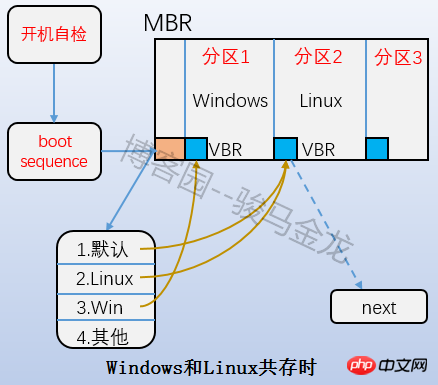
ist der Boot-Block-Teil in der obigen Abbildung, auch Boot-Sektor genannt. Er befindet sich im ersten Block der Partition und belegt 1024 Byte. Nicht alle Partitionen verfügen über diesen Bootsektor. Darin wird auch der Bootloader gespeichert. Es besteht eine gestaffelte Beziehung zwischen dem Bootloader hier und dem Bootloader auf dem MBR. Laden Sie beim Booten zunächst den Bootloader in den MBR und suchen Sie dann den Boot-Sektor der Partition, auf der sich das Betriebssystem befindet, um den Bootloader hier zu laden. Wenn mehrere Systeme vorhanden sind, wird nach dem Laden des Bootloaders im MBR das Betriebssystemmenü aufgelistet, und jedes Betriebssystem im Menü verweist auf den Bootsektor der Partition, in der es sich befindet. Die Beziehung zwischen ihnen ist in der folgenden Abbildung dargestellt.
4.2.2 Superblock
Da ein Dateisystem in mehrere Blöcke unterteilt ist, dann wie Weiß das Dateisystem, wie viele Blockgruppen aufgeteilt sind? Wie viele Blöcke, wie viele Inode-Nummern und andere Informationen hat jede Blockgruppe? Darüber hinaus werden die Attributinformationen des Dateisystems selbst angezeigt, z. B. verschiedene Zeitstempel, die Gesamtzahl der Blöcke und die Zahl der freien Blöcke, die Gesamtzahl und die Zahl der freien Inodes, ob das aktuelle Dateisystem normal ist, wann selbst- Test ist erforderlich usw., wo werden sie gespeichert?
Es besteht kein Zweifel, dass diese Informationen im Block gespeichert werden müssen. Das Speichern dieser Informationen belegt 1024 KB, daher ist auch ein Block erforderlich, der als Superblock bezeichnet wird und dessen Blocknummer 0 oder 1 sein kann. Wenn die Blockgröße 1024 KB beträgt, belegt der Bootblock genau einen Block. Die Blocknummer ist 0. Wenn die Blockgröße größer als 1024 KB ist, sind der Bootblock und der Superblock gleichzeitig. befindet sich in einem Block. Die Blocknummer ist 0. Kurz gesagt, die Start- und Endposition des Superblocks sind die zweiten 1024 (1024-2047) Bytes.
Was Sie mit dem Befehl df lesen, ist der Superblock jedes Dateisystems, daher sind seine Statistiken sehr schnell. Im Gegenteil, die Verwendung des Befehls du zum Anzeigen des belegten Speicherplatzes eines größeren Verzeichnisses ist sehr langsam, da zwangsläufig alle Dateien im gesamten Verzeichnis durchlaufen werden müssen.
[root@xuexi ~]# df -hT Filesystem Type Size Used Avail Use% Mounted on/dev/sda3 ext4 18G 1.7G 15G 11% /tmpfs tmpfs 491M 0 491M 0% /dev/shm/dev/sda1 ext4 190M 32M 149M 18% /boot
Superblock ist für das Dateisystem von entscheidender Bedeutung. Ein Verlust oder eine Beschädigung des Superblocks führt definitiv zu einer Beschädigung des Dateisystems. Daher sichert das alte Dateisystem den Superblock in jeder Blockgruppe, was jedoch Platz verschwendet, sodass das ext2-Dateisystem die Superblockinformationen nur in den Blockgruppen 0, 1 und 3, 5 und 7 speichert , wie Gruppe9, Gruppe25 usw. Obwohl so viele Superblöcke gespeichert werden, verwendet das Dateisystem nur die Superblockinformationen in der ersten Blockgruppe, Gruppe0, um Dateisystemattribute abzurufen. Erst wenn der Superblock in Gruppe0 beschädigt ist oder verloren geht, findet es den nächsten Backup-Superblock und kopiert ihn dorthin Gruppe0. um das Dateisystem wiederherzustellen.
Das Bild unten zeigt die Superblock-Informationen eines ext4-Dateisystems. Alle Dateisysteme der ext-Familie können mit dumpe2fs -h abgerufen werden.

4.2.3 Blockgruppen-Deskriptortabelle (GDT)
Da das Dateisystem in Blockgruppen unterteilt ist, sind die Informationen und Attributelemente jeder Blockgruppe Wo werden die Daten gespeichert?
Jede Blockgruppeninformation im ext-Dateisystem wird mit 32 Bytes beschrieben. Diese 32 Bytes werden als Blockgruppendeskriptoren bezeichnet. Die Blockgruppendeskriptoren aller Blockgruppen bilden die Blockgruppendeskriptortabelle GDT (Gruppendeskriptortabelle). .
Obwohl jede Blockgruppe einen Blockgruppendeskriptor benötigt, um die Informationen und Attributmetadaten der Blockgruppe aufzuzeichnen, speichert nicht jede Blockgruppe einen Blockgruppendeskriptor. Die Speichermethode des ext-Dateisystems besteht darin, einen GDT zu bilden und den GDT in bestimmten Blockgruppen zu speichern. Die Blockgruppe, in der der GDT gespeichert ist, ist dieselbe wie der Block, in dem der Superblock und der Backup-Superblock gespeichert sind eine bestimmte Blockgruppe gleichzeitig in einer Blockgruppe.
Wenn ein Dateisystem mit einer Blockgröße von 4 KB in 143 Blockgruppen unterteilt ist und jeder Blockgruppendeskriptor 32 Bytes groß ist, benötigt GDT 143*32=4576 Bytes oder zwei Blöcke zum Speichern. Die Blockgruppeninformationen aller Blockgruppen werden in diesen beiden GDT-Blöcken aufgezeichnet, und die GDTs in den Blockgruppen, in denen GDT gespeichert ist, sind genau gleich.
Das Bild unten zeigt die Informationen eines Blockgruppendeskriptors (erhalten über dumpe2fs).
4.2.4 Reserviertes GDT (Reserviertes GDT)
Reservieren Sie GDT für zukünftige Erweiterungen des Dateisystems, um zu verhindern, dass nach der Erweiterung zu viele Blockgruppen vorhanden sind, die zu Blockierungen führen Der Gruppendeskriptor überschreitet die Anzahl der Blöcke, in denen derzeit die GDT gespeichert ist. GDT und GDT erscheinen immer gleichzeitig, und natürlich erscheinen sie gleichzeitig mit dem Superblock.
Zum Beispiel verwenden die ersten 143 Blockgruppen 2 Blöcke zum Speichern von GDT, aber zu diesem Zeitpunkt verfügt der zweite Block noch über viel freien Speicherplatz. Wenn die Kapazität bis zu einem gewissen Grad erweitert wird, können die 2 Blöcke Wenn Sie den Blockgruppendeskriptor nicht mehr aufzeichnen, müssen Sie einen oder mehrere reservierte GDT-Blöcke zuweisen, um die überschüssigen Blockgruppendeskriptoren zu speichern.
Aufgrund des neu hinzugefügten GDT-Blocks sollte dieser GDT-Block zu jeder Blockgruppe hinzugefügt werden, in der GDT gleichzeitig gespeichert ist GDT kann direkt in Backup-GDT umgewandelt werden, ohne ineffiziente Kopiermethoden in jede Blockgruppe zu verwenden, in der GDT gespeichert ist.
In ähnlicher Weise muss das neu hinzugefügte GDT die Dateisystemattribute im Superblock in jeder Blockgruppe ändern, sodass die Kombination des Superblocks und des reservierten GDT/GDT die Effizienz verbessern kann.
4.3 Datenblock
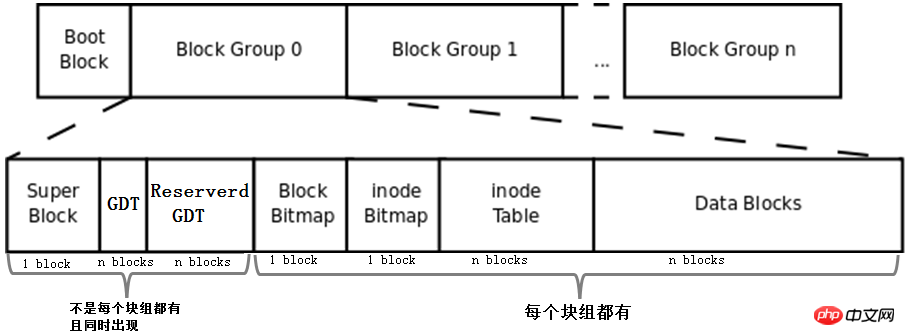
Wie im Bild oben gezeigt, wurden alle anderen Teile außer Datenblöcken erklärt. Der Datenblock ist ein Block, der Daten direkt speichert, aber tatsächlich ist es nicht so einfach.
Der von den Daten belegte Block wird durch den Blockzeiger im Inode-Datensatz gefunden, der der Datei entspricht. Der im Datenblock gespeicherte Inhalt ist für verschiedene Dateitypen unterschiedlich. So werden verschiedene Dateitypen unter Linux gespeichert.
Bei regulären Dateien werden die Daten der Datei normalerweise in Datenblöcken gespeichert.
Für ein Verzeichnis werden die Verzeichnisnamen aller Dateien und Unterverzeichnisse der ersten Ebene unter dem Verzeichnis im Datenblock gespeichert.
Der Dateiname wird nicht in einem eigenen Inode gespeichert, sondern im Datenblock des Verzeichnisses, in dem er liegt.
Wenn bei symbolischen Links der Zielpfadname kurz ist, wird er zur schnelleren Suche direkt im Inode gespeichert. Wenn der Zielpfadname lang ist, wird ein Datenblock gespeichert zugewiesen, um es zu retten.
Spezielle Dateien wie Gerätedateien, FIFOs und Sockets haben keine Datenblöcke. Die Hauptgerätenummer und die Nebengerätenummer der Gerätedatei werden im Inode gespeichert.
Die Speicherung regulärer Dateien wird nicht erläutert. Die Speichermethoden spezieller Dateien werden im Folgenden erläutert.
4.3.1 Datenblock von Verzeichnisdateien
Für Verzeichnisdateien speichert der Inode-Datensatz die Inode-Nummer des Verzeichnisses, die Attributmetadaten des Verzeichnisses und den Blockzeiger der Verzeichnisdatei. Dabei werden keine Informationen über den eigenen Dateinamen des Verzeichnisses gespeichert.
Die Speichermethode des Datenblocks ist in der folgenden Abbildung dargestellt.
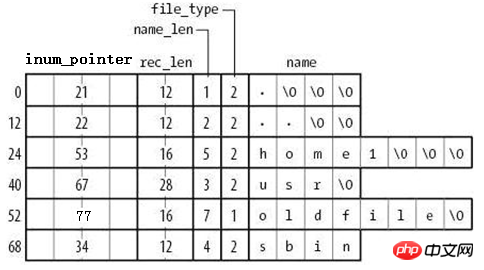
由图可知,在目录文件的数据块中存储了其下的文件名、目录名、目录本身的相对名称"."和上级目录的相对名称"..",还存储了指向inode table中这些文件名对应的inode号的指针(并非直接存储inode号码)、目录项长度rec_len、文件名长度name_len和文件类型file_type。注意到除了文件本身的inode记录了文件类型,其所在的目录的数据块也记录了文件类型。由于rec_len只能是4的倍数,所以需要使用"\0"来填充name_len不够凑满4倍数的部分。至于rec_len具体是什么,只需知道它是一种偏移即可。
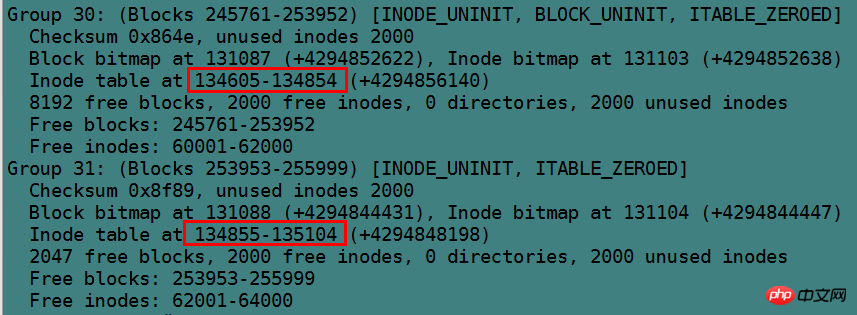
目录的data block中并没有直接存储目录中文件的inode号,它存储的是指向inode table中对应文件inode号的指针,暂且称之为inode指针(至此,已经知道了两种指针:一种是inode table中每个inode记录指向其对应data block的block指针,一个此处的inode指针)。一个很有说服力的例子,在目录只有读而没有执行权限的时候,使用"ls -l"是无法获取到其内文件inode号的,这就表明没有直接存储inode号。实际上,因为在创建文件系统的时候,inode号就已经全部划分好并在每个块组的inode table中存放好,inode table在块组中是有具体位置的,如果使用dumpe2fs查看文件系统,会发现每个块组的inode table占用的block数量是完全相同的,如下图是某分区上其中两个块组的信息,它们都占用249个block。
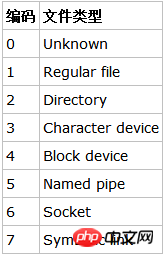
除了inode指针,目录的data block中还使用数字格式记录了文件类型,数字格式和文件类型的对应关系如下图。
注意到目录的data block中前两行存储的是目录本身的相对名称"."和上级目录的相对名称"..",它们实际上是目录本身的硬链接和上级目录的硬链接。硬链接的本质后面说明。
由此也就容易理解目录权限的特殊之处了。目录文件的读权限(r)和写权限(w),都是针对目录文件的数据块本身。由于目录文件内只有文件名、文件类型和inode指针,所以如果只有读权限,只能获取文件名和文件类型信息,无法获取其他信息,尽管目录的data block中也记录着文件的inode指针,但定位指针是需要x权限的,因为其它信息都储存在文件自身对应的inode中,而要读取文件inode信息需要有目录文件的执行权限通过inode指针定位到文件对应的inode记录上。以下是没有目录x权限时的查询状态,可以看到除了文件名和文件类型,其余的全是"?"。
[lisi4@xuexi tmp]$ ll -i d ls: cannot access d/hehe: Permission denied ls: cannot access d/haha: Permission denied total 0? d????????? ? ? ? ? ? haha? -????????? ? ? ? ? ? hehe
注意,xfs文件系统和ext文件系统不一样,它连文件类型都无法获取。
4.3.2 符号链接存储方式
符号链接即为软链接,类似于Windows操作系统中的快捷方式,它的作用是指向原文件或目录。
软链接之所以也被称为特殊文件的原因是:它一般情况下不占用data block,仅仅通过它对应的inode记录就能将其信息描述完成;符号链接的大小是其指向目标路径占用的字符个数,例如某个符号链接的指向方式为"rmt --> ../sbin/rmt",则其文件大小为11字节;只有当符号链接指向的目标的路径名较长(60个字节)时文件系统才会划分一个data block给它;它的权限如何也不重要,因它只是一个指向原文件的"工具",最终决定是否能读写执行的权限由原文件决定,所以很可能ls -l查看到的符号链接权限为777。
注意,软链接的block指针存储的是目标文件名。也就是说,链接文件的一切都依赖于其目标文件名。这就解释了为什么/mnt的软链接/tmp/mnt在/mnt挂载文件系统后,通过软链接就能进入/mnt所挂载的文件系统。究其原因,还是因为其目标文件名"/mnt"并没有改变。
例如以下筛选出了/etc/下的符号链接,注意观察它们的权限和它们占用的空间大小。
[root@xuexi ~]# ll /etc/ | grep '^l'lrwxrwxrwx. 1 root root 56 Feb 18 2016 favicon.png -> /usr/share/icons/hicolor/16x16/apps/system-logo-icon.png lrwxrwxrwx. 1 root root 22 Feb 18 2016 grub.conf -> ../boot/grub/grub.conf lrwxrwxrwx. 1 root root 11 Feb 18 2016 init.d -> rc.d/init.d lrwxrwxrwx. 1 root root 7 Feb 18 2016 rc -> rc.d/rc lrwxrwxrwx. 1 root root 10 Feb 18 2016 rc0.d -> rc.d/rc0.d lrwxrwxrwx. 1 root root 10 Feb 18 2016 rc1.d -> rc.d/rc1.d lrwxrwxrwx. 1 root root 10 Feb 18 2016 rc2.d -> rc.d/rc2.d lrwxrwxrwx. 1 root root 10 Feb 18 2016 rc3.d -> rc.d/rc3.d lrwxrwxrwx. 1 root root 10 Feb 18 2016 rc4.d -> rc.d/rc4.d lrwxrwxrwx. 1 root root 10 Feb 18 2016 rc5.d -> rc.d/rc5.d lrwxrwxrwx. 1 root root 10 Feb 18 2016 rc6.d -> rc.d/rc6.d lrwxrwxrwx. 1 root root 13 Feb 18 2016 rc.local -> rc.d/rc.local lrwxrwxrwx. 1 root root 15 Feb 18 2016 rc.sysinit -> rc.d/rc.sysinit lrwxrwxrwx. 1 root root 14 Feb 18 2016 redhat-release -> centos-release lrwxrwxrwx. 1 root root 11 Apr 10 2016 rmt -> ../sbin/rmt lrwxrwxrwx. 1 root root 14 Feb 18 2016 system-release -> centos-release
4.3.3 设备文件、FIFO、套接字文件
关于这3种文件类型的文件只需要通过inode就能完全保存它们的信息,它们不占用任何数据块,所以它们是特殊文件。
设备文件的主设备号和次设备号也保存在inode中。以下是/dev/下的部分设备信息。注意到它们的第5列和第6列信息,它们分别是主设备号和次设备号,主设备号标识每一种设备的类型,次设备号标识同种设备类型的不同编号;也注意到这些信息中没有大小的信息,因为设备文件不占用数据块所以没有大小的概念。
[root@xuexi ~]# ll /dev | tailcrw-rw---- 1 vcsa tty 7, 129 Oct 7 21:26 vcsa1 crw-rw---- 1 vcsa tty 7, 130 Oct 7 21:27 vcsa2 crw-rw---- 1 vcsa tty 7, 131 Oct 7 21:27 vcsa3 crw-rw---- 1 vcsa tty 7, 132 Oct 7 21:27 vcsa4 crw-rw---- 1 vcsa tty 7, 133 Oct 7 21:27 vcsa5 crw-rw---- 1 vcsa tty 7, 134 Oct 7 21:27 vcsa6 crw-rw---- 1 root root 10, 63 Oct 7 21:26 vga_arbiter crw------- 1 root root 10, 57 Oct 7 21:26 vmci crw-rw-rw- 1 root root 10, 56 Oct 7 21:27 vsock crw-rw-rw- 1 root root 1, 5 Oct 7 21:26 zero
4.4 inode基础知识
每个文件都有一个inode,在将inode关联到文件后系统将通过inode号来识别文件,而不是文件名。并且访问文件时将先找到inode,通过inode中记录的block位置找到该文件。
4.4.1 硬链接
虽然每个文件都有一个inode,但是存在一种可能:多个文件的inode相同,也就即inode号、元数据、block位置都相同,这是一种什么样的情况呢?能够想象这些inode相同的文件使用的都是同一条inode记录,所以代表的都是同一个文件,这些文件所在目录的data block中的inode指针目的地都是一样的,只不过各指针对应的文件名互不相同而已。这种inode相同的文件在Linux中被称为"硬链接"。
硬链接文件的inode都相同,每个文件都有一个"硬链接数"的属性,使用ls -l的第二列就是被硬链接数,它表示的就是该文件有几个硬链接。
[root@xuexi ~]# ls -l total 48drwxr-xr-x 5 root root 4096 Oct 15 18:07 700-rw-------. 1 root root 1082 Feb 18 2016 anaconda-ks.cfg-rw-r--r-- 1 root root 399 Apr 29 2016 Identity.pub-rw-r--r--. 1 root root 21783 Feb 18 2016 install.log-rw-r--r--. 1 root root 6240 Feb 18 2016 install.log.syslog
例如下图描述的是dir1目录中的文件name1及其硬链接dir2/name2,右边分别是它们的inode和datablock。这里也看出了硬链接文件之间唯一不同的就是其所在目录中的记录不同。注意下图中有一列Link Count就是标记硬链接数的属性。

每创建一个文件的硬链接,实质上是多一个指向该inode记录的inode指针,并且硬链接数加1。
删除文件的实质是删除该文件所在目录data block中的对应的inode指针,所以也是减少硬链接次数,由于block指针是存储在inode中的,所以不是真的删除数据,如果仍有其他指针指向该inode,那么该文件的block指针仍然是可用的。当硬链接次数为1时再删除文件就是真的删除文件了,此时inode记录中block指针也将被删除。
不能跨分区创建硬链接,因为不同文件系统的inode号可能会相同,如果允许创建硬链接,复制到另一个分区时inode可能会和此分区已使用的inode号冲突。
硬链接只能对文件创建,无法对目录创建硬链接。之所以无法对目录创建硬链接,是因为文件系统已经把每个目录的硬链接创建好了,它们就是相对路径中的"."和"..",分别标识当前目录的硬链接和上级目录的硬链接。每一个目录中都会包含这两个硬链接,它包含了两个信息:(1)一个没有子目录的目录文件的硬链接数是2,其一是目录本身,其二是".";(2)一个包含子目录的目录文件,其硬链接数是2+子目录数,因为每个子目录都关联一个父目录的硬链接".."。很多人在计算目录的硬链接数时认为由于包含了"."和"..",所以空目录的硬链接数是2,这是错误的,因为".."不是本目录的硬链接。另外,还有一个特殊的目录应该纳入考虑,即"/"目录,它自身是一个文件系统的入口,是自引用(下文中会解释自引用)的,所以"/"目录下的"."和".."的inode号相同,硬链接数除去其内的子目录后应该为3,但结果是2,不知为何?
[root@xuexi ~]# ln /tmp /mydataln: `/tmp': hard link not allowed for directory
为什么文件系统自己创建好了目录的硬链接就不允许人为创建呢?从"."和".."的用法上考虑,如果当前目录为/usr,我们可以使用"./local"来表示/usr/local,但是如果我们人为创建了/usr目录的硬链接/tmp/husr,难道我们也要使用"/tmp/husr/local"来表示/usr/local吗?这其实已经是软链接的作用了。若要将其认为是硬链接的功能,这必将导致硬链接维护的混乱。
不过,通过mount工具的"--bind"选项,可以将一个目录挂载到另一个目录下,实现伪"硬链接",它们的内容和inode号是完全相同的。
硬链接的创建方法:ln file_target link_name。
4.4.2 软链接
软链接就是字符链接,链接文件默认指的就是字符文件,使用"l"表示其类型。
软链接在功能上等价与Windows系统中的快捷方式,它指向原文件,原文件损坏或消失,软链接文件就损坏。可以认为软链接inode记录中的指针内容是目标路径的字符串。
创建方式:ln –s file_target softlink_name
查看软链接的值:readlink softlink_name
在设置软链接的时候,target虽然不要求是绝对路径,但建议给绝对路径。是否还记得软链接文件的大小?它是根据软链接所指向路径的字符数计算的,例如某个符号链接的指向方式为"rmt --> ../sbin/rmt",它的文件大小为11字节,也就是说只要建立了软链接后,软链接的指向路径是不会改变的,仍然是"../sbin/rmt"。如果此时移动软链接文件本身,它的指向是不会改变的,仍然是11个字符的"../sbin/rmt",但此时该软链接父目录下可能根本就不存在/sbin/rmt,也就是说此时该软链接是一个被破坏的软链接。
4.5 inode深入
4.5.1 inode大小和划分
inode大小为128字节的倍数,最小为128字节。它有默认值大小,它的默认值由/etc/mke2fs.conf文件中指定。不同的文件系统默认值可能不同。
[root@xuexi ~]# cat /etc/mke2fs.conf
[defaults]
base_features = sparse_super,filetype,resize_inode,dir_index,ext_attr
enable_periodic_fsck = 1blocksize = 4096inode_size = 256inode_ratio = 16384[fs_types]
ext3 = {
features = has_journal
}
ext4 = {
features = has_journal,extent,huge_file,flex_bg,uninit_bg,dir_nlink,extra_isize
inode_size = 256}同样观察到这个文件中还记录了blocksize的默认值和inode分配比率inode_ratio。inode_ratio=16384表示每16384个字节即16KB就分配一个inode号,由于默认blocksize=4KB,所以每4个block就分配一个inode号。当然分配的这些inode号只是预分配,并不真的代表会全部使用,毕竟每个文件才会分配一个inode号。但是分配的inode自身会占用block,而且其自身大小256字节还不算小,所以inode号的浪费代表着空间的浪费。
既然知道了inode分配比率,就能计算出每个块组分配多少个inode号,也就能计算出inode table占用多少个block。
如果文件系统中大量存储电影等大文件,inode号就浪费很多,inode占用的空间也浪费很多。但是没办法,文件系统又不知道你这个文件系统是用来存什么样的数据,多大的数据,多少数据。
当然inodesize、inode分配比例、blocksize都可以在创建文件系统的时候人为指定。
4.5.2 ext文件系统预留的inode号
Ext预留了一些inode做特殊特性使用,如下:某些可能并非总是准确,具体的inode号对应什么文件可以使用"find / -inum NUM"查看。
Ext4的特殊inode
Inode号 用途
0 不存在0号inode
1 虚拟文件系统,如/proc和/sys
2 根目录
3 ACL索引
4 ACL数据
5 Boot loader
6 未删除的目录
7 预留的块组描述符inode
8 日志inode
11 第一个非预留的inode,通常是lost+found目录
所以在ext4文件系统的dumpe2fs信息中,能观察到fisrt inode号可能为11也可能为12。
并且注意到"/"的inode号为2,这个特性在文件访问时会用上。
需要注意的是,每个文件系统都会分配自己的inode号,不同文件系统之间是可能会出现使用相同inode号文件的。例如:
[root@xuexi ~]# find / -ignore_readdir_race -inum 2 -ls 2 4 dr-xr-xr-x 22 root root 4096 Jun 9 09:56 / 2 2 dr-xr-xr-x 5 root root 1024 Feb 25 11:53 /boot 2 0 c--------- 1 root root Jun 7 02:13 /dev/pts/ptmx 2 0 -rw-r--r-- 1 root root 0 Jun 6 18:13 /proc/sys/fs/binfmt_misc/status 2 0 drwxr-xr-x 3 root root 0 Jun 6 18:13 /sys/fs
Wie aus den Ergebnissen ersichtlich ist, gibt es zusätzlich zur Root-Inode-Nummer von 2 auch mehrere Dateien mit Inode-Nummern von ebenfalls 2. Sie gehören alle zu unabhängigen Dateisystemen, und einige sind virtuelle Dateisysteme, wie z /proc und /sys.
4.5.3 Direkte und indirekte Adressierung des ext2/3-Inodes
Wie bereits erwähnt, wird der Blockzeiger im Inode gespeichert, aber die Anzahl der Zeiger, die in einem Inode-Datensatz gespeichert werden können Andernfalls wird die Inode-Größe (128 Byte oder 256 Byte) überschritten.
In ext2- und ext3-Dateisystemen kann es nur bis zu 15 Zeiger in einem Inode geben, und jeder Zeiger wird durch i_block[n] dargestellt.
Die ersten 12 Zeiger i_block[0] bis i_block[11] sind direkte Adressierungszeiger, jeder Zeiger zeigt auf einen Block im Datenbereich. Wie unten gezeigt.
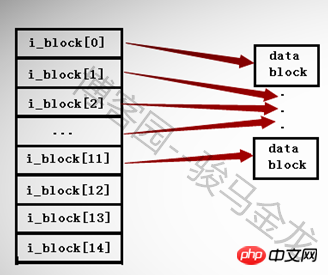
Der 13. Zeiger i_block[12] ist ein indirekter Adressierungszeiger der ersten Ebene, der auf einen Block zeigt, der noch Zeiger speichert, also i_block[13] -- > Zeigerblock --> Datenblock.
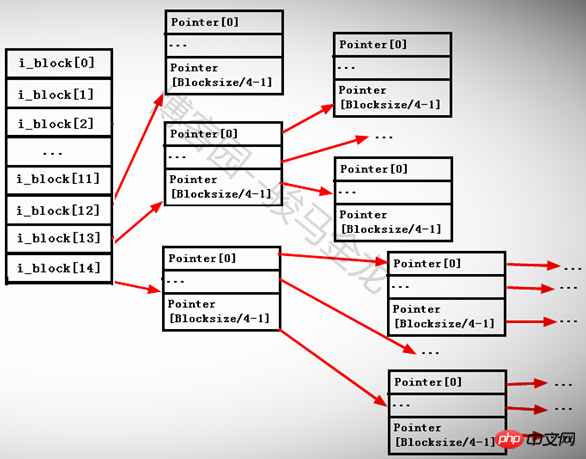
Der 14. Zeiger i_block[13] ist ein sekundärer indirekter Adressierungszeiger. Er zeigt auf einen Block, der noch Zeiger speichert, aber die Zeiger in diesem Block zeigen weiterhin auf andere Blöcke, die Zeiger speichern, nämlich i_block [ 13] --> Pointerblock1 -->
Der 15. Zeiger i_block[14] ist ein dreistufiger indirekter Adressierungszeiger. Er zeigt auf einen Block, der noch Zeiger speichert. Das heißt, i_block[13] --> PointerBlock2 -->
Da jeder Zeiger 4 Byte groß ist, beträgt die Anzahl der Zeiger, die jeder Zeigerblock speichern kann, BlockSize/4 Byte. Wenn die Blockgröße beispielsweise 4 KB beträgt, kann ein Block 4096/4=1024 Zeiger speichern.
Wie unten gezeigt.
Warum werden indirekte und direkte Zeiger getrennt? Wenn alle 15 Zeiger in einem Inode direkte Zeiger sind und die Größe jedes Blocks 1 KB beträgt, können die 15 Zeiger nur auf 15 Blöcke zeigen, was einer Größe von 15 KB entspricht. Da jede Datei einer Inode-Nummer entspricht, ist dies begrenzt Die maximale Größe jedes Blocks beträgt 15 * 1 = 15 KB, was offensichtlich unangemessen ist.
Wenn Sie eine Datei speichern, die größer als 15 KB, aber nicht zu groß ist, belegt sie den indirekten Zeiger der ersten Ebene i_block[12]. Zu diesem Zeitpunkt beträgt die Anzahl der speicherbaren Zeiger 1024/4+ 12=268, sodass 268 KB Datei gespeichert werden können.
Wenn Sie eine Datei speichern, die größer als 268 KB, aber nicht zu groß ist, belegt sie weiterhin den sekundären Zeiger i_block[13]. Zu diesem Zeitpunkt beträgt die Anzahl der speicherbaren Zeiger [1024/4]. ^2+1024/4+ 12=65804, sodass Dateien von etwa 65804 KB = 64 MB gespeichert werden können.
Wenn die gespeicherte Datei größer als 64 MB ist, verwenden Sie weiterhin den dreistufigen indirekten Zeiger i_block[14], und die Anzahl der gespeicherten Zeiger beträgt [1024/4]^3+[1024/4] ^2+[1024/ 4]+12=16843020 Zeiger, sodass Dateien mit etwa 16843020 KB=16 GB gespeichert werden können.
Was ist, wenn die Blockgröße = 4 KB ist? Dann beträgt die maximale Dateigröße, die gespeichert werden kann, ([4096/4]^3+[4096/4]^2+[4096/4]+12)*4/1024/1024/1024=ungefähr 4T.
Was auf diese Weise berechnet wird, ist natürlich nicht unbedingt die maximale Dateigröße, die gespeichert werden kann. Es unterliegt auch einer anderen Bedingung. Die Berechnungen hier geben lediglich an, wie eine große Datei adressiert und zugeordnet wird.
Wenn Sie die hier berechneten Werte sehen, wissen Sie, dass die Zugriffseffizienz von ext2 und ext3 für sehr große Dateien gering ist. Sie müssen zu viele Zeiger überprüfen, insbesondere wenn die Blockgröße 4 KB beträgt . Ext4 wurde für diesen Punkt optimiert. Ext4 verwendet Extent-Management, um die Blockzuordnung von ext2 und ext3 zu ersetzen, was die Effizienz erheblich verbessert und die Fragmentierung verringert.
4.6 Prinzipien von Dateioperationen in einem einzelnen Dateisystem
Wie werden Vorgänge wie Löschen, Kopieren, Umbenennen und Verschieben unter Linux ausgeführt? Was ist damit? Und wie finden Sie es, wenn Sie auf die Datei zugreifen? Solange Sie die verschiedenen im vorherigen Artikel eingeführten Begriffe und ihre Funktionen verstehen, ist es tatsächlich einfach, die Prinzipien von Dateioperationen zu kennen.
Hinweis: In diesem Abschnitt wird das Verhalten unter einem einzelnen Dateisystem erläutert. Informationen zur Verwendung mehrerer Dateisysteme finden Sie im nächsten Abschnitt: Zuordnung mehrerer Dateisysteme.
4.6.1 Dateien lesen
Welche Schritte werden im System ausgeführt, wenn der Befehl „cat /var/log/messages“ ausgeführt wird? Die erfolgreiche Ausführung dieses Befehls erfordert komplexe Prozesse wie die Suche nach dem Befehl cat, die Beurteilung von Berechtigungen sowie die Suche und Beurteilung der Nachrichtendateien. Hier erklären wir nur, wie Sie die Datei /var/log/messages finden, die mit dem Inhalt dieses Abschnitts verknüpft ist und sich darauf bezieht.
Suchen Sie die Blöcke, in denen sich die Blockgruppen-Deskriptortabelle des Root-Dateisystems befindet, lesen Sie den GDT (bereits im Speicher), um die Blocknummer der Inode-Tabelle zu finden.
Da sich GDT immer in derselben Blockgruppe wie der Superblock befindet und sich der Superblock immer im 1024.-2047. Byte der Partition befindet, ist es einfach, das erste zu kennen Die Blockgruppe, in der sich GDT befindet und welche Blöcke GDT in dieser Blockgruppe belegt.
Tatsächlich befindet sich GDT bereits im Speicher. Wenn das System gestartet wird, wird es im Root-Dateisystem gemountet. Beim Mounten wurden alle GDTs im Speicher abgelegt.
Suchen Sie den Inode der Wurzel „/“ im Block der Inode-Tabelle und suchen Sie den Datenblock, auf den „/“ zeigt.
Wie bereits erwähnt, reserviert das ext-Dateisystem einige Inode-Nummern, darunter die Inode-Nummer von „/“ 2, sodass die Root-Verzeichnisdatei direkt gefunden werden kann auf der Inode-Nummer.
Der var-Verzeichnisname und der Zeiger auf den var-Verzeichnisdatei-Inode werden im Datenblock von „/“ aufgezeichnet und der Inode-Datensatz wird gefunden. Der Block, der auf var zeigt wird im Inode-Datensatz gespeichert, sodass der Datenblock der var-Verzeichnisdatei gefunden wird.
Sie können den Inode-Datensatz des var-Verzeichnisses über den Inode-Zeiger des var-Verzeichnisses finden. Während des Zeigerpositionierungsprozesses müssen Sie jedoch auch den Block kennen Gruppe und Speicherort des Inode-Datensatzes, daher muss GDT im Speicher zwischengespeichert werden.
Der Name des Protokollverzeichnisses und sein Inode-Zeiger werden im Datenblock von var aufgezeichnet. Über diesen Zeiger werden die Blockgruppe und die Inode-Tabelle lokalisiert, in der sich der Inode befindet , und entsprechend der Der Inode-Datensatz findet den Datenblock des Protokolls.
Der Name der Nachrichtendatei und der entsprechende Inode-Zeiger werden im Datenblock der Protokollverzeichnisdatei aufgezeichnet, und die Blockgruppe und der Speicherort des Inodes werden aufgezeichnet Suchen Sie über diese Inode-Tabelle und suchen Sie den Datenblock der Nachrichten basierend auf dem Inode-Datensatz.
Lesen Sie abschließend den Datenblock, der den Nachrichten entspricht.
Es ist einfacher zu verstehen, nachdem der GDT-Teil der obigen Schritte vereinfacht wurde. Wie folgt: Finden Sie den Inode von „/“--> Finden Sie den Datenblock von /, lesen Sie den Inode von var--> > Suchen Sie die Daten des Protokollblocks, lesen Sie den Inode von Nachrichten. -> Suchen Sie die Datenblöcke von Nachrichten und lesen Sie sie.
4.6.2 Dateien löschen, umbenennen und verschieben
Beachten Sie, dass es sich hierbei um einen Vorgang handelt, der das Dateisystem nicht durchquert.
Gelöschte Dateien werden in normale Dateien und Verzeichnisdateien unterteilt. Wenn Sie die Löschprinzipien dieser beiden Dateitypen kennen, wissen Sie, wie Sie andere Arten spezieller Dateien löschen .
Zum Löschen gewöhnlicher Dateien: Suchen Sie den Inode und den Datenblock der Datei (finden Sie ihn gemäß der Methode im vorherigen Abschnitt); markieren Sie die Inode-Nummer der Datei als unbekannt in imap Verwenden Sie die Blocknummer, die dem Datenblock in der Bmap entspricht, und löschen Sie die Datensatzzeile, in der sich der Dateiname im Datenblock des Verzeichnisses befindet, in dem er sich befindet zum Inode gehen verloren.
Zum Löschen von Verzeichnisdateien: Suchen Sie den Inode und den Datenblock aller Dateien, Unterverzeichnisse und Unterdateien im Verzeichnis. Markieren Sie diese Inode-Nummern in der IMAP Die Nummer wird als nicht verwendet markiert. Löschen Sie die Datensatzzeile, in der sich der Verzeichnisname im Datenblock des übergeordneten Verzeichnisses befindet. Es ist zu beachten, dass das Löschen der Datensätze im Datenblock des übergeordneten Verzeichnisses der letzte Schritt ist. Wenn dieser Schritt im Voraus ausgeführt wird, wird ein Fehler „Verzeichnis nicht leer“ gemeldet, da im Verzeichnis noch Dateien belegt sind.
Das Umbenennen von Dateien ist in das Umbenennen innerhalb desselben Verzeichnisses und das Umbenennen innerhalb verschiedener Verzeichnisse unterteilt. Das Umbenennen in verschiedene Verzeichnisse ist eigentlich der Vorgang des Verschiebens von Dateien, siehe unten.
Das Umbenennen einer Datei im selben Verzeichnis dient lediglich der Änderung des im Datenblock des Verzeichnisses aufgezeichneten Dateinamens und ist kein Lösch- und Wiederherstellungsprozess .
Wenn beim Umbenennen ein Dateinamenskonflikt auftritt (der Dateiname ist bereits im Verzeichnis vorhanden), werden Sie gefragt, ob er überschrieben werden soll. Der Überschreibvorgang besteht darin, die Datensätze widersprüchlicher Dateien im Verzeichnisdatenblock zu überschreiben. Beispielsweise gibt es a.txt und a.log unter /tmp/. Wenn Sie a.txt in a.log umbenennen, werden Sie aufgefordert, die Datensätze zu a.log in den Daten zu überschreiben Der Block von /tmp wird zu diesem Zeitpunkt überschrieben.
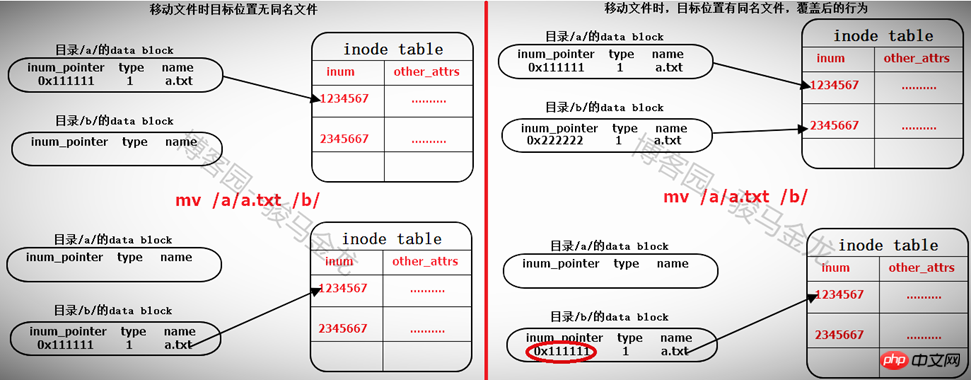
Dateien verschieben
Das Verschieben von Dateien unter dasselbe Dateisystem ändert tatsächlich den Datenblock des Verzeichnisses, in dem sich das Ziel befindet Datei befindet sich darin. Fügen Sie eine Zeile hinzu, die auf den Inode-Zeiger der zu verschiebenden Datei in der Inode-Tabelle zeigt. Wenn sich im Zielpfad eine Datei mit demselben Namen befindet, werden Sie gefragt, ob diese überschrieben werden soll Tatsächlich wird der Datensatz der in Konflikt stehenden Datei im Verzeichnisdatenblock überschrieben, da der Inode-Datensatzzeiger der gleichnamigen Datei „Überschreiben“ ist, sodass der Datenblock der Datei nicht mehr gefunden werden kann, was bedeutet, dass die Datei markiert ist zum Löschen (bei mehreren Hardlinks ist das etwas anderes).
Das Verschieben von Dateien innerhalb desselben Dateisystems erfolgt also sehr schnell. Es wird nur ein Datensatz im Datenblock des Verzeichnisses hinzugefügt oder überschrieben. Daher ändert sich beim Verschieben einer Datei die Inode-Nummer der Datei nicht.
Das Verschieben innerhalb verschiedener Dateisysteme entspricht dem erst Kopieren und dann Löschen. Siehe unten.
4.6.1 存储和复制文件
对于文件存储
(1).读取GDT,找到各个(或部分)块组imap中未使用的inode号,并为待存储文件分配inode号;
(2).在inode table中完善该inode号所在行的记录;
(3).在目录的data block中添加一条该文件的相关记录;
(4).将数据填充到data block中。
注意,填充到data block中的时候会调用block分配器:一次分配4KB大小的block数量,当填充完4KB的data block后会继续调用block分配器分配4KB的block,然后循环直到填充完所有数据。也就是说,如果存储一个100M的文件需要调用block分配器100*1024/4=25600次。
另一方面,在block分配器分配block时,block分配器并不知道真正有多少block要分配,只是每次需要分配时就分配,在每存储一个data block前,就去bmap中标记一次该block已使用,它无法实现一次标记多个bmap位。这一点在ext4中进行了优化。
(5)填充完之后,去inode table中更新该文件inode记录中指向data block的寻址指针。
对于复制,完全就是另一种方式的存储文件。步骤和存储文件的步骤一样。
4.7 多文件系统关联
在单个文件系统中的文件操作和多文件系统中的操作有所不同。本文将对此做出非常详细的说明。
4.7.1 根文件系统的特殊性
这里要明确的是,任何一个文件系统要在Linux上能正常使用,必须挂载在某个已经挂载好的文件系统中的某个目录下,例如/dev/cdrom挂载在/mnt上,/mnt目录本身是在"/"文件系统下的。而且任意文件系统的一级挂载点必须是在根文件系统的某个目录下,因为只有"/"是自引用的。这里要说明挂载点的级别和自引用的概念。
假如/dev/sdb1挂载在/mydata上,/dev/cdrom挂载在/mydata/cdrom上,那么/mydata就是一级挂载点,此时/mydata已经是文件系统/dev/sdb1的入口了,而/dev/cdrom所挂载的目录/mydata/cdrom是文件系统/dev/sdb1中的某个目录,那么/mydata/cdrom就是二级挂载点。一级挂载点必须在根文件系统下,所以可简述为:文件系统2挂载在文件系统1中的某个目录下,而文件系统1又挂载在根文件系统中的某个目录下。
再解释自引用。首先要说的是,自引用的只能是文件系统,而文件系统表现形式是一个目录,所以自引用是指该目录的data block中,"."和".."的记录中的inode指针都指向inode table中同一个inode记录,所以它们inode号是相同的,即互为硬链接。而根文件系统是唯一可以自引用的文件系统。
[root@xuexi /]# ll -ai /total 102 2 dr-xr-xr-x. 22 root root 4096 Jun 6 18:13 . 2 dr-xr-xr-x. 22 root root 4096 Jun 6 18:13 ..
由此也能解释cd /.和cd /..的结果都还是在根下,这是自引用最直接的表现形式。
[root@xuexi tmp]# cd /. [root@xuexi /]# [root@xuexi tmp]# cd /.. [root@xuexi /]#
但是有一个疑问,根目录下的"."和".."都是"/"目录的硬链接,所以除去根目录下目录数后的硬链接数位3,但实际却为2,不知道这是为何?
[root@server2 tmp]# a=$(ls -al / | grep "^d" |wc -l) [root@server2 tmp]# b=$(ls -l / | grep "^d" |wc -l) [root@server2 tmp]# echo $((a - b))2
4.7.2 挂载文件系统的细节
挂载文件系统到某个目录下,例如"mount /dev/cdrom /mnt",挂载成功后/mnt目录中的文件全都暂时不可见了,且挂载后权限和所有者(如果指定允许普通用户挂载)等的都改变了,知道为什么吗?
下面就以通过"mount /dev/cdrom /mnt"为例,详细说明挂载过程中涉及的细节。
在将文件系统/dev/cdrom(此处暂且认为它是文件系统)挂载到挂载点/mnt之前,挂载点/mnt是根文件系统中的一个目录,"/"的data block中记录了/mnt的一些信息,其中包括inode指针inode_n,而在inode table中,/mnt对应的inode记录中又存储了block指针block_n,此时这两个指针还是普通的指针。
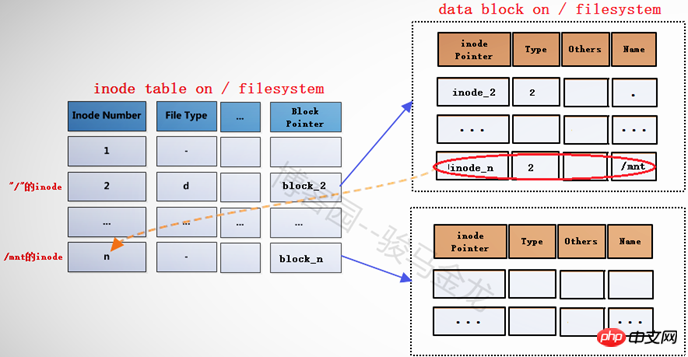
当文件系统/dev/cdrom挂载到/mnt上后,/mnt此时就已经成为另一个文件系统的入口了,因此它需要连接两边文件系统的inode和data block。但是如何连接呢?如下图。
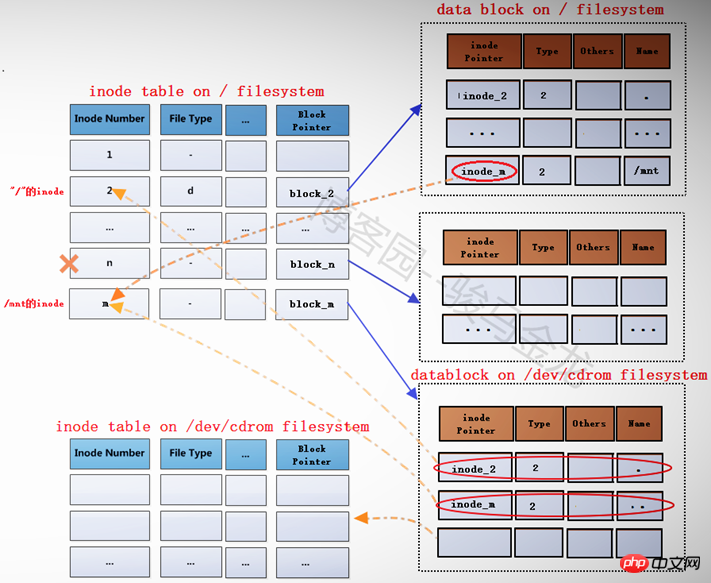
在根文件系统的inode table中,为/mnt重新分配一个inode记录m,该记录的block指针block_m指向文件系统/dev/cdrom中的data block。既然为/mnt分配了新的inode记录m,那么在"/"目录的data block中,也需要修改其inode指针为inode_m以指向m记录。同时,原来inode table中的inode记录n就被标记为暂时不可用。
block_m指向的是文件系统/dev/cdrom的data block,所以严格说起来,除了/mnt的元数据信息即inode记录m还在根文件系统上,/mnt的data block已经是在/dev/cdrom中的了。这就是挂载新文件系统后实现的跨文件系统,它将挂载点的元数据信息和数据信息分别存储在不同的文件系统上。
挂载完成后,将在/proc/self/{mounts,mountstats,mountinfo}这三个文件中写入挂载记录和相关的挂载信息,并会将/proc/self/mounts中的信息同步到/etc/mtab文件中,当然,如果挂载时加了-n参数,将不会同步到/etc/mtab。
而卸载文件系统,其实质是移除临时新建的inode记录(当然,在移除前会检查是否正在使用)及其指针,并将指针指回原来的inode记录,这样inode记录中的block指针也就同时生效而找回对应的data block了。由于卸载只是移除inode记录,所以使用挂载点和文件系统都可以实现卸载,因为它们是联系在一起的。
下面是分析或结论。
(1).挂载点挂载时的inode记录是新分配的。
# 挂载前挂载点/mnt的inode号
[root@server2 tmp]# ll -id /mnt100663447 drwxr-xr-x. 2 root root 6 Aug 12 2015 /mnt [root@server2 tmp]# mount /dev/cdrom /mnt
# 挂载后挂载点的inode号 [root@server2 tmp]# ll -id /mnt 1856 dr-xr-xr-x 8 root root 2048 Dec 10 2015 mnt
由此可以验证,inode号确实是重新分配的。
(2).挂载后,挂载点的内容将暂时不可见、不可用,卸载后文件又再次可见、可用。
# 在挂载前,向挂载点中创建几个文件 [root@server2 tmp]# touch /mnt/a.txt [root@server2 tmp]# mkdir /mnt/abcdir
# 挂载 [root@server2 tmp]# mount /dev/cdrom /mnt # 挂载后,挂载点中将找不到刚创建的文件 [root@server2 tmp]# ll /mnt total 636-r--r--r-- 1 root root 14 Dec 10 2015 CentOS_BuildTag dr-xr-xr-x 3 root root 2048 Dec 10 2015 EFI-r--r--r-- 1 root root 215 Dec 10 2015 EULA-r--r--r-- 1 root root 18009 Dec 10 2015 GPL dr-xr-xr-x 3 root root 2048 Dec 10 2015 images dr-xr-xr-x 2 root root 2048 Dec 10 2015 isolinux dr-xr-xr-x 2 root root 2048 Dec 10 2015 LiveOS dr-xr-xr-x 2 root root 612352 Dec 10 2015 Packages dr-xr-xr-x 2 root root 4096 Dec 10 2015 repodata-r--r--r-- 1 root root 1690 Dec 10 2015 RPM-GPG-KEY-CentOS-7-r--r--r-- 1 root root 1690 Dec 10 2015 RPM-GPG-KEY-CentOS-Testing-7-r--r--r-- 1 root root 2883 Dec 10 2015 TRANS.TBL # 卸载后,挂载点/mnt中的文件将再次可见 [root@server2 tmp]# umount /mnt [root@server2 tmp]# ll /mnt total 0drwxr-xr-x 2 root root 6 Jun 9 08:18 abcdir-rw-r--r-- 1 root root 0 Jun 9 08:18 a.txt
Der Grund dafür ist, dass nach dem Mounten des Dateisystems der ursprüngliche Inode-Datensatz des Mount-Punkts vorübergehend als nicht verfügbar markiert wird. Der Schlüssel liegt darin, dass kein Inode-Zeiger auf den Inode-Datensatz verweist. Nachdem das Dateisystem deinstalliert wurde, wird der ursprüngliche Inode-Datensatz des Mount-Punkts wieder aktiviert und der Inode-Zeiger von mnt im Verzeichnis „/“ zeigt erneut auf den Inode-Datensatz.
(3) Nach dem Mounten werden die Metadaten und der Datenblock des Mountpunkts in verschiedenen Dateisystemen gespeichert.
(4). Auch nachdem der Mountpunkt gemountet wurde, gehört er immer noch zur Datei des Quelldateisystems.
4.7.3 Betriebszuordnung für mehrere Dateisysteme
Angenommen, der Kreis im Bild unten stellt eine Festplatte dar, die in 3 Bereiche, also 3 Dateisysteme, unterteilt ist. Unter diesen ist root das Root-Dateisystem, /mnt ist der Eintrag eines anderen Dateisystems A, Dateisystem A ist auf /mnt gemountet, /mnt/cdrom ist auch der Eintrag von Dateisystem B und Dateisystem B ist gemountet /mnt/cdrom. Jedes Dateisystem verwaltet einige Inode-Tabellen. Es wird davon ausgegangen, dass die Inode-Tabelle in der Abbildung eine Sammlungstabelle von Inode-Tabellen in allen Blockgruppen jedes Dateisystems ist.

Wie lese ich /var/log/messages? Hierbei handelt es sich um das Lesen von Dateien im selben Dateisystem wie „/“, das im vorherigen Einzeldateisystem ausführlich erläutert wurde.
Aber wie liest man /mnt/a.log im A-Dateisystem? Suchen Sie zuerst den Inode-Datensatz von /mnt im Root-Dateisystem. Suchen Sie dann den Datenblock von /mnt basierend auf dem Blockzeiger dieses Inode-Datensatzes Dateisystem A; Lesen Sie dann den a.log-Datensatz aus dem Datenblock von /mnt und suchen Sie schließlich den Inode-Datensatz, der a.log entspricht, in der Inode-Tabelle des A-Dateisystems. Finden Sie einen vom Blockzeiger dieses Inode-Protokolldatenblocks. Zu diesem Zeitpunkt kann der Inhalt der Datei /mnt/a.log gelesen werden.
Das Bild unten kann den obigen Prozess vollständiger beschreiben.
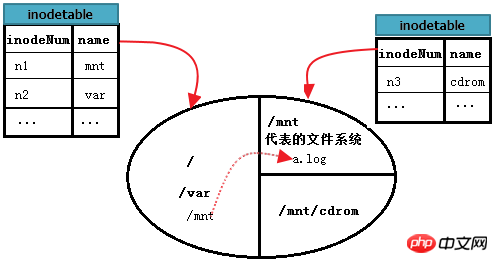
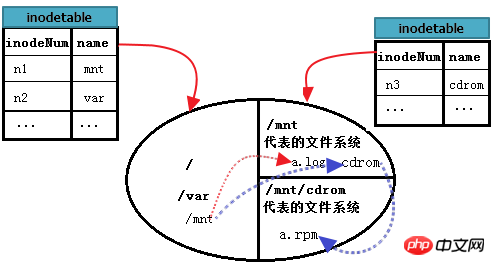
Wie liest man also /mnt/cdrom/a.rpm in /mnt/cdrom? Der hier durch cdrom dargestellte Mountpunkt des Dateisystems B befindet sich unter /mnt, daher ist noch ein weiterer Schritt erforderlich. Suchen Sie zuerst „/“, suchen Sie dann mnt im Stammverzeichnis, geben Sie das mnt-Dateisystem ein, suchen Sie den Datenblock von cdrom und geben Sie dann cdrom ein, um a.rpm zu finden. Mit anderen Worten: Der Speicherort der mnt-Verzeichnisdateien ist das Stammverzeichnis, der Speicherort der cdrom-Verzeichnisdateien ist mnt und schließlich ist der Speicherort von a.rpm cdrom.
Verbessern Sie das Bild oben weiter. wie folgt.
4.8 Die Protokollfunktion des ext3-Dateisystems
Im Vergleich zum ext2-Dateisystem verfügt ext3 über ein zusätzliches Protokoll Funktion.
Im ext2-Dateisystem gibt es nur zwei Bereiche: Datenbereich und Metadatenbereich. Kommt es beim Einfüllen von Daten in den Datenblock zu einem plötzlichen Stromausfall, wird beim nächsten Start die Konsistenz der Daten und des Status im Dateisystem überprüft. Diese Überprüfung und Reparatur kann viel Zeit in Anspruch nehmen Auch nach der Überprüfung ist eine Reparatur nicht mehr möglich. Der Grund dafür ist, dass das Dateisystem nach einem plötzlichen Stromausfall nicht weiß, wo der Block der zuletzt gespeicherten Datei beginnt und endet. Daher wird das gesamte Dateisystem gescannt, um ihn auszuschließen (möglicherweise wird dies auf diese Weise überprüft). ).
Beim Erstellen eines ext3-Dateisystems wird es in drei Bereiche unterteilt: Datenbereich, Protokollbereich und Metadatenbereich. Bei jeder Speicherung von Daten werden die Aktivitäten des Metadatenbereichs in ext2 zunächst im Protokollbereich ausgeführt. Erst wenn die Datei mit „Commit“ markiert wird, werden die Daten im Protokollbereich in den Metadatenbereich übertragen. Wenn es beim Speichern von Dateien zu einem plötzlichen Stromausfall kommt, müssen Sie bei der nächsten Überprüfung und Reparatur des Dateisystems nur die Datensätze im Protokollbereich überprüfen, den der BMAP entsprechenden Datenblock als nicht verwendet markieren und die Inode-Nummer markieren als unbenutzt, sodass Sie nicht die gesamte Datei scannen müssen. Das System nimmt viel Zeit in Anspruch.
Obwohl ext3 einen Log-Bereich mehr hat als ext2, das den Metadatenbereich konvertiert, ist die Leistung von ext3 etwas schlechter als die von ext2, insbesondere beim Schreiben vieler kleiner Dateien. Aufgrund anderer Optimierungen von ext3 besteht jedoch nahezu kein Leistungsunterschied zwischen ext3 und ext2.
4.9 ext4-Dateisystem
Es erinnert an die vorherigen Speicherformate der ext2- und ext3-Dateisysteme und verwendet Blöcke als Speichereinheiten, und jeder Block verwendet Bmap-Bits werden verwendet, um zu markieren, ob sie frei sind. Obwohl die Effizienz durch die Optimierung der Methode zur Aufteilung von Blockgruppen verbessert wird, wird bmap weiterhin innerhalb einer Blockgruppe verwendet, um die Blöcke in der Blockgruppe zu markieren. Bei einer riesigen Datei ist das Scannen der gesamten Bmap ein riesiges Projekt. Darüber hinaus verwendet ext2/3 im Hinblick auf die Inode-Adressierung direkte und indirekte Adressierungsmethoden. Bei indirekten Zeigern mit drei Ebenen ist die Anzahl der Zeiger, die durchlaufen werden können, sehr, sehr groß.
Das größte Merkmal des ext4-Dateisystems besteht darin, dass es mithilfe des Extent-Konzepts (Extent oder Segment) basierend auf ext3 verwaltet wird. Ein Extent enthält möglichst viele physisch zusammenhängende Blöcke. Auch die Inode-Adressierung wurde mithilfe des Abschnittsbaums verbessert.
Standardmäßig verwendet EXT4 nicht mehr die Blockzuordnungsmethode von EXT3, sondern stattdessen die Extent-Zuweisungsmethode.
(1). In Bezug auf die strukturellen Eigenschaften von EXT4
EXT4 ähnelt in seiner Gesamtstruktur den großen Zuordnungsrichtungen, die auf Blockgruppen gleicher Größe basieren Jede Blockgruppe ist festgelegt. Anzahl der Inodes, möglicher Superblock (oder Backup) und GDT.
Die Inode-Struktur von EXT4 wurde erheblich geändert, um neue Informationen hinzuzufügen. Die Größe wurde von EXT3 auf die standardmäßigen 256 Bytes erhöht. Gleichzeitig wird der Inode-Adressierungsindex nicht mehr verwendet EXT3s „12 direkt“ Der Indexmodus ist „Adressierungsblock + 1 indirekter Adressierungsblock der ersten Ebene + 1 indirekter Adressierungsblock der zweiten Ebene + 1 indirekter Adressierungsblock der dritten Ebene“ und wird in 4 Extent-Fragmentströme geändert, wobei jeder Fragmentstrom vorhanden ist set Die Startblocknummer des Fragments und die Anzahl aufeinanderfolgender Blöcke (er kann direkt auf den Datenbereich oder auf den Indexblockbereich verweisen).
Der Fragmentstrom ist der grüne Bereich im Indexknotenblock (Inde-Knotenblock) in der folgenden Abbildung, jeweils 15 Bytes, insgesamt 60 Bytes.
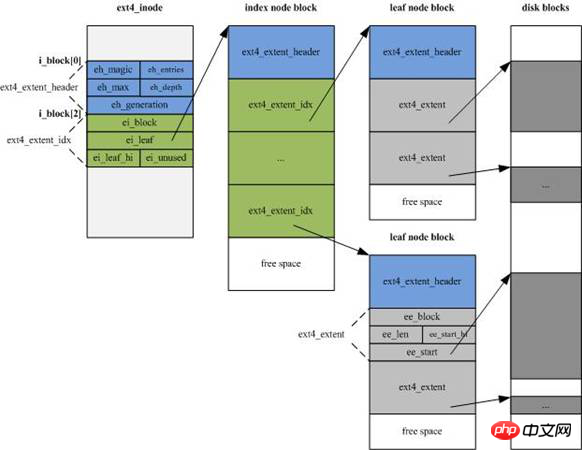
(2) löscht die strukturellen Änderungen der Daten.
Nach dem Löschen der Daten gibt EXT4 nacheinander die Bitmap-Speicherplatzbits des Dateisystems frei, aktualisiert die Verzeichnisstruktur und gibt die Inode-Speicherplatzbits nacheinander frei.
(3). ext4 verwendet die Mehrblockzuweisung.
Beim Speichern von Daten kann der Blockzuordner in ext3 jeweils nur 4-KB-Blöcke zuweisen, und bmap wird einmal markiert, bevor jeder Block gespeichert wird. Wenn eine 1G-Datei gespeichert ist und die Blockgröße 4 KB beträgt, wird der Blockzuordner einmal aufgerufen, nachdem jeder Block gespeichert wurde, d markiert ist auch 1024*1024/4= 262.144 mal.
In ext4 basiert die Zuweisung auf Abschnitten. Es ist möglich, eine Reihe aufeinanderfolgender Blöcke zuzuweisen, indem man den Blockzuordner einmal aufruft und die entsprechende Bmap sofort markiert, bevor diese Reihe von Blöcken gespeichert wird. Dies verbessert die Speichereffizienz für große Dateien erheblich.
4.10 Nachteile des ext-Dateisystems
Der größte Nachteil besteht darin, dass beim Erstellen des Dateisystems alles aufgeteilt werden kann direkt bei der Verwendung, was bedeutet, dass es keine dynamische Partitionierung und dynamische Zuordnung unterstützt. Bei kleineren Partitionen ist die Geschwindigkeit in Ordnung, bei einer sehr großen Festplatte ist die Geschwindigkeit jedoch extrem langsam. Wenn Sie beispielsweise ein Festplatten-Array mit mehreren zehn Terabyte in ein ext4-Dateisystem formatieren, verlieren Sie möglicherweise die Geduld.
Neben der extrem langsamen Formatierungsgeschwindigkeit ist das ext4-Dateisystem immer noch sehr vorzuziehen. Natürlich haben die von verschiedenen Unternehmen entwickelten Dateisysteme ihre eigenen Eigenschaften. Das Wichtigste ist, den geeigneten Dateisystemtyp entsprechend Ihren Anforderungen auszuwählen.
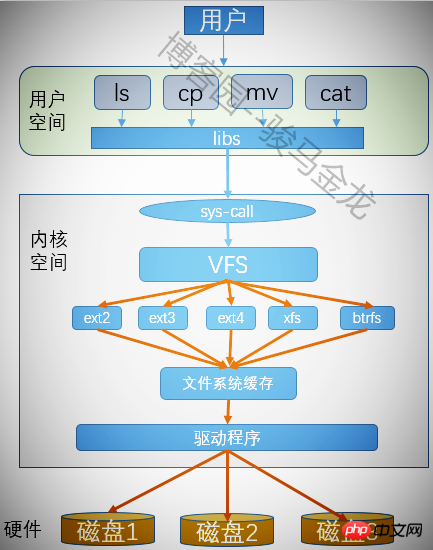
4.11 Virtuelles Dateisystem VFS
Ein Dateisystem kann erstellt werden, nachdem jede Partition formatiert wurde. Viele Dateisysteme können unter Linux erkannt werden um es zu identifizieren? Wenn wir die Dateien in der Partition bedienen, haben wir außerdem nicht angegeben, zu welchem Dateisystem sie gehören. Wie können unsere Benutzer verschiedene Dateisysteme wahllos bedienen? Dies ist, was ein virtuelles Dateisystem tut.
Das virtuelle Dateisystem bietet Benutzern eine gemeinsame Schnittstelle zum Betrieb verschiedener Dateisysteme, sodass Benutzer beim Ausführen eines Programms nicht berücksichtigen müssen, auf welchem Dateisystemtyp sich die Datei befindet und welche Art von Systemaufrufen sie ausführen Zur Bedienung der Datei sollten Systemfunktionen verwendet werden. Mit dem virtuellen Dateisystem müssen Sie nur den Systemaufruf von VFS für alle auszuführenden Programme aufrufen, und VFS hilft bei der Ausführung der verbleibenden Aktionen.
Bitte geben Sie die Quelle für den Nachdruck an:
Das obige ist der detaillierte Inhalt vonext-Dateisystemmechanismus. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Erfahren Sie, wie Sie den Nginx-Server unter Linux installieren
- Detaillierte Einführung in den wget-Befehl von Linux
- Ausführliche Erläuterung von Beispielen für die Verwendung von yum zur Installation von Nginx unter Linux
- Detaillierte Erläuterung der Worker-Verbindungsprobleme in Nginx
- Detaillierte Erläuterung des Installationsprozesses von Python3 unter Linux