
Heim >Backend-Entwicklung >Python-Tutorial >Crawler&Problemlösung&Denken
Crawler&Problemlösung&Denken
- 巴扎黑Original
- 2017-06-23 14:47:361611Durchsuche
Ich bin gerade erst mit Python in Kontakt gekommen und suche nach kleinen Aufgaben, um meine Fähigkeiten weiter zu üben. Dieser kleine Crawler stammt aus einem Kurs auf MOOC. Was ich hier aufzeichne, sind die Probleme und Lösungen, auf die ich während meines Lernprozesses gestoßen bin, sowie meine Gedanken außerhalb des Crawlers.
Diese kleine Aufgabe besteht darin, einen kleinen Crawler zu schreiben. Der wichtigste Grund, warum ich mich für diese Übung entschieden habe, ist, dass Big Data zu heiß ist, genau wie das aktuelle Wetter in Wuhan. Daten sind für „Big Data“ das, was Waffen für Soldaten und Ziegel und Dachziegel für Hochhäuser sind. Ohne Daten ist „Big Data“ nur ein Luftraum, der überhaupt nicht in die Praxis umgesetzt werden kann. Woher kommen die Daten? Es gibt zwei Möglichkeiten: Die eine besteht darin, es von sich selbst zu nehmen, die andere darin, es von anderen zu nehmen. Selbstverständlich besteht die andere Möglichkeit darin, Dinge von anderen zu nehmen, und dieses „Andere“ bezieht sich auf das Internet.
Zunächst müssen Sie Crawler verstehen: Ein Programm oder Skript, das automatisch World Wide Web-Informationen nach bestimmten Regeln erfasst (aus der Baidu-Enzyklopädie) . Wie der Name schon sagt, müssen Sie die Seite besuchen, den Inhalt auf der Seite speichern, dann den Inhalt, der Sie interessiert, aus der gespeicherten Seite herausfiltern und ihn dann separat speichern. Im wirklichen Leben machen wir so etwas oft: An einem langweiligen Nachmittag geben wir eine Adresse in den Browser ein, um auf die Seite zuzugreifen, stoßen dann auf einen interessanten Artikel oder Absatz, wählen ihn aus und kopieren ihn dann und fügen ihn in ein Wort ein dokumentieren. . Wenn wir das, was wir oben mit einer Seite gemacht haben, auch mit Millionen von Seiten machen, werden Ihre Daten immer größer. Wir nennen diesen Prozess „Datenerfassung“.
Der Vorteil von Crawlern ist: Automatisierung und Batchverarbeitung. Hier liegt ein Missverständnis vor, bevor ich mit Crawlern in Kontakt kam. Ich dachte, Crawler könnten Dinge crawlen, die ich „nicht sehen“ konnte.
Das Folgende ist die Architektur und der Crawling-Prozess dieses Crawlers
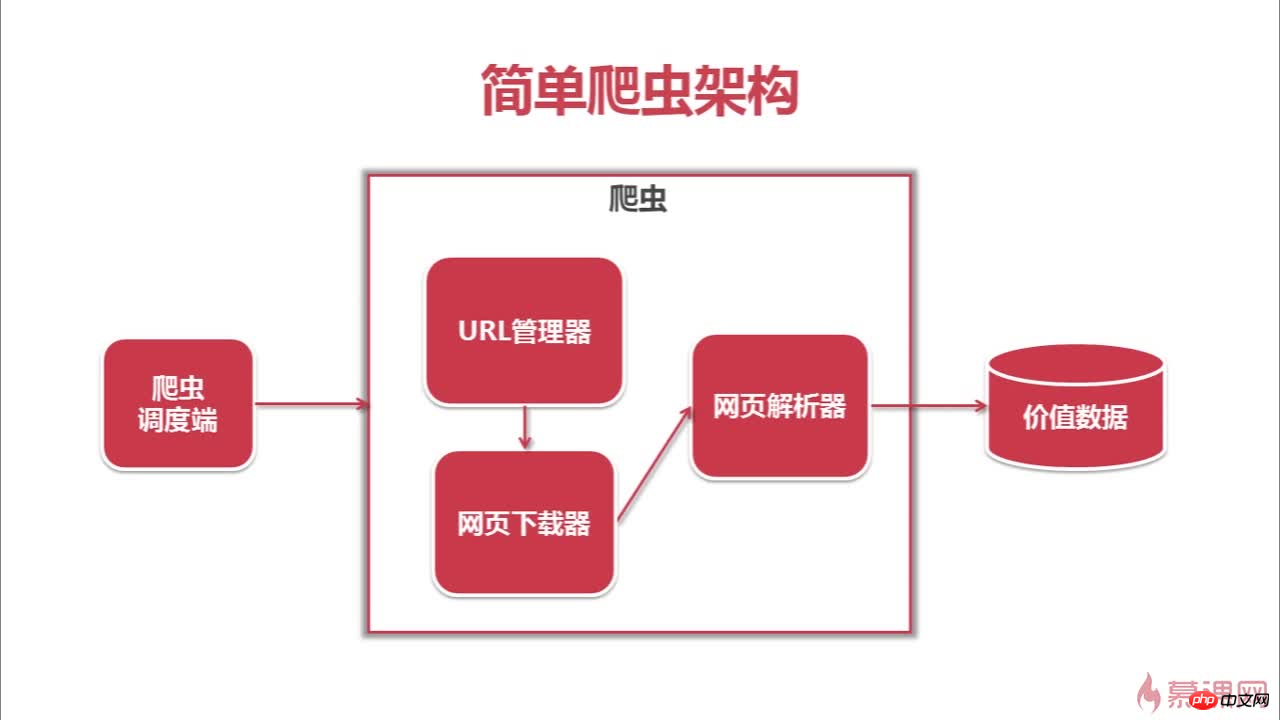
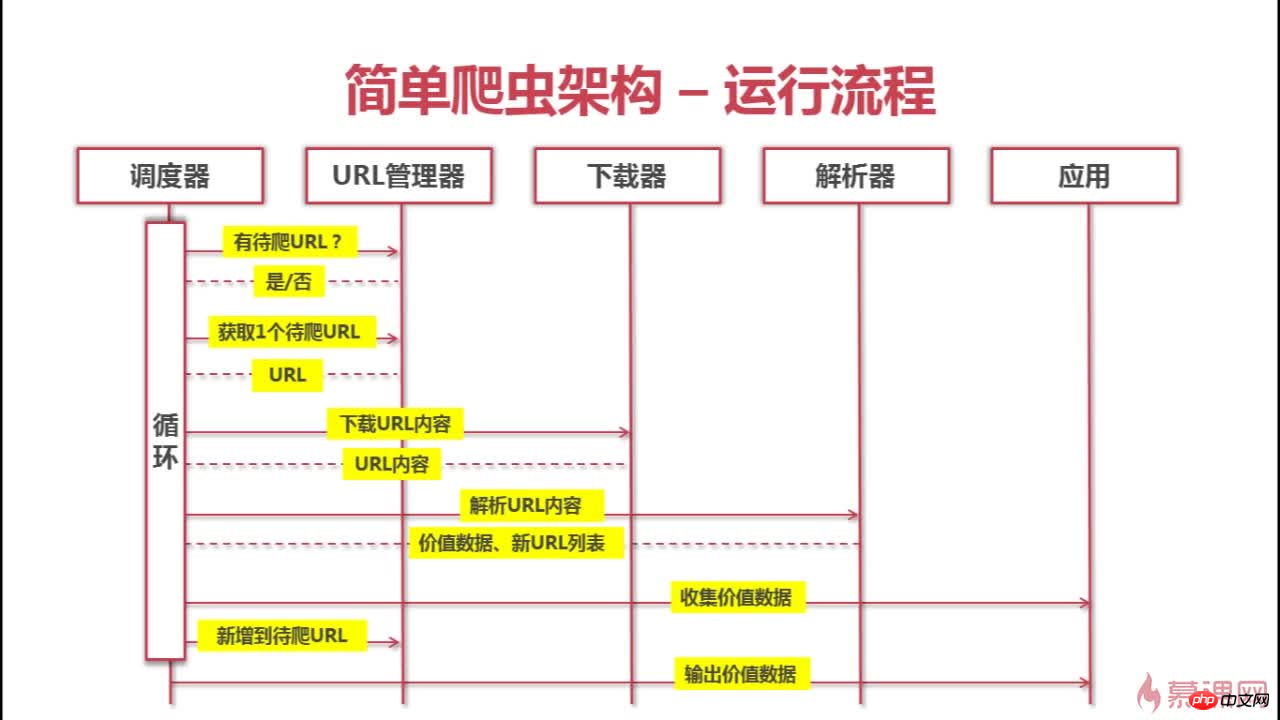
Das obige ist der detaillierte Inhalt vonCrawler&Problemlösung&Denken. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!