
Heim >Datenbank >MySQL-Tutorial >Testfall zur MySQL-Paging-Optimierung
Testfall zur MySQL-Paging-Optimierung

- PHP中文网Original
- 2017-06-20 15:27:551422Durchsuche
Kürzlich habe ich versehentlich einen Testfall für die MySQL-Paging-Optimierung gesehen, ohne dass das Testszenario sehr konkret erklärt wurde.
Weil es in Wirklichkeit viele gibt. Die Situation ist nicht behoben . Um allgemeine Praktiken oder Regeln zusammenfassen zu können, müssen wir viele Szenarien berücksichtigen. Wenn wir mit Möglichkeiten zur Optimierung konfrontiert werden, müssen wir den gleichen Ansatz untersuchen verändert und der Optimierungseffekt nicht erzielt werden kann, müssen die Gründe dafür untersucht werden.
Ich habe persönlich Zweifel an der Verwendung dieses Szenarios geäußert, es dann selbst getestet, einige Probleme festgestellt und auch einige erwartete Ideen bestätigt.
In diesem Artikel wird eine einfache Analyse der MySQL-Paging-Optimierung durchgeführt, beginnend mit der einfachsten Situation.
MySQLs klassischer Paging-„Optimierungs“-Ansatz
Bei der MySQL-Paging-Optimierung gibt es ein klassisches Problem: Je mehr „Back“-Daten abgefragt werden, desto langsamer sind sie (Abhängig von der Tabelle) Der Indextyp, für B-Tree-strukturierte Indizes gilt dasselbe in SQL Server)
select * from t order by id limit m,n. Das heißt, mit zunehmendem M wird die Abfrage derselben Datenmenge immer langsamer.
Angesichts dieses Problems wurde ein klassischer Ansatz geboren, der dem ähnelt (oder eine Variante davon ist). Die folgende Schreibweise
besteht darin, zuerst die ID im Paging-Bereich separat herauszufinden, sie dann der Basistabelle zuzuordnen und schließlich die erforderlichen Daten abzufragen
* aus t auszuwählen
innerer Join (
wähle id aus t order by id limit m,n)t1 on t1.id = t.id
Wenn Filterbedingungen vorhanden sind, wird die
SQL-Anweisung zu „select * from“. t where *** order by id limit m,n
Wenn Sie der gleichen Methode folgen, schreiben Sie sie so um:
select * from t
inner join (select id from t where *** order by id limit m,n )t1 on t1.id = t.id
Kann die neu geschriebene SQL-Anweisung in diesem Fall immer noch den Zweck der Optimierung erreichen?
Einrichtung der Testumgebung
Die Testdaten sind relativ einfach und werden in einem geschrieben Schleife durch die gespeicherte Prozedur Testdaten, InnoDB-Engine-Tabelle der Testtabelle.
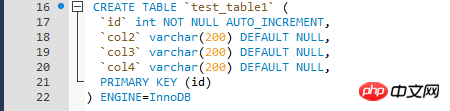
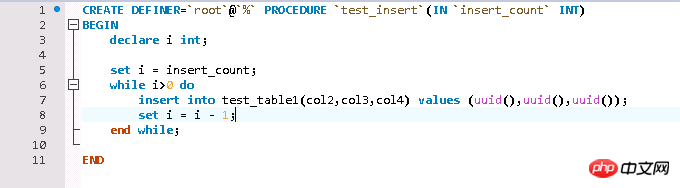

Die Gründe für die Optimierung von Paging-Abfragen
Schauen wir uns zunächst dieses klassische Problem an: Je „rückwärts“ die Abfrage ist, desto langsamer ist die Antwort ist
Test 1: Abfrage der ersten 1-20 Datenzeilen, 0,01 Sekunden Dieselbe Abfrage gilt für 20 Datenzeilen, Abfrage relativ „ Für spätere Daten, wie in diesem Fall die Datenzeilen 4900001–4900020, dauerte es 1,97 Sekunden. 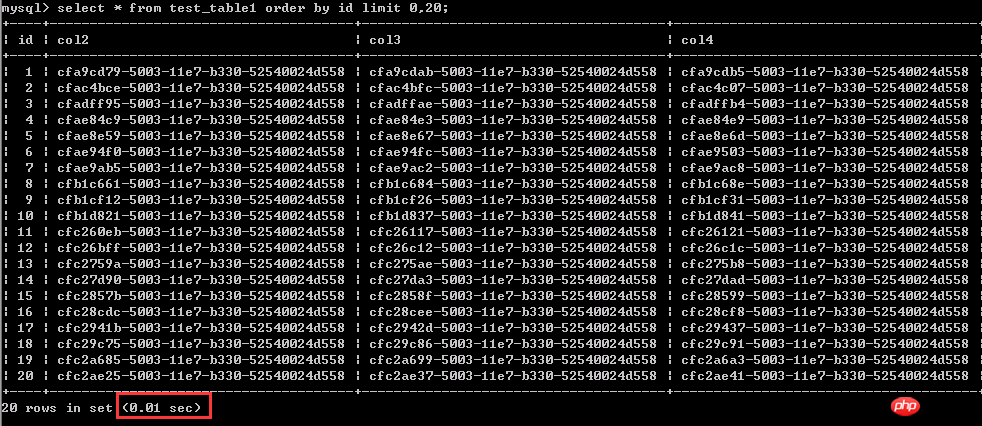
Daraus ist ersichtlich, dass die Abfrageeffizienz umso geringer ist, wenn die Abfragebedingungen unverändert bleiben. Dieselbe Suche nach 20 Datenzeilen. Je weiter die Daten entfernt sind, desto höher sind die Abfragekosten.  Warum Letzteres weniger effizient ist, werden wir später analysieren.
Warum Letzteres weniger effizient ist, werden wir später analysieren.
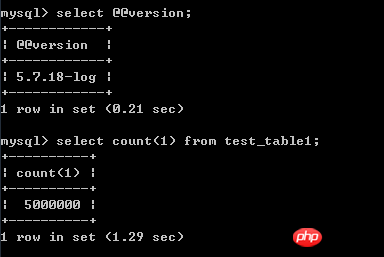
Reproduzieren Sie die klassische Paging-„Optimierung“. Wenn es keine Filterbedingungen gibt und die Sortierspalte ein Clustered-Index ist, gibt es keine Verbesserung
Hier vergleichen wir die Leistung der folgenden beiden Schreibmethoden, wenn Clustered-Index-Spalten als Sortierbedingungen verwendet werden wählen Sie * aus t order by id limit m,n.
select * from tinner join (select id from t order by id limit m,n)t1 on t1.id = t.id
select * from test_table1 order by id asc limit 4900000,20; Die Testergebnisse werden im Screenshot angezeigt, Die Ausführungszeit beträgt 8,31 Sekunden
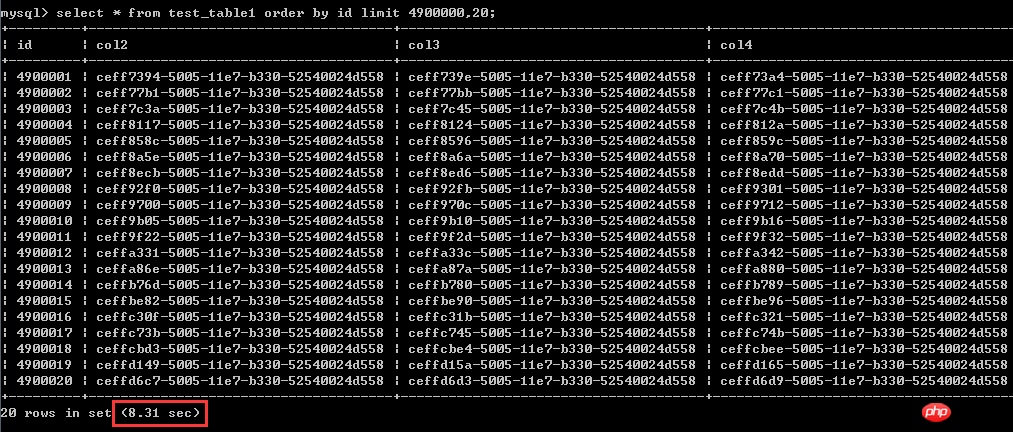
Der zweite Typ Umgeschriebenes Schreiben:
select t1.* from test_table1 t1
inner join (select id from test_table1 order by id limit 4900000,20)t2 on t1.id = t2.id;Ausführen Die Zeit beträgt 8,43 Sekunden
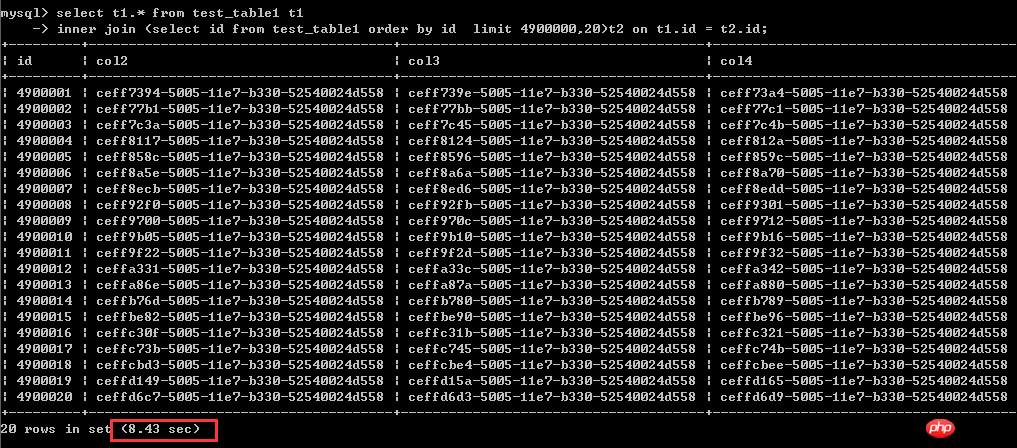
Hier ist sehr deutlich, dass sich die Leistung nach dem Umschreiben mit der klassischen Umschreibmethode überhaupt nicht und sogar nicht verbessert hat Etwas langsamer,
Der eigentliche Test zeigt, dass es keinen offensichtlichen linearen Leistungsunterschied zwischen den beiden gibt. Das Originalplakat der beiden hat mehrere Tests durchgeführt.
Wenn ich ähnliche Schlussfolgerungen sehe, muss ich sie testen. Auf diese Sache kann man sich nicht verlassen, oder auf Glück. Warum kann sie verbessert werden?
Warum hat die neu geschriebene Methode die Leistung nicht so verbessert?
Was ist der Grund, warum diese aktuelle Neufassung nicht das Ziel einer Leistungsverbesserung erreicht?
Wie verbessert Letzteres die Leistung?
Schauen Sie sich zunächst die Tabellenstruktur der Testtabelle an. Es gibt einen Index für die Sortierspalte. Der Schlüssel ist, dass der Index für die Sortierspalte der Primärschlüssel ist Index).
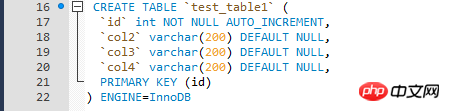
Warum kann das relativ „optimierte“ umgeschriebene SQL den Zweck der „Optimierung“ nicht erreichen, wenn die Sortierspalte ein Clustered-Index ist?
Beim Sortieren Wenn es sich bei der Spalte um eine Clustered-Index-Spalte handelt, scannen beide nacheinander die Tabelle, um qualifizierte Daten abzufragen
Obwohl letztere zuerst eine Unterabfrage ansteuern und dann die Ergebnisse der Unterabfrage verwenden, um die Haupttabelle anzusteuern,
Die Unterabfrage ändert jedoch nichts an der Methode „Sequentielles Scannen der Tabelle, um qualifizierte Daten abzufragen“. Unter den gegenwärtigen Umständen scheint sogar die neu geschriebene Methode überflüssig zu sein
Beziehen Sie sich auf die folgenden beiden Ausführungspläne, den ersten Screenshot Eine Zeile Der Ausführungsplan entspricht im Wesentlichen der dritten Zeile des neu geschriebenen SQL-Ausführungsplans (der Zeile mit der ID = 2).


Paging-Abfrage, wenn keine Filterbedingung vorhanden ist und die Sortierspalte ein Clustered-Index ist, Die sogenannte Paging-Abfrageoptimierung ist einfach überflüssig
Derzeit sind beide Methoden zur Abfrage der oben genannten Daten sehr langsam. Was sollten Sie also tun, wenn Sie die oben genannten Daten abfragen möchten?
Wir müssen noch herausfinden, warum es langsam ist. Aus meinem eigenen groben Verständnis heraus müssen wir verstehen, dass die Abfragedaten „im Rückstand“ sind. es weicht tatsächlich von der Richtung ab Eine Richtung des B-Tree-Index, die in den folgenden beiden Screenshots gezeigten Zieldaten
Tatsächlich gibt es für die Daten im ausgeglichenen Baum keine sogenannte „Vorderseite“ und „Rückseite“. „vorne“ und „hinten“ sind beide relativ zur anderen Seite oder aus der Scanrichtung
Betrachtet man die „hinteren“ Daten aus einer Richtung, handelt es sich um die „vorderen“ Daten aus einer Richtung und die vorderen und hinteren Daten zurück sind nicht absolut.
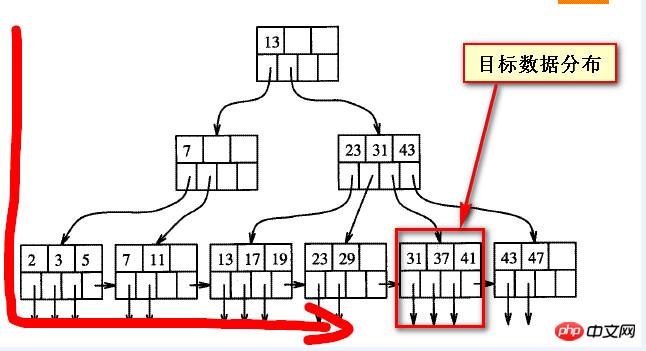
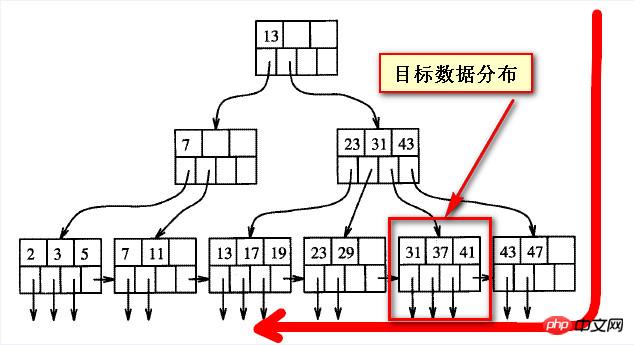
Wenn Sie für die späteren Daten das umgekehrte Scannen verwenden, sollten Sie in der Lage sein, diesen Teil der Daten schnell zu finden und die gefundenen Daten dann erneut zu sortieren (aufsteigend). Das Ergebnis sollte dasselbe sein.
Schauen wir uns zunächst den Effekt an: Das Ergebnis ist genau das gleiche wie bei der obigen Abfrage.
Es dauert nur 0,07 Sekunden. Die beiden vorherigen Schreibmethoden haben mehr als 8 Sekunden gedauert und die Effizienz beträgt Hunderte mal anders.
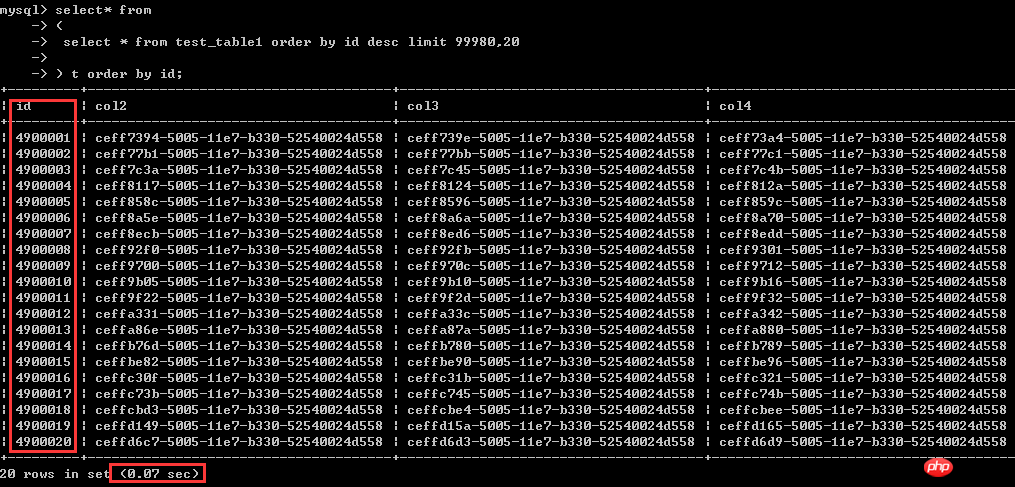
Was den Grund dafür angeht, denke ich, dass ich es anhand der obigen Erklärung verstehen sollte. Hier ist die SQL.
Wenn Sie häufig sogenannte spätere Daten abfragen, z. B. Daten mit größeren IDs oder neuere Daten in der Zeitdimension, können Sie den Rückwärtsscan-Index verwenden, um effiziente Paging-Abfragen zu erreichen
(Bitte berechnen die Seite, auf der sich die Daten hier befinden. Für die gleichen Daten ist die beginnende „Seitennummer“ in Vorwärts- und Rückwärtsreihenfolge unterschiedlich)
select* from(select * from test_table1 order by id desc limit 99980,20) t order by id;
Wenn keine Filterbedingung vorliegt und die Sortierspalte ein nicht gruppierter Index ist, wird sie verbessert
Hier sind die folgenden Änderungen an der Testtabelle test_table1
1, eine Spalte „id_2“ hinzufügen,
2, einen eindeutigen Index für dieses Feld erstellen,
3, dieses Feld mit der entsprechenden Primärschlüssel-ID füllen
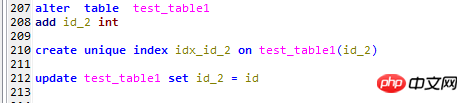
Der obige Test wird nach dem Primärschlüsselindex (Clustered-Index) sortiert, also nach der neu hinzugefügten Spalte id_2, und testen wir die beiden unter erwähnten Paging-Methoden der Anfang.
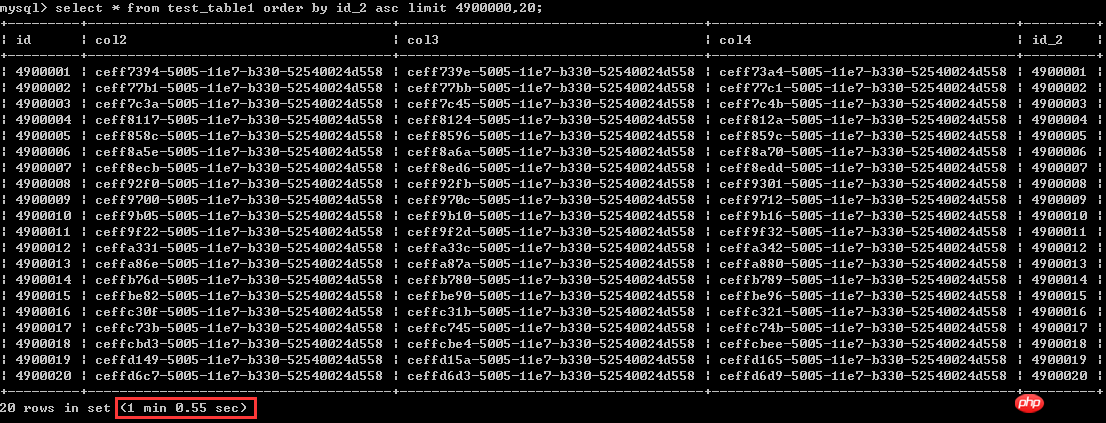
Schauen wir uns zunächst die erste Schreibweise an
Wählen Sie * aus test_table1 order by id_2 asc limit 4900000,20; die Ausführungszeit beträgt etwas mehr als 1 Minute, betrachten wir es beträgt 60 Sekunden
Die zweite Schreibweise
select t1.* from test_table1 t1
inner join (select id from test_table1 order by id_2 limit 4900000, 20)t2 on t1.id = t2.id;Ausführungszeit 1,67 Sekunden
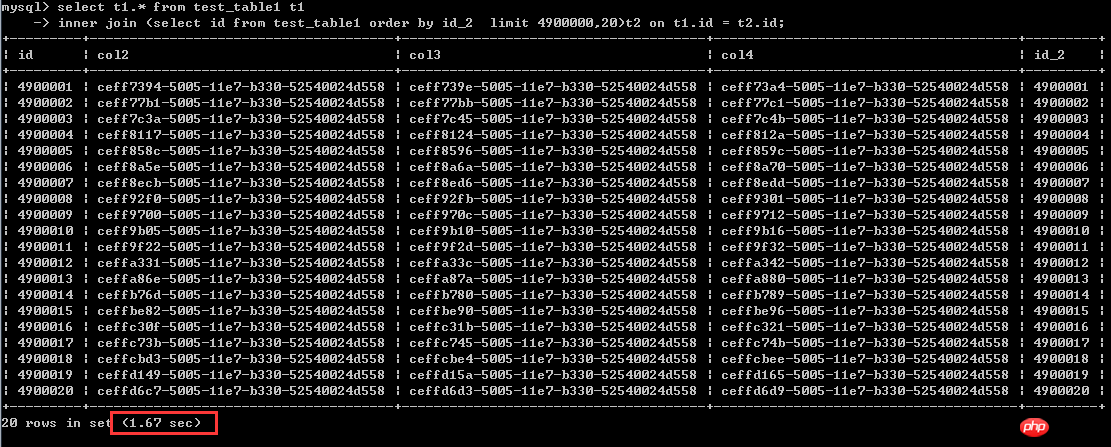
Aus dieser Situation heraus ist das so Sagen wir, die Sortierspalte ist Bei Verwendung von nicht gruppierten Indexspalten kann die letztere Schreibmethode tatsächlich die Effizienz erheblich verbessern. Das ist fast eine 40-fache Verbesserung.
Was ist also der Grund?
Schauen wir uns zunächst den Ausführungsplan der ersten Schreibweise an. Es ist einfach zu verstehen, dass die gesamte Tabelle während der Ausführung dieser SQL gescannt und dann erneut nach id_2 sortiert wird, und schließlich die oberen 20 Teile Daten erfasst werden.
Erstens ist das Scannen einer vollständigen Tabelle ein sehr zeitaufwändiger Prozess, und auch das Sortieren ist mit sehr hohen Kosten verbunden, sodass die Leistung sehr gering ist.

Schauen wir uns den Ausführungsplan des letzteren an. Zuerst wird die Unterabfrage gemäß der Indexreihenfolge auf id_2 gescannt und dann die qualifizierte Primärschlüssel-ID zur Abfrage verwendet Die Tabelle.
In diesem Fall wird vermieden, eine große Datenmenge abzufragen und dann neu zu ordnen (mithilfe von Filesort).
Wenn Sie den SQLServer-Ausführungsplan verstehen, sollten Sie im Vergleich zum ersteren den letzteren vermeiden Tabellenrückgaben ( Der in SQL Server als Schlüsselsuche oder Lesezeichensuche bezeichnete Prozess
kann als ein einmaliger Stapelprozess zur Abfrage von 20 qualifizierenden Daten in der äußeren Tabelle betrachtet werden, der von einer Unterabfrage gesteuert wird.
Tatsächlich Nur unter den aktuellen Umständen, das heißt, wenn die Sortierspalte eine nicht gruppierte Indexspalte ist, kann das neu geschriebene SQL die Effizienz von Paging-Abfragen verbessern.  Trotzdem wurde diese Methode „optimiert“. immer noch ganz anders als die Paging-Effizienz, die wie folgt geschrieben wird
Trotzdem wurde diese Methode „optimiert“. immer noch ganz anders als die Paging-Effizienz, die wie folgt geschrieben wird
Eine weitere Frage, die ich erwähnen möchte, ist: Wenn Paging-Abfragen häufig und in einer bestimmten Reihenfolge durchgeführt werden, warum nicht einen Clustered-Index für diese Spalte erstellen?
Wenn die Anweisung beispielsweise die ID automatisch erhöht oder die Zeit + andere Felder die Eindeutigkeit gewährleisten, erstellt MySQL automatisch einen Clustered-Index für den Primärschlüssel.
Beim Clustered-Index sind „vorne“ und „hinten“ dann nur relative logische Konzepte. Wenn Sie die meiste Zeit „zurück“ oder neuere Daten erhalten möchten, können Sie die obige Schreibmethode verwenden,
Optimierung von Paging-Abfragen bei Filterbedingungen
Nachdem ich über diesen Teil nachgedacht habe, ist die Situation zu kompliziert und es ist schwierig, sie zusammenzufassen. Ein sehr repräsentativer Fall herausgekommen, daher werde ich nicht zu viele Tests durchführen.
select * from t where *** order by id limit m,n
1. Beispielsweise ist die Pinselauswahlbedingung selbst sehr effizient. Sobald sie herausgefiltert wird, bleibt nur ein kleiner Teil der Daten übrig Daher spielt die Bedeutung von SQL keine Rolle, ob sie geändert wird oder nicht. Nicht groß, da die Filterbedingungen selbst eine sehr effiziente Filterung erreichen können
2. Beispielsweise haben die Pinselauswahlbedingungen selbst nur geringe Auswirkungen (die Menge). Die Daten sind nach dem Filtern immer noch riesig. Diese Situation ist tatsächlich wieder die Situation, in der es keine Filterbedingungen gibt, und es hängt auch davon ab, wie sortiert, weitergeleitet oder umgekehrt wird usw.
3. Zum Beispiel die Filterbedingungen selbst haben kaum Auswirkungen (die Datenmenge ist nach dem Filtern immer noch riesig). ganz anders)
4. Wenn die Abfrage selbst relativ komplex ist, ist es schwierig zu sagen, dass eine bestimmte Methode effiziente Zwecke erreichen kann
Hier werden wir nicht die Situation analysieren, in der Filterbedingungen einzeln zur Abfrage hinzugefügt werden. Sicher ist jedoch, dass es ohne das tatsächliche Szenario definitiv keine solide Lösung gibt.
Zusammenfassung
Je weiter hinten, desto langsamer ist die Situation. Tatsächlich gilt für den B-Tree-Index die Vorder- und Rückseite Sind ein logisch relatives Konzept, der Leistungsunterschied basiert auf der B-Tree-Indexstruktur und der Scanmethode.Wenn Filterbedingungen hinzugefügt werden, wird die Situation komplizierter. Das Prinzip dieses Problems ist in SQL Server dasselbe Ja, es wurde ursprünglich in SQL Server getestet, daher werde ich es hier nicht wiederholen.
In der aktuellen Situation sind die Sortierspalte, die Abfragebedingungen und die Datenverteilung nicht unbedingt sicher, sodass es schwierig ist, eine bestimmte Methode zur „Optimierung“ zu verwenden. Andernfalls hat dies überflüssige Nebenwirkungen.
Daher müssen Sie bei der Paging-Optimierung eine Analyse basierend auf bestimmten Szenarien durchführen. Es gibt nicht unbedingt nur eine Methode, die vom tatsächlichen Szenario abweicht.
Nur wenn wir die Besonderheiten dieses Problems verstehen, können wir es problemlos lösen.
Daher muss meine persönliche Schlussfolgerung zur Datenoptimierung auf einer spezifischen Analyse spezifischer Probleme basieren. Es ist sehr tabu, eine Reihe von Regeln (Regeln 1, 2, 3, 4, 5) zusammenzufassen, damit andere sie „anwenden“ können „Da ich auch sehr auf Essen stehe, geschweige denn auf ein paar Dogmen.
Das obige ist der detaillierte Inhalt vonTestfall zur MySQL-Paging-Optimierung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!