
Heim >Backend-Entwicklung >Python-Tutorial >Einführung in das Scrapy-Crawler-Framework
Einführung in das Scrapy-Crawler-Framework

- PHP中文网Original
- 2017-06-20 17:19:392438Durchsuche
Einführung in das Scrapy-Crawler-Framework
Installationsmethode pip install scrapy kann installiert werden. Ich verwende den Anaconda-Befehl, um Scrapy mit Conda zu installieren.

1 Engine erhält die Crawl-Anfrage (Request) von Spider<br>2Engine wird die Crawling-Anfrage wird zur Planung an den Scheduler weitergeleitet
3 Engine erhält die nächste Crawling-Anfrage vom Scheduler<br>4 Engine sendet die Crawling-Anfrage über die Middleware an den Downloader<br>5 Crawling nach der Webseite , der Downloader erstellt eine Antwort und sendet sie über die Middleware an die Engine.<br>Die Engine sendet die empfangene Antwort über die Middleware an den Spider zur Verarbeitung. Die Engine leitet die Crawling-Anfrage zur Planung an den Scheduler weiter 🎜> 7 Nachdem Spider die Antwort verarbeitet hat, generiert es ein gescraptes Element
und neue Crawling-Anfragen (Requests) an die Engine8 Engine sendet das gescrapte Element an die Item-Pipeline (Framework-Exit) <br> 9 Engine sendet die Crawling-Anfrage wird an den Scheduler gesendet<br><br>Engine steuert den Datenfluss jedes Moduls und erhält kontinuierlich Crawling-Anfragen vom Scheduler
bis die Anfrage leer istFrame-Eintrag: Spiders erste Crawling-Anfrage<br>Frame-Export : Item Pipeline<br><br>
Engine Nein Benutzeränderung erforderlich
<br>Downloader<br>Webseiten entsprechend den Anforderungen herunterladen<br>Keine Benutzeränderung erforderlich
Planer<br>Planung und Verwaltung aller Crawling-Anfragen<br>Keine Benutzeränderung erforderlich
Downloader-Middleware<br>Zweck: Implementierung einer benutzerkonfigurierbaren Steuerung zwischen Engine, Scheduler und Downloader<br>
Funktion: Anforderungen oder Antworten ändern, verwerfen, hinzufügenBenutzer können Konfigurationscode schreiben <br>Spider<br><br>(1) Die vom Downloader zurückgegebene Antwort analysieren <br>(2) Gekratztes Element generieren
(3) Zusätzliche Crawling-Anfragen generieren (Anfrage)Benutzer müssen Konfigurationscode schreiben <br>Item-Pipelines<br><br>(1) Verarbeiten Sie die von Spider generierten gecrawlten Elemente in eine Pipeline-Art <br>( 2) Sie besteht aus einer Reihe von Operationssequenzen, ähnlich einer Pipeline. Jede Operation
ist ein Item-Pipeline-Typ(3) Zu den möglichen Operationen gehören: Bereinigen, Überprüfen und Duplikatsprüfung Die HTML-Daten von in den gecrawlten Elementen. Das Speichern von Daten in der Datenbank erfordert, dass der Benutzer Konfigurationscode schreibt <br> <br> Nachdem wir die Grundkonzepte verstanden haben, beginnen wir mit dem Schreiben des ersten Scrapy-Crawlers. <br><br>Erstellen Sie zunächst ein neues Crawler-Projekt scrapy startproject xxx (Projektname) <br><br>
Dieser Crawler crawlt einfach den Titel und den Autor einer Roman-Website. Wir haben nun das Crawler-Projektbuch erstellt und nun bearbeiten wir seine Konfiguration
 Surface-Operation zu verwenden. Schreiben Sie den folgenden Code in die Datei.
Surface-Operation zu verwenden. Schreiben Sie den folgenden Code in die Datei.
Die ersten beiden Parameter sind festgelegt, der dritte Parameter ist der Name Ihrer Spinne
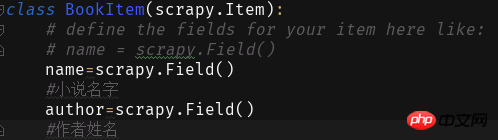
Als nächstes füllen wir die Felder in Elementen aus:
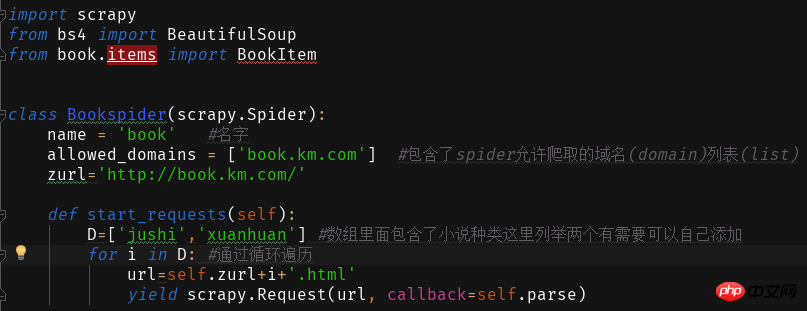
Dann erstellen wir das Crawler-Hauptprogrammbuch in Spider Py
Die Website, die wir crawlen möchten, ist
Wenn Sie auf die verschiedenen Romantypen auf der Website klicken, werden Sie feststellen, dass die Website-Adresse +Romantyp pinyin.html
Dadurch schreiben und lesen wir den Inhalt der Webseite
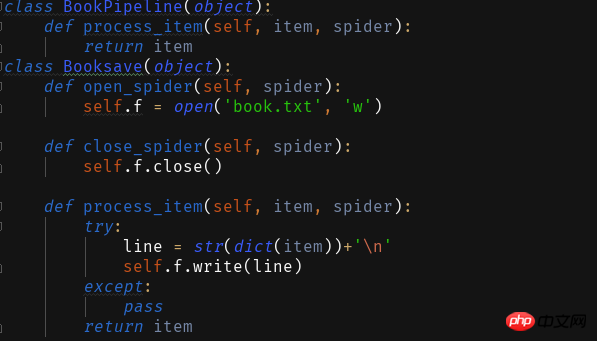
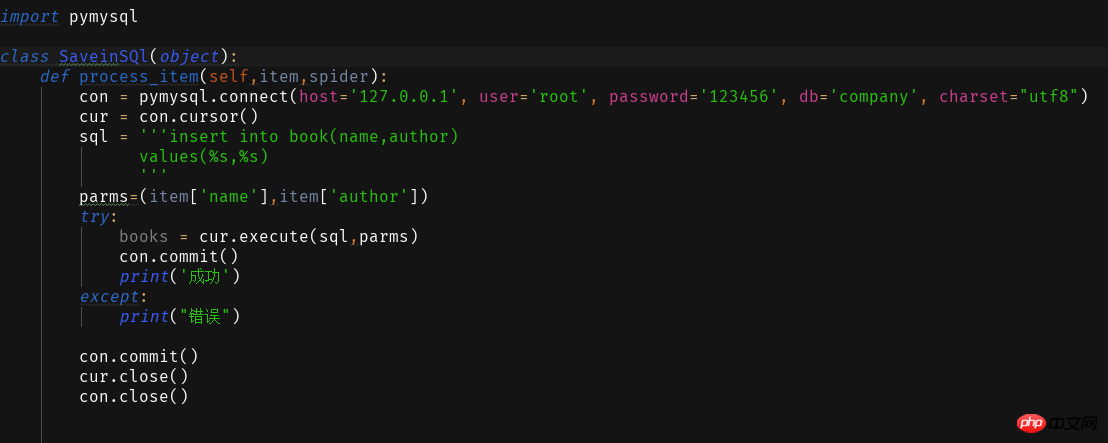
<span style="color: #000000">ITEM_PIPELINES = { 'book.pipelines.xxx': 300,}<br>xxx为存储方法的类名,想用什么方法存储就改成那个名字就好运行结果没什么看头就略了<br>第一个爬虫框架就这样啦期末忙没时间继续完善这个爬虫之后有时间将这个爬虫完善成把小说内容等一起爬下来的程序再来分享一波。<br>附一个book的完整代码:<br></span>
import scrapyfrom bs4 import BeautifulSoupfrom book.items import BookItemclass Bookspider(scrapy.Spider):
name = 'book' #名字
allowed_domains = ['book.km.com'] #包含了spider允许爬取的域名(domain)列表(list)
zurl=''def start_requests(self):
D=['jushi','xuanhuan'] #数组里面包含了小说种类这里列举两个有需要可以自己添加for i in D: #通过循环遍历
url=self.zurl+i+'.html'yield scrapy.Request(url, callback=self.parse)
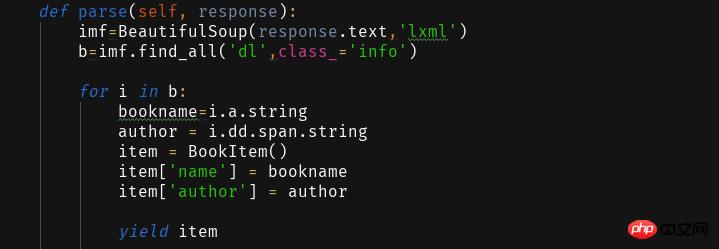
def parse(self, response):
imf=BeautifulSoup(response.text,'lxml')
b=imf.find_all('dl',class_='info')for i in b:
bookname=i.a.stringauthor = i.dd.span.stringitem = BookItem()
item['name'] = bookname
item['author'] = authoryield item<br>
Das obige ist der detaillierte Inhalt vonEinführung in das Scrapy-Crawler-Framework. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!