
Heim >Backend-Entwicklung >Python-Tutorial >Beispiel für Python-Crawler-Audiodaten
Beispiel für Python-Crawler-Audiodaten

- PHP中文网Original
- 2017-06-21 17:16:242331Durchsuche
1: Vorwort
Dieses Mal haben wir die Informationen zu jedem Kanal aller Radiosender unter der beliebten Spalte „Himalaya“ und verschiedene Informationen zu den einzelnen Audiodaten im Kanal gecrawlt und dann die gecrawlten Daten gespeichert mongodb zur späteren Verwendung. Diesmal beträgt die Datenmenge rund 700.000. Zu den Audiodaten gehören Audio-Download-Adresse, Kanalinformationen, Einleitung usw., davon gibt es viele.
Ich hatte gestern mein erstes Vorstellungsgespräch. Ich wollte in den Sommerferien meines zweiten Studienjahres ein Praktikum machen, also kam ich, um Himalaya zu analysieren . Die Audiodaten kriechen nach unten. Derzeit warte ich noch auf drei Interviews oder darauf, über die endgültigen Interviewnachrichten informiert zu werden. (Da ich eine gewisse Anerkennung bekommen kann, bin ich unabhängig von Erfolg oder Misserfolg sehr glücklich)
2: Laufumgebung
-
IDE: Pycharm 2017
Python3.6
Pymongo 3.4.0
Anfragen 2.14.2
-
lxml 3.7.2
BeautifulSoup 4.5.3
Drei: Beispielanalyse
1. Rufen Sie zunächst die Hauptseite dieses Crawls auf. Auf jeder Seite sind 12 Kanäle zu sehen. Unter jedem Kanal gibt es viele Seitenumbrüche. Crawling-Plan: Durchlaufen Sie 84 Seiten, analysieren Sie jede Seite, erfassen Sie den Namen, den Bildlink und den Kanallink jedes Kanals und speichern Sie sie in Mongodb.
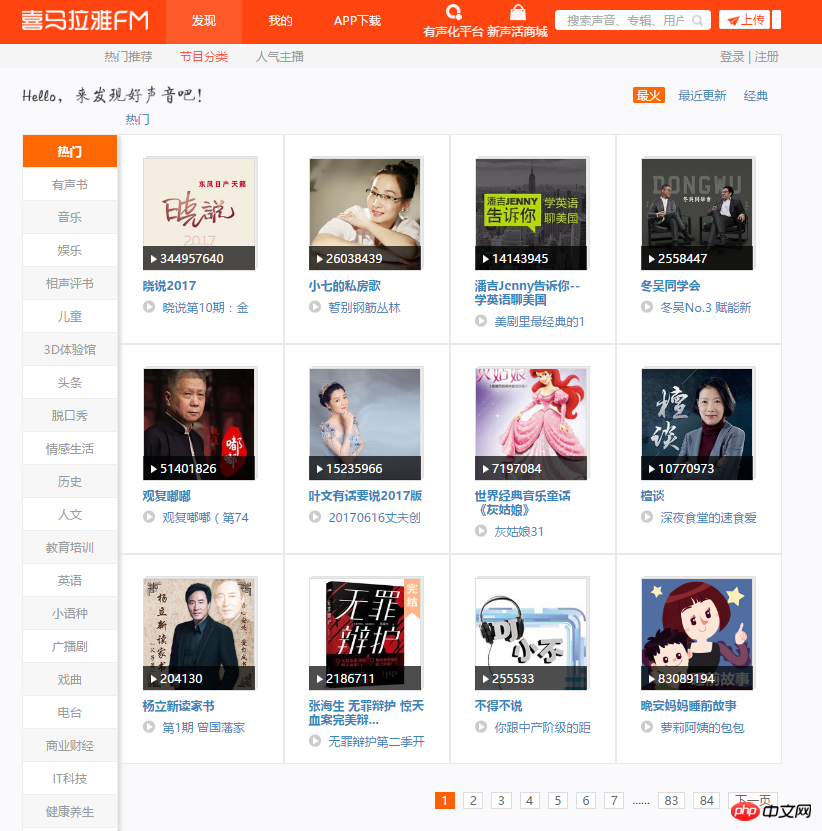
2. Öffnen Sie den Entwicklermodus, analysieren Sie die Seite und ermitteln Sie schnell den Speicherort der gewünschten Daten. Mit dem folgenden Code werden die Informationen aller gängigen Kanäle erfasst und in mongodb gespeichert.
start_urls = ['http://www.ximalaya.com/dq/all/{}'.format(num) for num in range(1, 85)]for start_url in start_urls:html = requests.get(start_url, headers=headers1).text
soup = BeautifulSoup(html, 'lxml')for item in soup.find_all(class_="albumfaceOutter"):content = {'href': item.a['href'],'title': item.img['alt'],'img_url': item.img['src']
}
print(content)
3 Im Folgenden wird damit begonnen, alle Audiodaten in jedem Kanal zu erhalten, die über erhalten wurden Die Analyseseite Hier ist der Link zum US-Kanal. Beispielsweise analysieren wir die Seitenstruktur nach Eingabe dieses Links. Es ist ersichtlich, dass jedes Audio eine bestimmte ID hat, die aus den Attributen in einem Div abgerufen werden kann. Verwenden Sie split() und int(), um in einzelne IDs zu konvertieren.
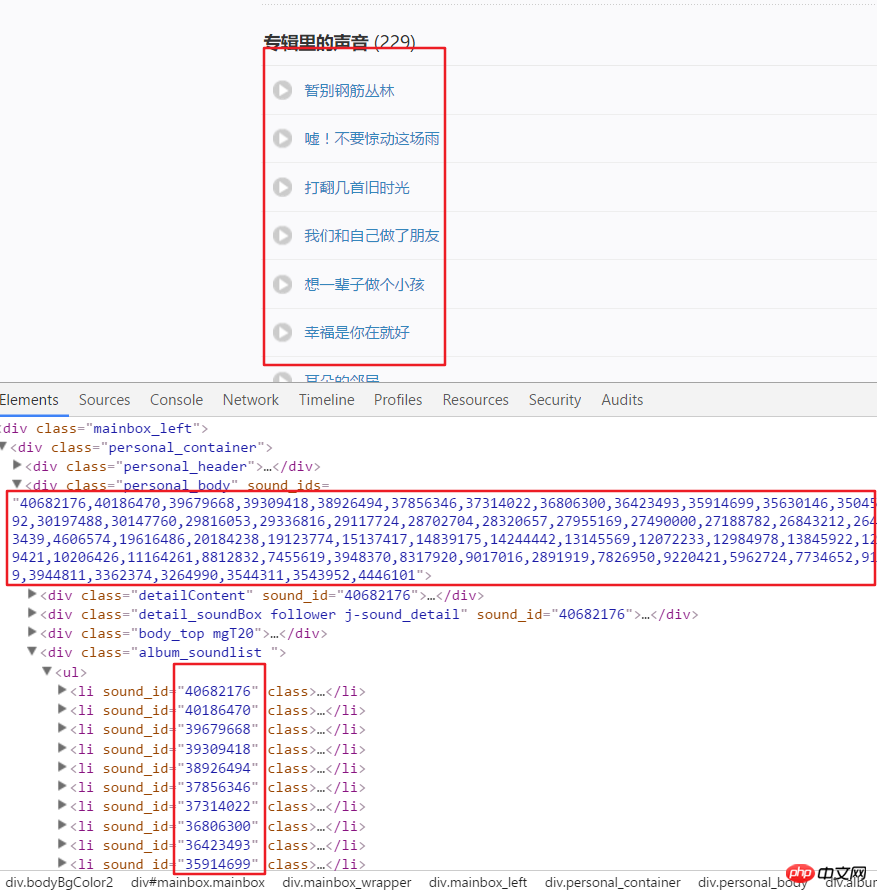
4. Klicken Sie dann auf einen Audiolink, wechseln Sie in den Entwicklermodus, aktualisieren Sie die Seite und klicken Sie auf XHR, dann klicken Sie auf a json Der Link, um dies anzuzeigen, enthält alle Details dieses Audios.
html = requests.get(url, headers=headers2).text
numlist = etree.HTML(html).xpath('//div[@class="personal_body"]/@sound_ids')[0].split(',')for i in numlist:
murl = 'http://www.ximalaya.com/tracks/{}.json'.format(i)html = requests.get(murl, headers=headers1).text
dic = json.loads(html)
5. Das Obige analysiert nur alle Audioinformationen auf der Hauptseite eines Kanals. aber in Wirklichkeit hat der Audiolink auf dem oberen Kanal viele Seitenumbrüche.
html = requests.get(url, headers=headers2).text
ifanother = etree.HTML(html).xpath('//div[@class="pagingBar_wrapper"]/a[last()-1]/@data-page')if len(ifanother):num = ifanother[0]
print('本频道资源存在' + num + '个页面')for n in range(1, int(num)):
print('开始解析{}个中的第{}个页面'.format(num, n))
url2 = url + '?page={}'.format(n)# 之后就接解析音频页函数就行,后面有完整代码说明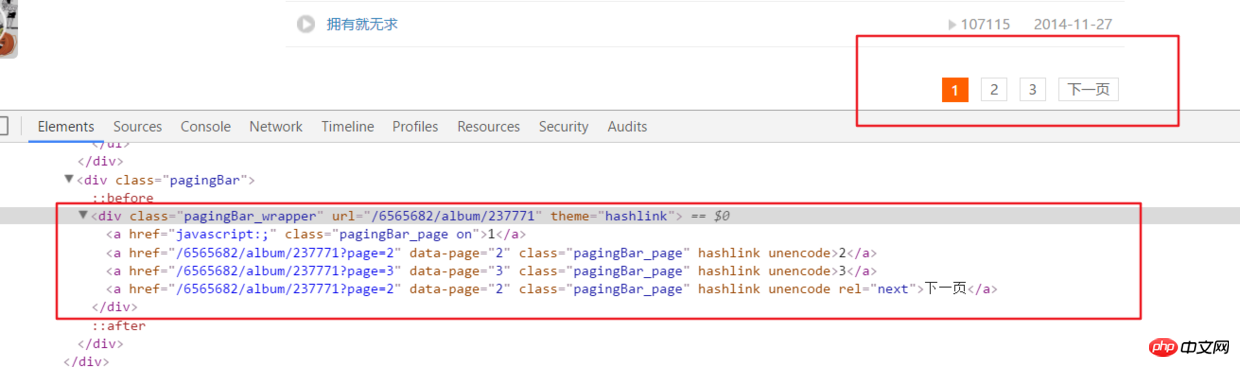
6. Alle Codes
Vollständige Codeadresse github.com/rieuse/learnPython
__author__ = '布咯咯_rieuse'import jsonimport randomimport timeimport pymongoimport requestsfrom bs4 import BeautifulSoupfrom lxml import etree
clients = pymongo.MongoClient('localhost')
db = clients["XiMaLaYa"]
col1 = db["album"]
col2 = db["detaile"]
UA_LIST = [] # 很多User-Agent用来随机使用可以防ban,显示不方便不贴出来了
headers1 = {} # 访问网页的headers,这里显示不方便我就不贴出来了
headers2 = {} # 访问网页的headers这里显示不方便我就不贴出来了def get_url():
start_urls = ['http://www.ximalaya.com/dq/all/{}'.format(num) for num in range(1, 85)]for start_url in start_urls:
html = requests.get(start_url, headers=headers1).text
soup = BeautifulSoup(html, 'lxml')for item in soup.find_all(class_="albumfaceOutter"):
content = {'href': item.a['href'],'title': item.img['alt'],'img_url': item.img['src']
}
col1.insert(content)
print('写入一个频道' + item.a['href'])
print(content)
another(item.a['href'])
time.sleep(1)def another(url):
html = requests.get(url, headers=headers2).text
ifanother = etree.HTML(html).xpath('//div[@class="pagingBar_wrapper"]/a[last()-1]/@data-page')if len(ifanother):
num = ifanother[0]
print('本频道资源存在' + num + '个页面')for n in range(1, int(num)):
print('开始解析{}个中的第{}个页面'.format(num, n))
url2 = url + '?page={}'.format(n)
get_m4a(url2)
get_m4a(url)def get_m4a(url):
time.sleep(1)
html = requests.get(url, headers=headers2).text
numlist = etree.HTML(html).xpath('//div[@class="personal_body"]/@sound_ids')[0].split(',')for i in numlist:
murl = 'http://www.ximalaya.com/tracks/{}.json'.format(i)
html = requests.get(murl, headers=headers1).text
dic = json.loads(html)
col2.insert(dic)
print(murl + '中的数据已被成功插入mongodb')if __name__ == '__main__':
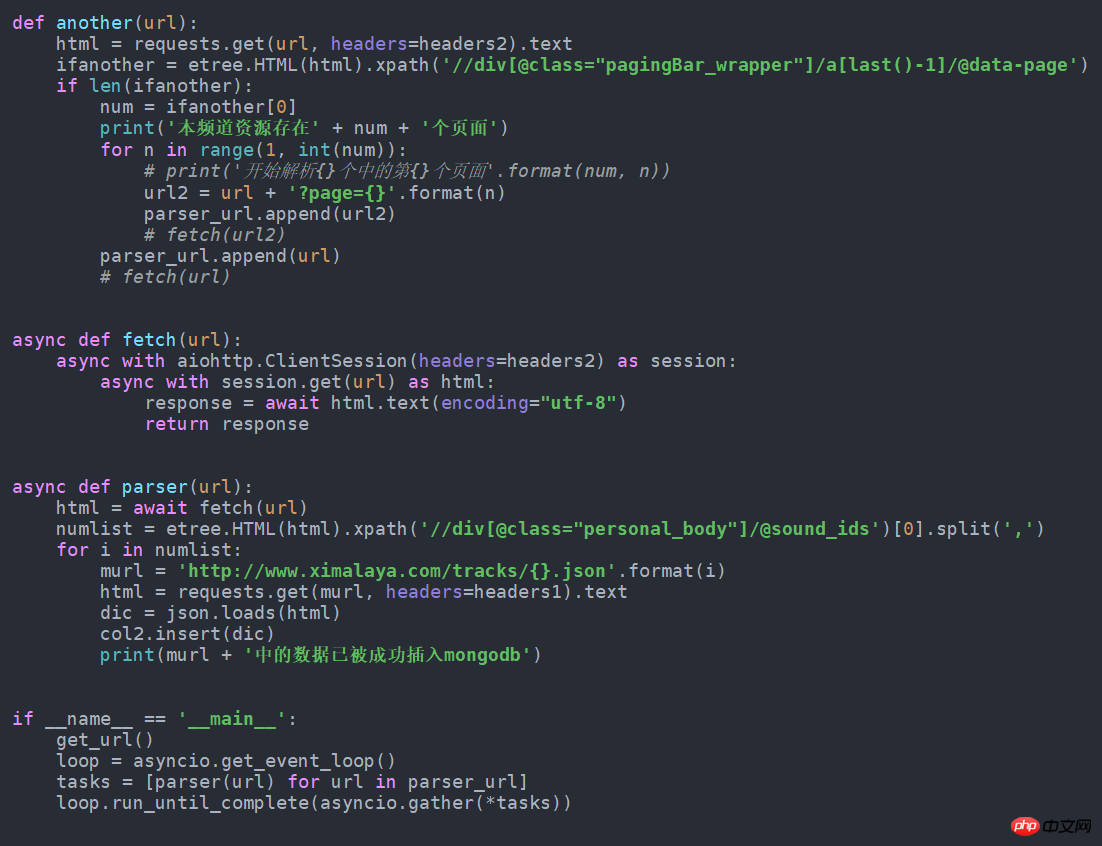
get_url()7. Wenn es in die asynchrone Form geändert wird, wird es schneller. Ändern Sie es einfach wie folgt. Ich habe versucht, fast 100 Daten mehr pro Minute als normal zu erhalten. Dieser Quellcode ist auch in Github.
Das obige ist der detaillierte Inhalt vonBeispiel für Python-Crawler-Audiodaten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!