
Heim >Java >javaLernprogramm >Beispiel-Tutorial der pseudoverteilten Bereitstellungsinstallation von Hadoop 2.6.0
Beispiel-Tutorial der pseudoverteilten Bereitstellungsinstallation von Hadoop 2.6.0

- 零下一度Original
- 2017-06-25 10:33:431734Durchsuche
Ich habe zuvor einen Blog-Beitrag über die Konfiguration und Installation von Hadoop gelesen (Adresse:). Es kann jedoch korrekt installiert und ausgeführt werden, aber wenn Sie Jobtracker auf der Webseite überwachen, geben Sie localhost:8088 ein (beachten Sie hier, dass die Jobtracker-Schnittstelle von hadoop2. 0 und spätere Versionen beginnen bei 50030 (Es wurde 8088) und können nicht aufgerufen werden. Nachdem ich einige Informationen gelesen hatte, stellte ich fest, dass die beiden Konfigurationsdateien „mapred-site.xml“ und „garn-site.xml“ nicht konfiguriert waren.
Die erste ist die Datei „mapred-site.xml“. Diese Konfigurationsdatei existiert ursprünglich nicht, aber es gibt eine Datei „mapred-site.xml.template“. Die Methode besteht darin, die Datei „mapred-site.xml“ zu kopieren. Erstellen Sie eine Vorlagedatei, nennen Sie sie „mapred-site.xml“ und konfigurieren Sie sie dann.
Befehl:
vim mapred-site.xml
Fügen Sie den Inhalt wie unten gezeigt hinzu:

Dann Garn - site.xml-Dateikonfiguration
Befehl:
vim Yarn-site.xml
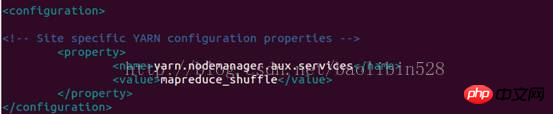
Andere müssen nicht zurückgesetzt werden, und Du bist fertig!
Das obige ist der detaillierte Inhalt vonBeispiel-Tutorial der pseudoverteilten Bereitstellungsinstallation von Hadoop 2.6.0. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!