
Heim >Java >javaLernprogramm >JAVA WEB-Notizen – Chinesische verstümmelte Zeichen
JAVA WEB-Notizen – Chinesische verstümmelte Zeichen
- 巴扎黑Original
- 2017-06-26 11:11:011612Durchsuche
JAVA WEB-Problemanalyse mit verstümmeltem Code
Ursache für verstümmelten Code
Im Prozess der Java-Webentwicklung stoßen wir häufig auf das Problem von verstümmeltem Code. Der Grund für verstümmelten Code kann als Zeichenkodierung zusammengefasst werden. Entspricht nicht der Dekodierungsmethode.
Da der Grund für verstümmelte Zeichen darin liegt, dass die Methoden zur Zeichenkodierung und -dekodierung nicht übereinstimmen, warum müssen wir die Zeichen dann kodieren? Ist es in Ordnung, sie nicht zu kodieren? Dies liegt daran, dass die Grundeinheit zum Speichern von Daten in einem Computer 1 Byte, also 8 Bit, beträgt. Die maximale Anzahl an Zeichen, die er ausdrücken kann, beträgt also 28=256, und in unserer realen Gesellschaft gibt es solche weit mehr Zeichen (chinesische Zeichen, englische Zeichen, andere Zeichen usw.) als diese Anzahl. Um den Konflikt zwischen Zeichen und Bytes zu lösen, müssen Zeichen codiert werden, bevor sie im Computer gespeichert werden können.
Kodierung und Dekodierung
Übliche Kodierungsmethoden in Computern sind ASCII, ISO-8859-1, GB2312, UTF-16 und UTF-8.
Der ASCII-Code wird durch die unteren 7 Bits eines Bytes dargestellt, daher beträgt die maximale Anzahl darstellbarer Zeichen 27=128 . ISO-8859-1 ist eine auf ASCII-Code basierende Erweiterung der ISO-Organisation. Sie ist mit ASCII-Code kompatibel und deckt die meisten westeuropäischen Zeichen ab. ISO8859-1 verwendet ein Byte zur Darstellung und kann daher bis zu 256 Zeichen ausdrücken. GB2312 verwendet die Doppelbyte-Kodierung. Der Kodierungsbereich ist A1-F7, wobei A1-A9 der Symbolbereich und B0-F7 der chinesische Zeichenbereich ist, der 6763 chinesische Zeichen enthält. GBK soll die GB2312-Kodierung erweitern und weitere chinesische Schriftzeichen hinzufügen. Es können 21.003 chinesische Schriftzeichen ausgedrückt werden. UTF-16 verwendet eine Kodierungsmethode mit fester Länge. Unabhängig davon, welches Zeichen dargestellt wird, wird es durch 2 Bytes dargestellt. Dies ist auch das Speicherformat von Zeichen im JAVA-Speicher. Im Gegensatz zu UTF-16 verwendet UTF-8 eine Codierungsmethode mit variabler Länge und verschiedene Zeichentypen können aus 1–6 Bytes bestehen.
Werfen wir einen Blick auf die Kodierung verschiedener Kodierungsmethoden im Computer mithilfe der Zeichenfolge „Hyuuga Hinata“, wie unten gezeigt.

Analyse und Lösung von verstümmeltem Code
Für das Problem mit verstümmeltem Code in JAVA WEB: Wir unterteilen die durch Anfragen verursachten verstümmelten Zeichen und die durch Antworten verursachten verstümmelten Zeichen. Für verschiedene verstümmelte Zeichen müssen wir die Ursachen der verstümmelten Zeichen analysieren, dh was ist die Zeichencodierungsmethode und was ist die Dekodierungsmethode .
Für den durch die Anfrage verursachten verstümmelten Code müssen wir die HTTP-Anfrage analysieren und ihre Codierungsmethode überprüfen. Da HTTP-Anfragen in Get-Anfragen und Post-Anfragen unterteilt sind, werden wir sie besprechen separat als nächstes.
Bei der Get-Anfrage handelt es sich um die Standardanforderungsmethode des Browsers und die Übermittlungsmethode, wenn das Formular an „Get“ gesendet wird. Wir überprüfen den spezifischen Inhalt über den Firefox-Browser wie folgt:
Die Adressleiste lautet: 
Der Anforderungsinhalt lautet:

Aus der obigen Anfrage können wir ersehen, dass die Abfragezeichenfolge in der GET-Anfrage in der Anfragezeile gespeichert und an die gesendet wird WEB-Server: Anhand der „Hyuga Hinata“-Kodierung können wir erkennen, dass die vom Browser für diese Zeichenfolge verwendete Kodierungsmethode „UTF-8“ ist.
Wenn wir uns den Servercode ansehen, können wir verstümmelte Zeichen sehen (wie unten gezeigt). Dies liegt daran, dass der Server die Daten nach dem Empfang der Zeichenfolgenkodierung standardmäßig mit ISO-8859-1 dekodiert . Daher sind die Kodierungs- und Dekodierungsmethoden nicht einheitlich.

Die Lösung lautet wie folgt:
Holen Sie sich zuerst die Zeichenfolge user Bevor Sie die Codierung dekodieren, geben Sie dann die Codierungsmethode der Zeichenfolge an, wie unten gezeigt:

Das Lösungsdiagramm lautet wie folgt folgt:

Im Prozess der Java-Webentwicklung übergeben wir Parameter in Hyperlinks und stoßen häufig auf chinesische Situationen. In diesem Fall müssen wir Chinesisch kodieren, wir können es auf UTF-8 einstellen und das Dekodierungsschema ist das gleiche wie oben.
<a href="${pageContext.request.contextPath}/Test?user=<%=URLEncoder.encode("日向雏田", "UTF-8")%>">点击</a>Bei Post-Anfragen handelt es sich um die Übermittlungsmethode, wenn das Formular auf „Posten“ eingestellt ist " . Wir verwenden Firefox, um den spezifischen Inhalt wie folgt zu überprüfen:
Die Adressleiste und ihre Seite sind:

Der Inhalt der Post-Anfrage lautet:
Fügen Sie den Anforderungsinhalt direkt in den Anforderungstext ein und senden Sie ihn an den Webserver sowie die Codierungsmethode ist „utf-8“. 
In diesem Antwort-Servlet lautet der Hauptteil der doPost-Methode wie folgt:
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
String user=request.getParameter("user");
System.out.println(user);//输出为æ¥åéç°
}Der Grund für den verstümmelten Code hier ist immer noch, dass der Webserver beim Code getParameter („Benutzer“) das Standarddekodierungsschema „ISO-8859-1“ verwendet Wenn Sie mit dem Decodierungsschema nicht einverstanden sind, kann die Lösung darin bestehen, die verstümmelte Get-Request-Lösung zu verwenden. Es gibt jedoch eine einfachere Lösung, bei der das Codierungs-/Decodierungsschema des Methodenkörpers direkt angegeben wird als „utf-8“. Der Plan ist wie folgt.
Die obige Analyse hat den verstümmelten Code verursacht durch die Anfrage abgeschlossen.
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
response.setCharacterEncoding("utf-8"); //设置请求体的编码/解码方案为UTF-8 但是请求行的编码解码方案不会受影响
String user=request.getParameter("user");
System.out.println(user); //输出为日向雏田
}In dem durch die Auswirkung verursachten verstümmelten Code schreibt der Webserver den Antwortinhalt in den Antworttext und gibt ihn ohne Einbeziehung der Statuszeile an den Client zurück. Wenn beispielsweise „HelloWorld“ an den Browser ausgegeben wird, ist die Antwort wie in der folgenden Abbildung dargestellt.
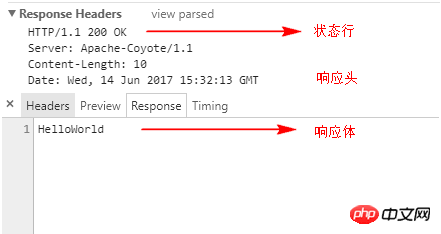 Wir müssen vier Methoden für den durch die Antwort verursachten verstümmelten Code einbeziehen, wie folgt :
Wir müssen vier Methoden für den durch die Antwort verursachten verstümmelten Code einbeziehen, wie folgt :
response.setHeader("Content-Type", "text/html;cahrset=utf-8");//设置发送到客户端的响应的内容类型和响应内容的编码类型(响应体的编码类型)
response.setCharacterEncoding("utf-8");//设置响应体的编码类型
response.getWriter(); //获取响应的输出字符流
response.getOutputStream(); //获取响应的输出字节流Für Festlegen der Antwort Der Kodierungstyp des Körpers, z. B. Response.setHeader("Content-Type", "text/html;cahrset=utf-8"); und Antwort.setCharacterEncoding("utf-8"); Durch diese beiden Methoden usw. Wenn die Codierungsmethode des Antwortkörpers nicht festgelegt ist, ist die Standardeinstellung ISO-8859-1, und die Codierungsmethode des Zeichensatzes für den Antwortkörper wird später die Codierungsmethode der vorherigen Einstellung wiederholen. Beide Methoden sind vor der getWriter-Methode gültig, und die Methode zum Festlegen der Codierung in der getWriter-Methode ist ungültig. Diese beiden Methoden unterscheiden sich jedoch etwas, dh die Methode setHeader("Content-Type", "text/html;cahrset=utf-8") wird automatisch verwendet Die Codierungsmethode des Antworttexts wird vom Browser decodiert, und die setCharacterEncoding()-Methode wird nicht von allen Browsern zum Decodieren verwendet. Die beiden Methoden werden unten getestet und die Ergebnisse sind wie folgt:
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
response.setHeader("Content-Type", "text/html;charset=utf-8");
response.getWriter().write("日向雏田");
}
从上面可以看到第一个方法对于浏览器来说,支持的较好,提倡采用第一种方法设置响应体的字符编码方式。 对于获取响应字符输出流的方法,如果在此之前没有设置响应体的编码方式,那么默认为null,即ISO-8859-1方式进行编码。而且后面设置的编码方式会覆盖前面设置的编码方式。在getWriter()方法之后设置的编码无效。 对于获取响应输出字节流,我们在输出字符串时,我们需要设置字符串的编码方式如果没有那么默认ISO-8859-1。 对于前面2个输出流,由于只有一个输出缓存,所以这两个方法互斥。 以上,为了保证响应无乱码,需要保证字符编码和解码方法的统一,方案如下: 此外在Java web开发过程中,我们还会遇到当进行文件下载时,中文文件名导致的问题,如下图所示: 采用火狐浏览器进行测试,查看页面效果,及其响应结果如下: 经过查看响应头分析,下载文件名存放在响应头中,且对于中文文字没有采用UTF-8、UTF-16、GBK等等能识别中文的编码,那么对于中文文件名导致采用哪种编码方式呢?查看REF 7578得知,在此处采用ASCII编码,但是REF规定,如果不可避免的要使用非ASCII码的字符,程序员应该均匀的使用UTF-8,来最小化交互操作的问题。 所以,解决方案就是把文件名编码成UTF-8,传递给响应头,浏览器(部分)默认对该文件名进行UTF-8解码处理。 效果如下:其中火狐浏览器并没有对其解码
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
// 方案1
// response.setHeader("Content-Type", "text/html;charset=utf-8");
// response.getWriter().write("日向雏田");
// 方案2
// response.getOutputStream().write("日向雏田".getBytes("UTF-8"));
// 方案1,2互斥
} public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
String realPath=this.getServletContext().getRealPath("/src/日向雏田.jpg");
String fileName=realPath.substring(realPath.lastIndexOf('\\')+1);
response.setHeader("content-disposition", "attachment;filename="+fileName);
InputStream is=new FileInputStream(new File(realPath));
OutputStream os=response.getOutputStream();
byte[] buff=new byte[1024];
int len=0;
while((len=is.read(buff))>0){
os.write(buff, 0, len);
}
os.close();
is.close();
}

public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
String realPath=this.getServletContext().getRealPath("/src/日向雏田.jpg");
String fileName=realPath.substring(realPath.lastIndexOf('\\')+1);
String utf_8Name=URLEncoder.encode(fileName,"utf-8");//解决方案
response.setHeader("content-disposition", "attachment;filename="+utf_8Name);
InputStream is=new FileInputStream(new File(realPath));
OutputStream os=response.getOutputStream();
byte[] buff=new byte[1024];
int len=0;
while((len=is.read(buff))>0){
os.write(buff, 0, len);
}
os.close();
is.close();
}
Das obige ist der detaillierte Inhalt vonJAVA WEB-Notizen – Chinesische verstümmelte Zeichen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!