
Heim >Java >javaLernprogramm >Einführung in den Offline-Datenanalyseprozess
Einführung in den Offline-Datenanalyseprozess
- 巴扎黑Original
- 2017-06-26 11:33:451856Durchsuche
3. OfflineDatenanalyseProzesseinführung
Hinweis: Dieser Link konzentriert sich hauptsächlich auf das Erleben des Makrokonzepts und des Verarbeitungsablaufs des Datenanalysesystems sowie auf das anfängliche Verständnis der Anwendungsverknüpfungen von hadoop und anderen Frameworks. Achten Sie nicht zu sehr darauf. Codedetails
Ein weit verbreitetes Datenanalysesystem: "WebLog Data Mining"
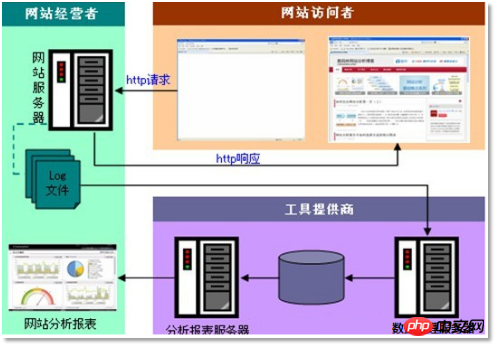
3.1 Anforderungsanalyse
3.1.1 Fallname
"Website oder APP Clickstream Log Data Mining System".
3.1.2 Fallanforderungsbeschreibung
“Web „Clickstream-Protokoll“ enthält sehr wichtige Informationen für den Website-Betrieb. Durch die Protokollanalyse können wir die Anzahl der Besuche auf der Website ermitteln, welche Webseite die meisten Besucher hat, welche Webseite am wertvollsten ist, die Werbekonvertierungsrate, Informationen zur Besucherquelle usw Informationen zum Besucherterminal warten.
3.1.3 Datenquelle
Die Daten werden in diesem Fall hauptsächlich bereitgestellt von Klickverhaltensaufzeichnung des Benutzers
So erhalten Sie: Betten Sie ein js-Programm auf der Seite für die Dinge vorab ein Sie möchten auf der Seite das Label-Bindungsereignis überwachen. Solange der Benutzer auf das Label klickt oder zu ihm wechselt, kann es die Ajax-Anfrage an den Hintergrund auslösen Servlet Programm, verwenden Sie log4j zeichnet die Ereignisinformationen auf dem Web Server auf ( nginx, Tomcat usw.).
Form:
|
3.2 Datenverarbeitungsablauf
3.2.1 Flussdiagrammanalyse
Dieser Fall ist dem typischen BI-System sehr ähnlich, und der Gesamtprozess ist wie folgt:

Da jedoch die Prämisse dieses Falles
ist verarbeitet riesige Datenmengen. Daher unterscheiden sich die in den einzelnen Prozessgliedern verwendeten Technologien vollständig von herkömmlichen BI. Nachfolgende Kurse werden sie einzeln erklären: 1)
Datenerfassung: individuell entwickeltes Erfassungsprogramm, oder verwenden Sie das Open-Source-FrameworkFLUME2)
Datenvorverarbeitung: individuell entwickeltesmapreduceProgramm läuft auf HadoopCluster3)
Data Warehouse-Technologie:Hivehadoop 🎜>4) Datenexport:
sqoopDatenimport- und -exporttool basierend auf hadoop 5) Datenvisualisierung: Kundenspezifische Entwicklung von
Web-Programmen oder Einsatz von Produkten wie Wasserkocher 6) des gesamten Prozesses Prozessplanung:
HadoopoozieTools oder andere ähnliche Open-Source-Produkte im Ökosystem
3.2.2
Projekttechnisches Architekturdiagramm 
3.2.3
Projektbezogene Screenshots (Schätzen Sie es einfach wahrnehmungsmäßig)a) MapreudceProgramm läuft

Daten in
Hive abfragen

Statistische Ergebnisse in
MySQL importieren| ./sqoop export --connect jdbc:mysql://localhost:3306/weblogdb --username root --password root --table t_display_xx --export- dir /user/hive/warehouse/uv /dt=2014-08-03 |
./sqoop export --connect jdbc:mysql://localhost:3306/weblogdb --username root --password root --table t_display_xx --export-dir /user/hive/warehouse/uv/dt=2014-08-03 |
3.3
Endgültige Wirkung des Projekts
Nach vollständigen Daten Im Verarbeitungsprozess werden regelmäßig verschiedene Statistiken als Indikatorberichte ausgegeben. In der Produktionspraxis müssen diese Berichtsdaten letztendlich in visueller Form angezeigt werden. In diesem Fall wird dasWeb-Programm verwendet, um die Datenvisualisierung zu erreichen 🎜> Wirkung Wie unten gezeigt:

Das obige ist der detaillierte Inhalt vonEinführung in den Offline-Datenanalyseprozess. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!