
Heim >Backend-Entwicklung >Python-Tutorial >Detaillierte Erklärung der Zeichenkodierung in Python
Detaillierte Erklärung der Zeichenkodierung in Python

- 零下一度Original
- 2017-06-16 10:49:551369Durchsuche
Der folgende Editor bringt Ihnen einen Artikel über die grundlegende Zeichenkodierung von Python. Der Herausgeber findet es ziemlich gut, deshalb werde ich es jetzt mit Ihnen teilen und es allen als Referenz geben. Folgen wir dem Herausgeber und werfen wir einen Blick darauf.
Vorwort
Bei der Zeichencodierung kann es sehr leicht zu Fehlern kommen, wir muss ein paar Dinge beachten. In einem Satz:
1. Welche Kodierung zum Speichern verwendet wird, welche Kodierung zum Öffnen verwendet werden soll
2 Die Ausführung des Programms besteht darin, die Datei zunächst in den Speicher einzulesen
3 Unicode ist die übergeordnete Kodierung und kann nur in andere Kodierungsformate kodiert und dekodiert werden
utf-8 Sub-8-Kodierung und kann nur in Unicode dekodiert werden
1 Was ist Zeichenkodierung
Wir wissen, dass Computer nur binäre, und die Codes, die wir normalerweise schreiben, müssen in Binärdateien umgewandelt werden, damit sie vom Computer erkannt werden. Wie konvertieren wir also die von uns geschriebenen Zeichen in Binärzeichen? Dieser Prozess verwendet tatsächlich einen Standard, um sicherzustellen, dass die von uns geschriebenen Zeichen eins zu eins bestimmten Zahlen entsprechen.
Zeichen------(Zeichenkodierung)------->Nummer
2. Entwicklungsgeschichte der Zeichenkodierung
1. ASCII-Code
Computer haben ihren Ursprung in den Vereinigten Staaten, und auch die Zeichenkodierung hat ihren Ursprung in den Vereinigten Staaten. Aber die vom amerikanischen Volk verwendeten Zeichen bestehen nur aus 26 Buchstaben und einigen Sonderzeichen. Anders als in China müssen Grundschüler Tausende chinesischer Schriftzeichen kennen. Die Amerikaner verwenden also den ASCII-Code (American Standard Code for Information Interchange) als Zeichenkodierung. Ein Byte entspricht 2 hoch 8 Bit, also 256 verschiedenen Änderungen Es wurden Bits verwendet, also 127 Zeichen, was für die Menschen in den Vereinigten Staaten ausreicht (natürlich aus Kostengründen). Später wurde Latein an der 8. Stelle kompiliert. Zu diesem Zeitpunkt sind die ASCII-Codes vollständig und englischsprachige Länder und lateinische Länder können problemlos spielen.
2.GBK
Obwohl Chinas Technologie derzeit nicht so gut ist wie die des US-Imperiums, sind wir 1980 positiv eingestellt , die State Administration of Standards hat die in Chinesisch -> GBK verwendete Zeichenkodierung herausgegeben, die zwei Bytes zur Darstellung eines chinesischen Zeichens verwendet, sodass es 2 hoch 16 oder 65536 Kombinationen gibt, was für chinesische Zeichen ausreicht.
Gleichzeitig haben auch andere Länder ihre eigenen nationalen Zeichenkodierungsstandards veröffentlicht, wie z. B. Shift_JIS aus Japan, Euc-kr aus Südkorea usw.
3. Unicode
Es wird gesagt, dass es in ihrer Blütezeit Hunderte von Zeichenkodierungen gab und sie sich nicht gegenseitig unterstützten. Es scheint, dass die Menschen in allen Ländern sehr willensstark sind, aber das hier ist der Interoperabilität der Welt nicht förderlich, daher wurde Unicode ins Leben gerufen. Im Jahr 1994 veröffentlichte die Internationale Organisation für Normung Unicode, bekannt als Universal Code, der zwei Bytes zur Darstellung eines Zeichens verwendet und 65.536 Kombinationen aufweist, was bereits die meisten Sprachen der Welt abdecken kann.
4.utf-8
Obwohl Unicode gut ist, gibt es ein Problem, das jetzt in einem Byte ausgedrückt werden kann Wenn Sie zwei Bytes verwenden, wird der Speicherplatz verdoppelt. Dies ist offensichtlich nicht perfekt, daher wurde UTF-8 erstellt, das nur 1 Byte für englische Zeichen und 3 Bytes für chinesische Zeichen verwendet.
5. Alle Unicode-Zeichen bestehen aus zwei Bytes, was einfach und grob ist. Die Umwandlung von Zeichen in Zahlen ist schnell, nimmt aber viel Speicherplatz in Anspruch
utf-8 verwendet unterschiedliche Längen, um unterschiedliche Zeichen darzustellen, was Platz spart, aber die Konvertierungseffizienz ist nicht so schnell wie Unicode
Die im Speicher verwendete Zeichenkodierung ist Unicode und der Speicher Es geht darum, die Geschwindigkeit zu erhöhen, also würde ich lieber ein wenig Platz opfern, aber auch die Geschwindigkeit sicherstellen
Festplatten- und Netzwerkübertragung verwenden UTF-8, da die Festplatten-E/A- oder Netzwerk-E/A-Verzögerung viel größer ist als Die Konvertierungseffizienz von UTF-8 und die Netzwerkübertragung sollten so viel Bandbreite wie möglich einsparen
3. Ausführung des Python-Interpreters
Die erste Stufe: Der Python-Interpreter wird gestartet. Dies entspricht dem Starten eines Texteditors.
Die zweite Stufe: Der Python-Interpreter dient als Texteditor zum Öffnen des t. py-Datei und kopieren Sie die t.py-Datei von der Festplatte. Der Inhalt wird in den Speicher eingelesen.
Die dritte Stufe: Der Python-Interpreter interpretiert und führt den Code von t.py aus In den Speicher geladen
In der zweiten Stufe hat die t-Datei beim Speichern eine Zeichenkodierung, und beim Öffnen der Datei muss dieselbe Kodierungsmethode angegeben werden (die Standardkodierungsmethode von Python2 ist ASCII). und die Standardkodierungsmethode von Python3 ist utf-8). der Datei, um den Python-Interpreter anzuweisen, nicht seine Standardcodierungsmethode zum Lesen zu verwenden, sondern die in der Header-Datei angegebene Methode zum Lesen der Datei zu verwenden, damit nichts schiefgehen kann.
Die dritte Stufe: Lesen Sie den in den Speicher geladenen Code (standardmäßig Unicode) und führen Sie ihn dann aus. Wenn während der Ausführung ein Vorgang wie das Definieren einer Variablen auftritt, wird ein neuer Speicherbereich geöffnet Erinnerung. Bitte beachten Sie zu diesem Zeitpunkt, dass der neu geöffnete Speicherplatz nicht unbedingt Unicode ist. Der Benutzer kann beim Definieren der Variablen die Codierungsmethode angeben. Der während der Definition geöffnete Speicherplatz ist nur ein Leerzeichen und kann Codes in einem beliebigen Codierungsformat speichern. Nehmen Sie Python3 als Beispiel

4. Kodierung und Dekodierung
Das Speichern einer Datei dient zum Speichern der Datei im Speicher Zur Festplatte
Dateien lesen bedeutet, die Dateien von der Festplatte in den Speicher zu lesen
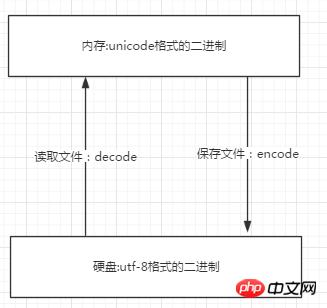
Unicode ist die übergeordnete Kodierung, utf -8, GBK sind die untergeordneten Codierungen. Wenn der Subcode in andere Codes konvertiert werden soll, muss er zuerst in den übergeordneten Code und dann vom übergeordneten Code in andere Subcodes konvertiert werden.
Dekodierung ist Dekodierung. Dabei handelt es sich um den Prozess der Konvertierung des Subcodes in den übergeordneten Code Unicode
Codierung ist Codierung, also den Prozess der Konvertierung von Unicode in andere Codierungen
Wie ich bereits sagte, wenn eine Datei eingelesen wird Im Speicher wird es zur Unicode-Codierung (natürlich ist dies die Standardeinstellung und kann auch gemäß den Anweisungen geändert werden). Der Prozess des Lesens von Dateien von der Festplatte besteht darin, utf-8 auf der Festplatte in Unicode zu dekodieren
. Wenn die Datei gespeichert wird, wird sie aus dem Speicher auf der Festplatte gespeichert. Die Festplatte ist in utf-8 kodiert und muss in utf-8 kodiert werden >
5. Der Unterschied zwischen Python2 und Python31 Die Standardkodierung von Python2 ist ASCII, zum Speichern wird utf-8 geöffnet. Bei der Eingabe wird ein Fehler gemeldet Sie sollten der Header-Datei #coding hinzufügen: utf-8
Str in Python2 wird als Bytes erkannt, daher ist str in Python2 das Ergebnis der Codierung. Tatsächlich wird dies standardmäßig durchgeführt . Die Sache besteht darin, ein u vor str hinzuzufügen, es zuerst in Unicode zu konvertieren und es dann in Bytes zu kodieren.
Es gibt zwei String-Typen in Python2, str und Unicode str, die durch Hinzufügen eines ' konvertiert werden können. u' davor. In Unicode konvertieren
2. Die Standardkodierungsmethode von Python 3 ist utf-8, Sie können in utf-8 gespeicherte Dateien direkt öffnen
Str in Python3 ist als Unicode erkannt
Es gibt auch zwei String-Typen (Bytes und Str) in Python3, aber Bytes ist Bytes und Str ist Unicode
6. Auf dem Terminal drucken Zunächst müssen Sie wissen, dass die Standardkodierungsmethode des Windows-Terminals GBK ist
Das Terminal ist auch eine Anwendung und wird im Speicher ausgeführt, also der Prozess Das Drucken mit print() erfolgt von Speicher zu Speichermitte. Für Unicode tritt also unabhängig von der Druckmethode kein Fehler auf. In Python2 sind die anderen Zeichenfolgen jedoch Bytes. Derzeit verwendet das Terminal die GBK-Codierung, während Python2 die Codierung verwendet Wenn Sie UTF-8 oder den Standard-ASCII-Code angegeben haben, tritt beim Drucken im Terminal ein Fehler auf.
Dies sind mein derzeitiges Verständnis. Wenn ich in Zukunft feststelle, dass es Fehler oder unklare Ausdrücke gibt, werde ich diese überarbeiten. Leider ist die Zeichenkodierung eine Falle
Das obige ist der detaillierte Inhalt vonDetaillierte Erklärung der Zeichenkodierung in Python. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!