
Heim >Betrieb und Instandhaltung >Betrieb und Wartung von Linux >Platzhalter und reguläre Ausdrücke unter Linux
Platzhalter und reguläre Ausdrücke unter Linux
- 巴扎黑Original
- 2017-06-16 10:39:361885Durchsuche
Reguläre Ausdrücke stimmen mit qualifizierten Zeichenfolgen in Dateien überein. Der folgende Artikel stellt Platzhalter und reguläre Ausdrücke unter Linux vor. Freunde, die es benötigen, können darauf verweisen
Platzhalter
* Jedes Zeichen kann sein mehrmals wiederholt
? Jedes Zeichen, einmal wiederholt
[] stellt ein Zeichen dar
Beispiel: [a,b,c] steht für einen beliebigen
Platzhalter in abc
Regulärer Ausdruck zum Abgleichen von Dateinamen
Regulärer Ausdruck wird zum Abgleichen von Zeichenfolgen verwendet, die die Bedingungen in der Datei erfüllen
ls find cp unterstützt keine regulären Ausdrücke
aber grep awk sed unterstützt reguläre Ausdrücke
[root@hadoop-bigdata01 test]# touch aa
[ root@hadoop-bigdata01 test]# touch aab aabb
[root@hadoop-bigdata01 test]# ll
total 0
-rw-r--r-- 1 root root 0 16. Mai 19:47 aa
-rw-r--r -- 1 Wurzel Wurzel 0 16. Mai 19:47 aab
-rw-r--r-- 1 Wurzel Wurzel 0 16. Mai 19:47 aabb
[root @hadoop-bigdata01 test]# ls aa
aa
[root@hadoop-bigdata01 test]# ls aa?
aab
[root@hadoop-bigdata01 test]# ls aa*
aa aab aabb
Regulärer Ausdruck Sonderzeichen
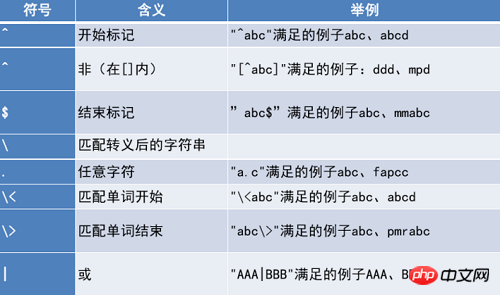
Übereinstimmungsbereich für reguläre Ausdrücke
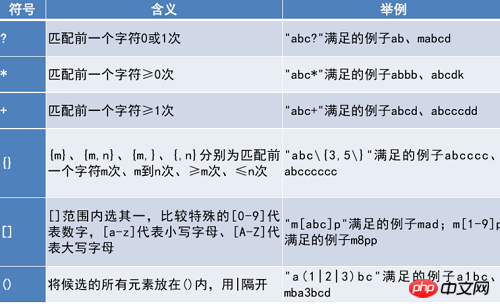
Regular Die Standardzeichen für Ausdrücke

Verwenden Sie den regulären Ausdruck
grep "1" /etc/passwd
, solange die Zeile das Schlüsselwort 1, grep, enthält. Fügen Sie es einfach ein, Sie möchten keine Platzhalter, es müssen genau gleich sein
[root@hadoop-bigdata01 test]# grep "1" /etc/passwd bin:x:1:1:bin:/bin:/sbin/nologin mail:x:8:12:mail:/var/spool/mail:/sbin/nologin uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin operator:x:11:0:operator:/root:/sbin/nologin games:x:12:100:games:/usr/games:/sbin/nologin gopher:x:13:30:gopher:/var/gopher:/sbin/nologin ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin dbus:x:81:81:System message bus:/:/sbin/nologin usbmuxd:x:113:113:usbmuxd user:/:/sbin/nologin avahi-autoipd:x:170:170:Avahi IPv4LL Stack:/var/lib/avahi-autoipd:/sbin/nologin abrt:x:173:173::/etc/abrt:/sbin/nologin wang:x:501:501::/home/wang:/bin/bash grep 'root' /etc/passwd cat /etc/passwd | grep 'root'
sind gleich, aber das Pipe-Zeichen verbraucht mehr Ressourcen
also
1 Zeilen mit Zahlen
grep '[0-9]' /etc/passwd
2. Ordnen Sie Zeilen zu, die drei aufeinanderfolgende Zahlen enthalten
grep '[0-9][0-9][0-9]' /etc/passwd 或者 grep ':[0-9][0-9][0-9]:' /etc/passwd
[root@hadoop-bigdata01 test]# grep '[0-9][0-9][0-9]' /etc/passwd games:x:12:100:games:/usr/games:/sbin/nologin usbmuxd:x:113:113:usbmuxd user:/:/sbin/nologin rtkit:x:499:497:RealtimeKit:/proc:/sbin/nologin avahi-autoipd:x:170:170:Avahi IPv4LL Stack:/var/lib/avahi-autoipd:/sbin/nologin abrt:x:173:173::/etc/abrt:/sbin/nologin nfsnobody:x:65534:65534:Anonymous NFS User:/var/lib/nfs:/sbin/nologin saslauth:x:498:76:"Saslauthd user":/var/empty/saslauth:/sbin/nologin pulse:x:497:496:PulseAudio System Daemon:/var/run/pulse:/sbin/nologin liucheng:x:500:500::/home/liucheng:/bin/bash wang:x:501:501::/home/wang:/bin/bas
3. Passen Sie Zeilen an, die mit r beginnen und mit n enden
grep '^r.*n$' /etc/passwd .*代表所有 [root@hadoop-bigdata01 test]# grep '^r.*n$' /etc/passwd rpc:x:32:32:Rpcbind Daemon:/var/cache/rpcbind:/sbin/nologin rtkit:x:499:497:RealtimeKit:/proc:/sbin/nologin rpcuser:x:29:29:RPC Service User:/var/lib/nfs:/sbin/nologin
4. Filter ifconfig, intercept ip
grep -v steht für Reverse Interception, was bedeutet, dass das Entfernen von Zeilen mit einem bestimmten Schlüsselwort sed die Bedeutung von Ersetzung hat
[root@hadoop-bigdata01 test]# ifconfig | grep 'inet addr:'
inet addr:192.168.126.191 Bcast:192.168.126.255 Mask:255.255.255.0
inet addr:127.0.0.1 Mask:255.0.0.0
[root@hadoop-bigdata01 test]#
[root@hadoop-bigdata01 test]# ifconfig | grep 'inet addr:' | grep -v '127.0.0.1'
inet addr:192.168.126.191 Bcast:192.168.126.255 Mask:255.255.255.0
[root@hadoop-bigdata01 test]# ifconfig | grep 'inet addr:' | grep -v '127.0.0.1' | sed 's/inet addr://g'
192.168.126.191 Bcast:192.168.126.255 Mask:255.255.255.0
[root@hadoop-bigdata01 test]# ifconfig | grep 'inet addr:' | grep -v '127.0.0.1' | sed 's/inet addr://g' | sed 's/Bcast.*//g'
192.168.126.191Missverständnis
Hier besteht schon lange ein Missverständnis. Es ist der Unterschied zwischen regulären Ausdrücken und Platzhalter.
Wir wissen, dass sich der Platzhalter * auf jedes Zeichen bezieht, und der * im regulären Ausdruck, der mehrmals wiederholt werden kann, bezieht sich auf die Übereinstimmung mit dem vorherigen Zeichen >= 0 Mal
Die beiden sind völlig unterschiedlich. Ja, woher weiß ich, ob das *, das ich verwendet habe, ein Platzhalter oder ein regulärer Ausdruck ist? 🎜>
Warum sind die Ergebnisse von grep 'a*c' und grep '^a*c$' unterschiedlich? Ich dachte, eines sei ein Platzhalter und das andere ein regulärer Ausdruck, weil die vier Die von a*c angezeigten Ergebnisse waren genau
Stimmt nur mit einer beliebigen Anzahl von Zeichen überein?
[root@hadoop-bigdata01 test]# touch ac aac abc abbc [root@hadoop-bigdata01 test]# ll total 0 -rw-r--r-- 1 root root 0 May 16 19:55 aac -rw-r--r-- 1 root root 0 May 16 19:55 abbc -rw-r--r-- 1 root root 0 May 16 19:55 abc -rw-r--r-- 1 root root 0 May 16 19:55 ac [root@hadoop-bigdata01 test]# ls | grep 'a*c' aac abbc abc ac [root@hadoop-bigdata01 test]# ls | grep 'a.*c' aac abbc abc ac [root@hadoop-bigdata01 test]# ls | grep '^a.*c' aac abbc abc ac [root@hadoop-bigdata01 test]# ls | grep '^a*c' aac acEigentlich nicht. Der Platzhalter wird verwendet, um den Dateinamen abzugleichen. Der reguläre Ausdruck dient dazu, qualifizierte Zeichen in der Datei zu verwenden, nachdem die Zeichenfolge an das Pipe-Zeichen übergeben wurde. Dies ist eine Operation für die Datei , also ist es genau der reguläre Ausdruck grep 'a*c' Es bedeutet, dass a>=0 übereinstimmt. Solange es also c enthält, ist es in Ordnung und grep '^a *c$' ist ebenfalls ein regulärer Ausdruck, was bedeutet, dass er mit a beginnt und das zweite Zeichen null oder mehrmals mit a übereinstimmt, gefolgt vom Buchstaben c , sodass nur aac und ac
Schauen Sie sich also dieses Beispiel an
Hier bedeutet grep 'a*b' nicht, dass es a und b enthält, sondern dass a 0 oder mehr wiederholt wird mal und dann enthält b
Das Obige ist der vom Herausgeber eingeführte Platzhalter und das reguläre Muster. Wenn Sie Fragen haben, hinterlassen Sie mir bitte eine Nachricht Der Herausgeber wird Ihnen rechtzeitig antworten. Ich möchte mich auch bei Ihnen allen für Ihre Unterstützung der Script House-Website bedanken!
Das obige ist der detaillierte Inhalt vonPlatzhalter und reguläre Ausdrücke unter Linux. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Erfahren Sie, wie Sie den Nginx-Server unter Linux installieren
- Detaillierte Einführung in den wget-Befehl von Linux
- Ausführliche Erläuterung von Beispielen für die Verwendung von yum zur Installation von Nginx unter Linux
- Detaillierte Erläuterung der Worker-Verbindungsprobleme in Nginx
- Detaillierte Erläuterung des Installationsprozesses von Python3 unter Linux