
Heim >Web-Frontend >js-Tutorial >Beispielcode-Analyse eines mehrseitigen Crawlers in NodeJS
Beispielcode-Analyse eines mehrseitigen Crawlers in NodeJS

- 黄舟Original
- 2017-05-31 10:11:271723Durchsuche
In diesem Artikel wird hauptsächlich der auf Nodejs basierende Multi-Page-Crawler vorgestellt. Der Herausgeber findet ihn recht gut, daher werde ich ihn jetzt mit Ihnen teilen und als Referenz angeben. Folgen wir dem Editor und werfen wir einen Blick darauf.
Vorwort
Ich habe die Front-End-Zeit noch einmal überprüftnode.js, also habe ich es ausgenutzt der Situation und machte einen Crawler. Vertiefen Sie Ihr Verständnis von Node.
Die drei hauptsächlich verwendeten Module sind Request, Cheerio und Async
Request
zum Anfordern von Adressen und zum schnellen Herunterladen BilderStream.
cheerio
Eine schnelle, flexible und implementierte jQuery Kernimplementierung, die speziell auf den Server zugeschnitten ist.
Einfach zu analysierender HTML-Code.
asynchron
Asynchroner Aufruf, um Blockierungen zu verhindern.
Kernidee
Verwenden Sie Anfrage, um eine Anfrage zu senden. Holen Sie sich den HTML-Code und das img-Tag sowie ein Tag.
Führen Sie einen rekursiven Aufruf über den erhaltenen Ausdruck durch. Rufen Sie kontinuierlich die IMG-Adresse und eine Adresse ab und führen Sie die Rekursion fort
Erhalten Sie die IMG-Adresse über request(photo).pipe(fs.createWriteStream(dir + „/“ + filename)); für schnelles Herunterladen.
function requestall(url) {
request({
uri: url,
headers: setting.header
}, function (error, response, body) {
if (error) {
console.log(error);
} else {
console.log(response.statusCode);
if (!error && response.statusCode == 200) {
var $ = cheerio.load(body);
var photos = [];
$('img').each(function () {
// 判断地址是否存在
if ($(this).attr('src')) {
var src = $(this).attr('src');
var end = src.substr(-4, 4).toLowerCase();
if (end == '.jpg' || end == '.png' || end == '.jpeg') {
if (IsURL(src)) {
photos.push(src);
}
}
}
});
downloadImg(photos, dir, setting.download_v);
// 递归爬虫
$('a').each(function () {
var murl = $(this).attr('href');
if (IsURL(murl)) {
setTimeout(function () {
fetchre(murl);
}, timeout);
timeout += setting.ajax_timeout;
} else {
setTimeout(function () {
fetchre("http://www.ivsky.com/" + murl);
}, timeout);
timeout += setting.ajax_timeout;
}
})
}
}
});
}Anti-Pits
1 Wenn die Anforderung über die Bildadresse heruntergeladen wird, binden Sie den Fehler Ereignis um eine abnormale Crawler-Unterbrechung zu verhindern.
2. Begrenzen Sie die Parallelität durch die MapBegrenzung von Async.
3. Fügen Sie einen Anforderungsheader hinzu, um zu verhindern, dass IP blockiert wird.
4. Holen Sie sich einige Bilder und Hyperlinks Adressen, bei denen es sich möglicherweise um relative Pfade handelt (um zu prüfen, ob es eine Lösung gibt).
function downloadImg(photos, dir, asyncNum) {
console.log("即将异步并发下载图片,当前并发数为:" + asyncNum);
async.mapLimit(photos, asyncNum, function (photo, callback) {
var filename = (new Date().getTime()) + photo.substr(-4, 4);
if (filename) {
console.log('正在下载' + photo);
// 默认
// fs.createWriteStream(dir + "/" + filename)
// 防止pipe错误
request(photo)
.on('error', function (err) {
console.log(err);
})
.pipe(fs.createWriteStream(dir + "/" + filename));
console.log('下载完成');
callback(null, filename);
}
}, function (err, result) {
if (err) {
console.log(err);
} else {
console.log(" all right ! ");
console.log(result);
}
})
}Test:
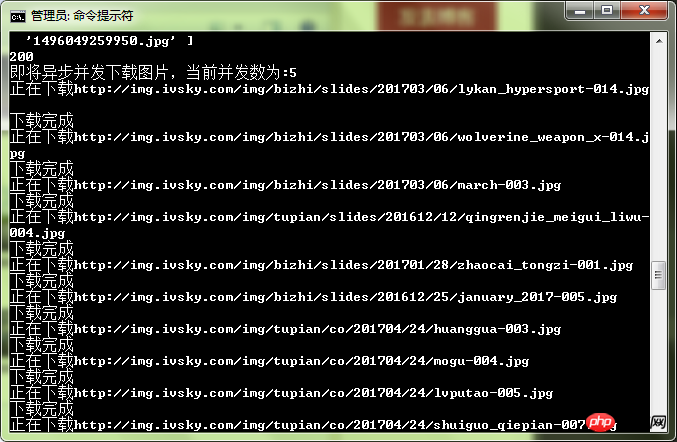
Man spürt, dass die Geschwindigkeit relativ hoch ist.
Das obige ist der detaillierte Inhalt vonBeispielcode-Analyse eines mehrseitigen Crawlers in NodeJS. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Eine eingehende Analyse der Bootstrap-Listengruppenkomponente
- Detaillierte Erläuterung des JavaScript-Funktions-Curryings
- Vollständiges Beispiel für die Generierung von JS-Passwörtern und die Erkennung der Stärke (mit Download des Demo-Quellcodes)
- Angularjs integriert WeChat UI (weui)
- Wie man mit JavaScript schnell zwischen traditionellem Chinesisch und vereinfachtem Chinesisch wechselt und wie Websites den Wechsel zwischen vereinfachtem und traditionellem Chinesisch unterstützen – Javascript-Kenntnisse