
Heim >Backend-Entwicklung >C#.Net-Tutorial >OSS.Core-Grundideen
OSS.Core-Grundideen

- 大家讲道理Original
- 2017-05-28 11:43:311431Durchsuche
Heutzutage ist das Wort Framework populär geworden. Das Architektur-Design von xx Company ist überall zu sehen, aber die meisten davon sind nur zum Spaß gedacht und wie werden die Details berücksichtigt? Was ist die Grundlage für die gegenseitige Isolation ... Ich glaube, viele Freunde haben immer noch ihre eigenen Zweifel, insbesondere angesichts der immer beliebter werdenden Microservices und abgeleiteten Microservice-Gateway-Produkte. Ich hatte gerade vor, ein kleines Open-Source-Framework zu schreiben OSS.Core, ich hatte während des Prozesses einige Gedanken und werde sie in diesem Artikel festhalten. Ich hoffe, dass er allen dabei helfen kann, es so gut wie möglich zu verstehen, was sich wahrscheinlich um die folgenden Fragen dreht:
1. Der Ursprung von Microservices
Die Designidee von Microservices
Das Design und die Implementierung des OSS.Core-Frameworks
Bevor ich darüber spreche, hoffe ich, dass jeder versteht, dass die traditionelle Architektur nicht unabhängig/gegensätzlich ist. Microservices sind ein logisches Konzept, das aus dem traditionellen Framework abgeleitet ist, um Probleme wie die gleichzeitige Wartung zu lösen geht es eher um Veränderungen in der Denkweise und Problemlösung in verschiedenen Phasen des Projekts. Zweitens: Unterscheiden Sie die logische Architektur von der physischen Architektur (Datei). Meistens entspricht die logische Architektur der physischen Architektur, aber manchmal kann eine physische Architektur mehrere logische Architekturen enthalten.
1. Der Ursprung von Microservices
Microservices zerlegen hauptsächlich einige große und komplexe Anwendungen in mehrere Servicekombinationen, wobei jeder Service autonom ist, um mehr Flexibilität und einfachere Wartung zu erreichen.
Zum besseren Verständnis schauen wir uns zunächst drei gängige Methoden zur Lösung der Parallelität an:
1. Fügen Sie eine Datenbank-Master-Slave-Trennung oder sogar Multi-Master-Schreib- oder Partitionierungsmechanismen hinzu und ändern Sie sie entsprechend Fügen Sie die Verbindungszeichenfolge hinzu oder fügen Sie Zugriffs-Middleware in der Anwendung hinzu, um die Verarbeitungskapazität der Datenbank zu verbessern.
2. Da Datenbankressourcen relativ knapp und zeitaufwändig sind, werden zur Verbesserung der Zugriffsgeschwindigkeit im Allgemeinen verteilter Cache usw. verwendet, um den Zugriff auf die darunter liegende Ebene zu reduzieren.
3. Die Lastausgleichs-Offload-Verarbeitung wird auf verschiedene Maschinen verteilt, bevor eine große Anzahl von Anforderungen bei der Anwendung eintrifft, um das Problem der Bandbreite einzelner Maschinen und Leistungsengpässe zu lösen.
Natürlich gibt es viele andere Möglichkeiten, Parallelität zu lösen, wie z. B. Front-End- statische Dateikomprimierung, CDN-Beschleunigung, IP-Ratenkontrolle usw., die hier übersprungen werden.
Viele Freunde sollten die oben genannten drei Methoden gesehen haben, weil sie in Kombination mit diesem Bild einfacher sein können, die Änderungen zwischen traditionellen Gesamtdiensten und Mikrodiensten zu vergleichen:
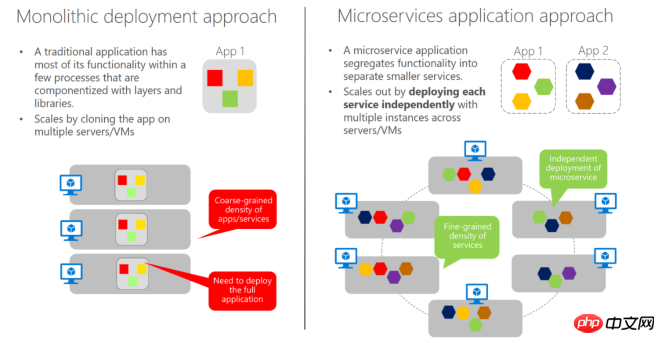
Im traditionellen Gesamtservice-Framework gibt es eine große Kopplung zwischen Modulen, gegenseitige Aufrufe innerhalb des Projekts und verschiedene komplexe Aggregation-Vorgänge, sodass dies in den meisten Fällen der Fall ist Im Bild links können wir sehen, dass wir es während des Lastausgleichs als Ganzes auf mehreren Maschinen bereitstellen müssen. Das Gleiche gilt für die Datenbank und die Anforderungen jedes Moduls in einem Projekt sind unterschiedlich.
Beispielsweise sind die Zugriffshäufigkeit von Produkten und Bestellmodulen und die Komplexität des Prozesses sehr unterschiedlich. Die Bestellhäufigkeit ist relativ gering und die Komplexität hoch Mit hoher Budgetkapazität ist es auch praktisch für eine schnellere Fehlerbehebung und Wartung. Wie Sie im Bild rechts sehen können, können wir nach der Verfeinerung der Leistungen kleinere Einsatzeinheiten nutzen, um diese je nach Situation zu kombinieren.
Gleichzeitig muss ein Produkt in der heutigen Zeit der schnellen Iteration von Internetprodukten in der Lage sein, schnell verschiedene Anwendungsfunktionen für verschiedene Endgeräte zu starten, und gleichzeitig können geschäftliche Anpassungen schnell vorgenommen werden . Das traditionelle Gesamtservicemodell reicht nicht mehr aus. Da Microservices in Teile zerlegt wurden, kann jedes Modul aufgrund seiner Unabhängigkeit schnell miteinander kombiniert werden und jedes Modul kann Programmiersprachen mit unterschiedlichen Eigenschaften entsprechend unterschiedlichen Anforderungspunkten verwenden.
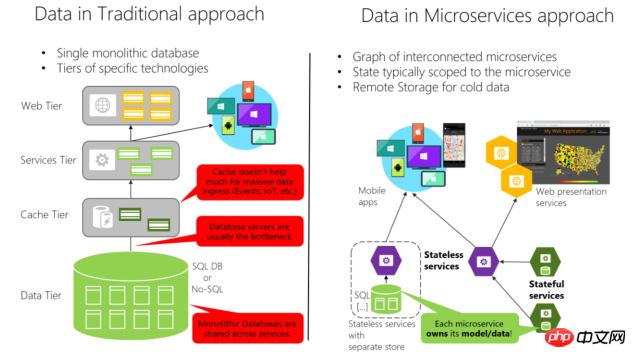
2. Microservice-Designideen
Weil jedes Produkt seine eigenen Standards hat und die wichtigsten Punkte sind Anders beim Entwerfen von Serviceeinheiten, aber es gibt die grundlegendsten Punkte: Dienstautonomie
Wenn Sie ein Microservice-Modul entwerfen, müssen Sie die Unabhängigkeit des aktuellen Dienstes sicherstellen, insbesondere des Datenmoduls ist unabhängig. Andere Dienste haben kein Recht, das Datenbankmodul unter dem aktuellen Dienst zu betreiben. Externe Interaktion kann nur über die Dienst--Schnittstelle durchgeführt werden. Da die Module unabhängig sind, können Sie die passende Programmiersprache und den entsprechenden Einsatzumfang wählen. Erzielen Sie eine lokale flexible Optimierung. Während Microservices unabhängig voneinander sind und die oben genannten Vorteile bieten, bringt sie auch einige Probleme mit sich, denen wir uns stellen müssen:
Zuerst: Wie definiert man die Grenzen des aktuellen Dienstes und wie bestimmt man den Umfang der aktuellen Dienst-Governance?
Da die Serviceeinheit minimiert werden soll, ist es notwendig, die Verantwortungsgrenze des Dienstes zu bestimmen. Es wird empfohlen, dieses Problem zu kombinieren mit: ServiceLebenszyklusProzess, Feld und Geschätzter Maßstab Diese Punkte werden umfassend berücksichtigt, B. Benutzerdienste, wenn die Arbeitsbelastung gering ist und das Personal klein ist, können grundlegende Benutzerinformationen und Kontostände unter einem Servicemodul platziert werden, um Arbeitsbelastung und Ablenkung zu reduzieren. Wenn der Umfang groß ist, kann er in Basisdienste und Asset-Dienste unterteilt werden.
Zweitens: Serviceübergreifende DatenAbfrageProbleme
Zum Beispiel im Client nach Produkten suchen, Sie kann auch nach Benutzern suchen oder wie mit statistischen Datenabfragen umgegangen wird usw. Ich gebe Ihnen zwei Möglichkeiten, damit umzugehen:
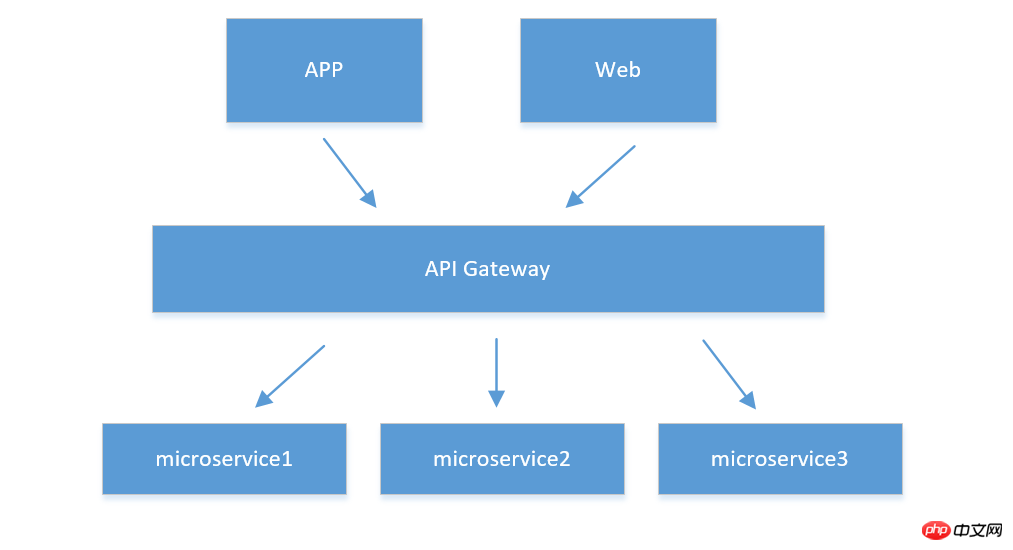
1. API Gateway
Diese Situation eignet sich, wenn zu viele Serviceeinheiten vorhanden sind und der Client Abfragen und Abfragen durchführen muss Für die Daten in der Einheit können wir zu diesem Zeitpunkt ein API-Service-Gateway erstellen (bitte beachten Sie, dass es sich vom APP-Gateway unterscheidet, mit dem der Client nur interagieren muss). das aktuelle Gateway, und das Gateway aggregiert sie und leitet sie an verschiedene Microservices weiter. Wie unten gezeigt:
2. Datenredundanz oder Hintergrunddatensynchronisierung
In den Bestellinformationen benötige ich beispielsweise ein paar Benutzerfelder wie das Benutzername. Zu diesem Zeitpunkt können diese Felder redundant zum Auftrags-Microservice-Datenmodul hinzugefügt werden. Als weiteres Beispiel gehören im Statistikmodul der Datenproduzent und der Abfrager zu völlig unterschiedlichen Objekten , die keine hohe Echtzeitleistung aufweisen. Dann schlage ich vor, einen Statistikdienst und eine entsprechende Statistikdatenbank usw. zu erstellen Dienste durch Ereignis Nachrichteninteraktion, Aktualisierung entsprechende statistische Daten und Abfragen können über die eigenen Daten des Statistikdienstes abgeschlossen werden.
Noch einmal: Wie man das Kommunikationsproblem zwischen Diensten löst
Weil wir die Dienste voneinander unabhängig gemacht und die Möglichkeit abgeschnitten haben, verschiedene Dienstdatenbanken direkt zu betreiben . Wie gehen wir also mit der Datenkonsistenz um? Im traditionellen Service--Modell können wir die Datenkonsistenz durch Transaktionen oder gespeicherte Prozeduren sicherstellen. Es gibt zwei gängige Methoden:
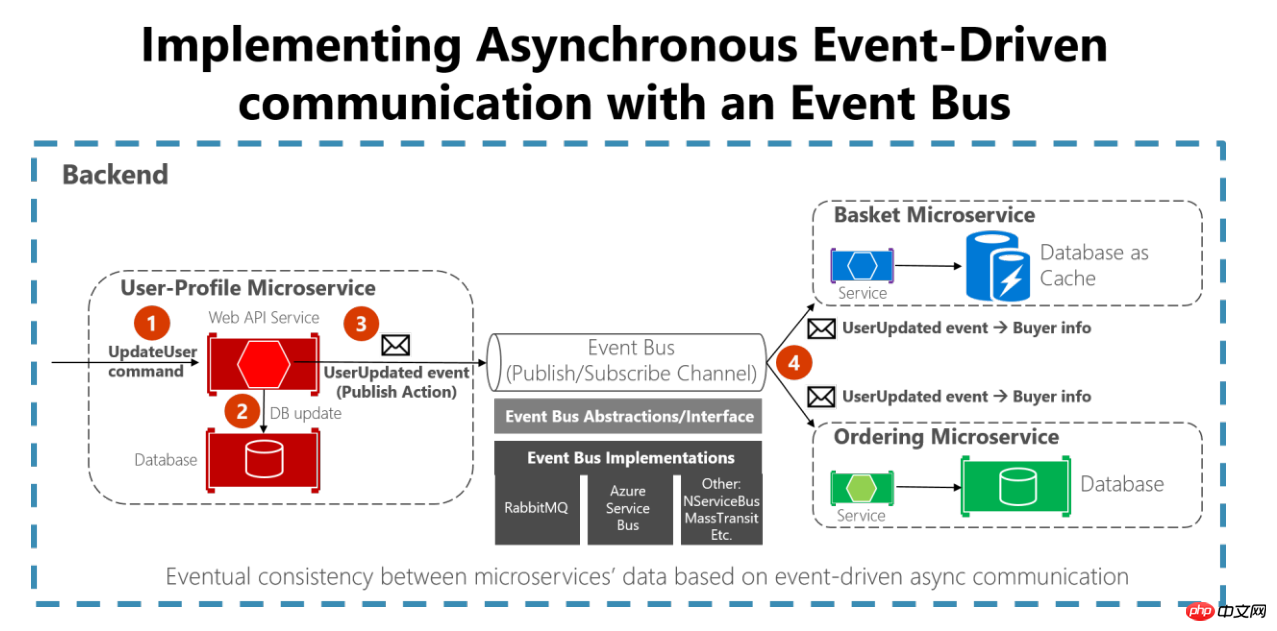
1. Asynchrone Ereignismeldung Treiber
Diese Art von Lösung eignet sich für Szenarien, die relativ geringe Anforderungen an Echtzeitdaten haben, wie z Wie oben wird der Statistikdienst aktualisiert. Nachdem das Dienstereignis, z. B. die Auftragserteilung, ausgelöst wurde, wird die Antwortnachrichtenbenachrichtigung in die Nachrichtenwarteschlange verschoben, und der Dienst, der diese Warteschlange abonniert hat, empfängt aktualisierte Daten. Wie in der Abbildung gezeigt:
2. Direkte Schnittstellenanforderung (HTTP, RPC)
Im Allgemeinen nicht empfohlen, um kaskadierende Abhängigkeiten zu verhindern. Diese Art von Anfrage richtet sich hauptsächlich an Anfragen mit hohem Echtzeit-Datenbedarf. Beispielsweise müssen Sie während des Flash-Sale-Bestellvorgangs sofort wissen, ob der Lagerdienstabzug erfolgreich ist usw. (Hinweis: Die Unterstützung für Aufgaben unter .net ist bereits sehr gut. Es wird empfohlen, asynchrone HTTP-Anfragen zu verwenden, und das Frontend gibt Task<ActionResult> zurück, wodurch der durch E/A verursachte Verbrauch von Arbeitsthreads reduziert wird Operationen)
Abschließend: Wie der Client zugreift
Nachdem wir den Dienst gekapselt haben, müssen wir festlegen, wie der Dienst und der endgültige Clientzugriff darauf basieren müssen Sicherheit Die Regeln und Anforderungen werden separat festgelegt. Wenn relativ wenige Dienste vorhanden sind und die Funktionen nicht komplex sind, kann die Dienstschnittstelle dem Client direkt für den Zugriff zugänglich gemacht werden, wie in der Abbildung dargestellt:
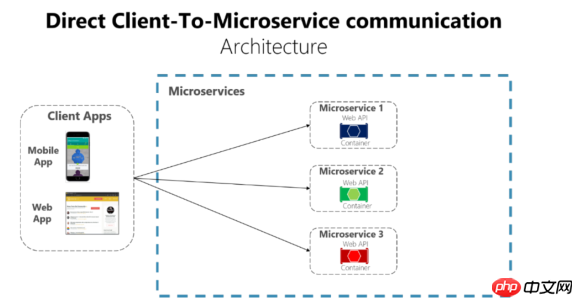
Oder stellen Sie es dem Kunden in Form des oben erwähnten API-Gateways zur Verfügung. Natürlich gibt es auch viele ausgereifte Microservice-Gateways wie Service Fabric oder API Management in der Azure-Cloud.
3. Die Idee und Umsetzung des OSS.Core-Frameworks
Das OSS.Core-Projekt ist ein kleines Open-Source-Produkt, an dem ich kürzlich geschrieben habe. Freunde, die es kennen, sollten wissen, dass ich bereits einige Komponenten geschrieben habe: OSS.Social, OSS.PayCenter, OSS.Common, OSS.Http Ich hoffe, diese Komponenten miteinander zu verbinden. Ich werde mein Bestes geben, um dies in der logischen Architektur dieses Produkts widerzuspiegeln:
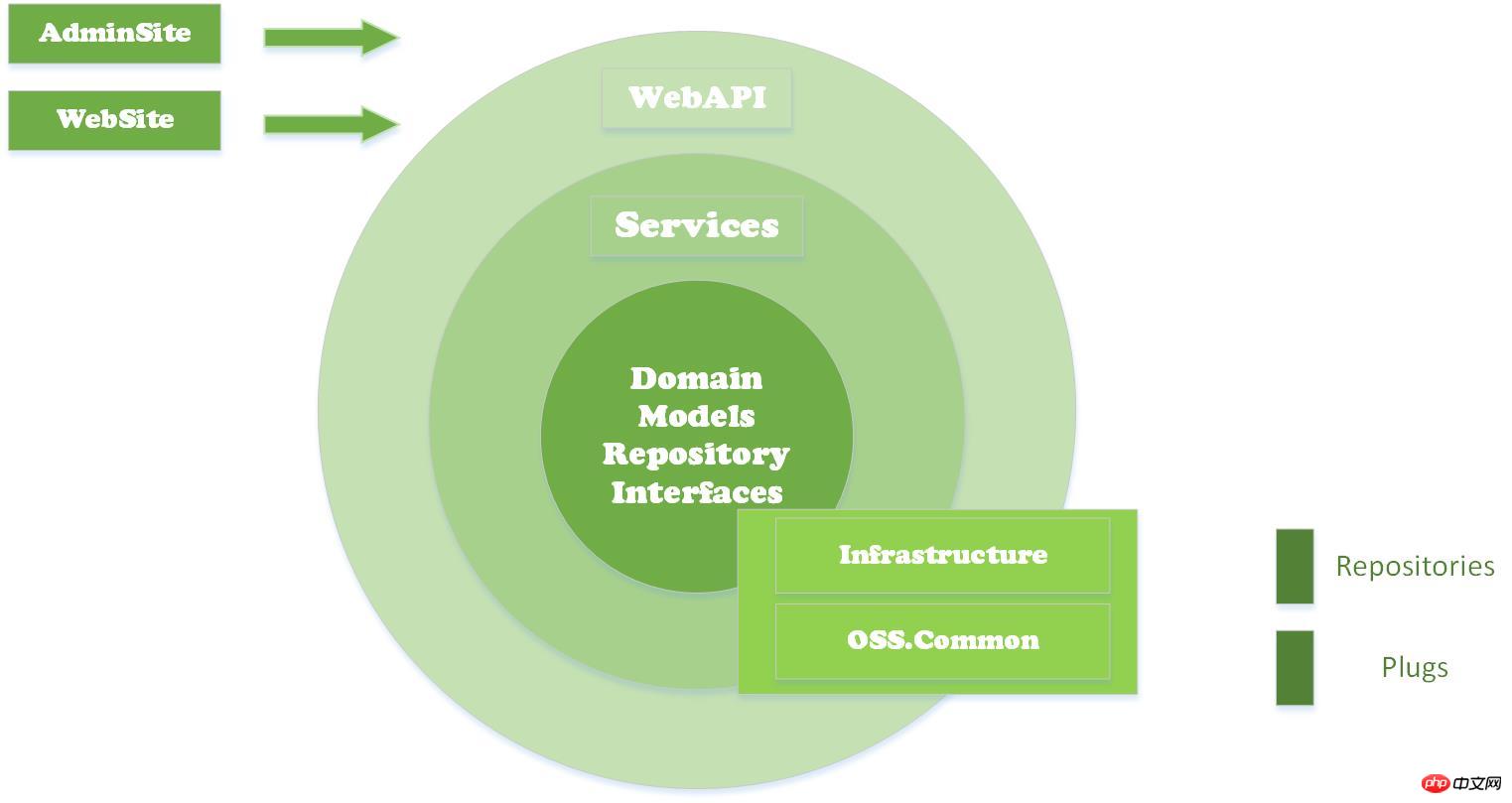
In diesem Projekt werden AdminSite und WebSite im FrontEnds-Ordner platziert. Die beiden Sites sind das Benutzer-Frontend und das Hintergrundverwaltungs-Frontend. Ende
WebApi, Service, DomainMos (Modelles und Schnittstelle im Bild)Klassenbibliothekunter dem Ordner „Ebenen“ und bildet die Basis der API
Infrastructure (geschäftsbezogene allgemeine Entitätsaufzählungs-Hilfsklasse) und Common (geschäftsirrelevante Entitäts-Hilfsklasse) als Infrastrukturklassenbibliotheken, können in allen Ebenen von Klassenbibliotheken aufgerufen werden
Repositorys (vorübergehend) Die Mysql-Implementierung von OSS.Core.RepDapper im Projekt (andere Datenbankunterstützung kann in Zukunft hinzugefügt werden) ist hauptsächlich die spezifische Implementierung von Rep.. Interface.
Plugs sind spezifische Implementierungen von Protokollierungs-, Caching- und Konfigurationsschnittstellen unter dem Common-Plug-in und können auf allen Ebenen direkt über Common aufgerufen werden.
Zurück zum Thema Microservices, ich werde in diesem Projekt keinen Satz von Klassenbibliotheksimplementierungen unter Schichten erstellen Ich kann WebApi als API-Gateway betrachten. Ich hoffe, die interne Aufrufsequenz ist wie folgt:
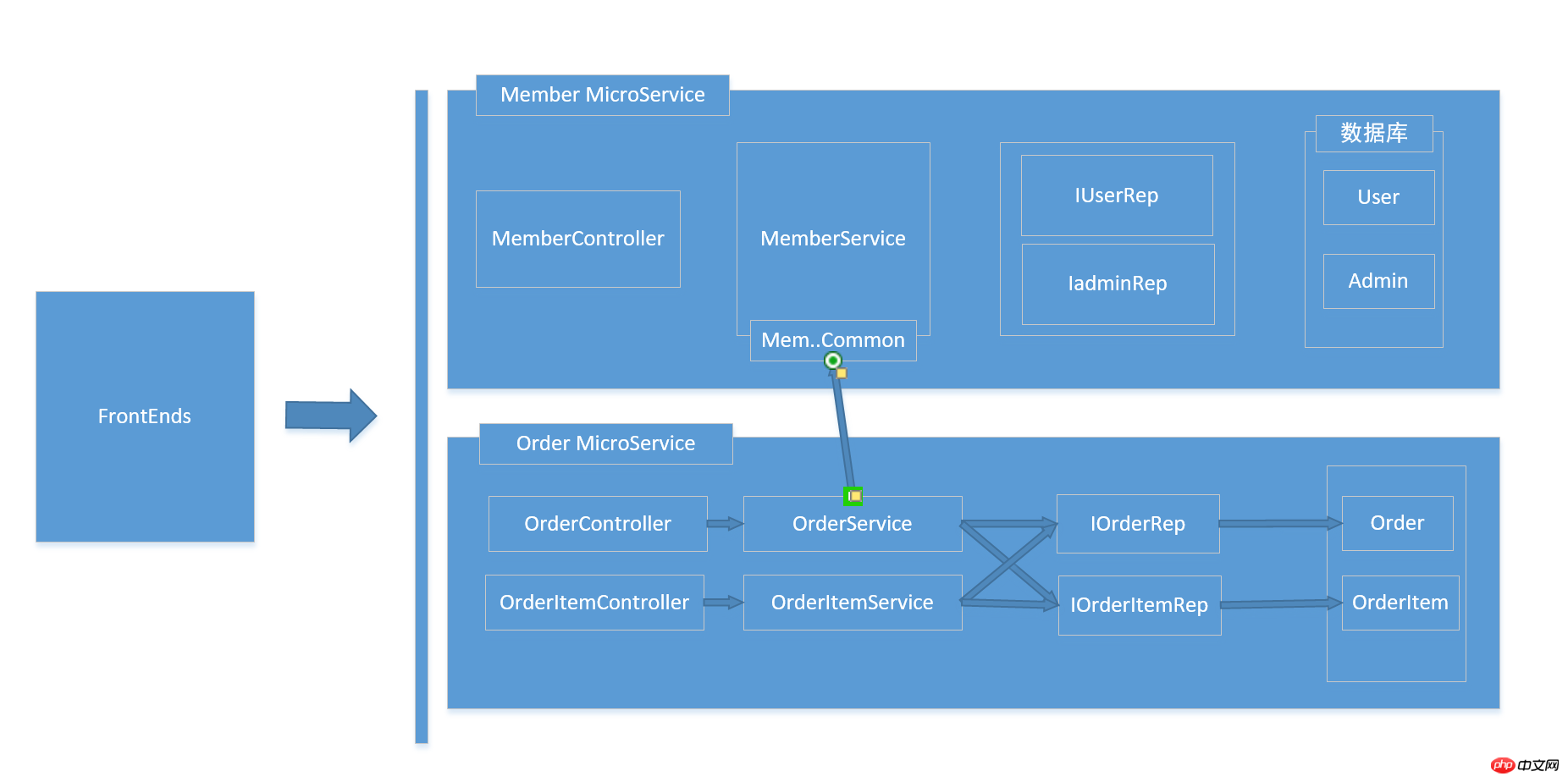
Nun das Codestrukturdiagramm:
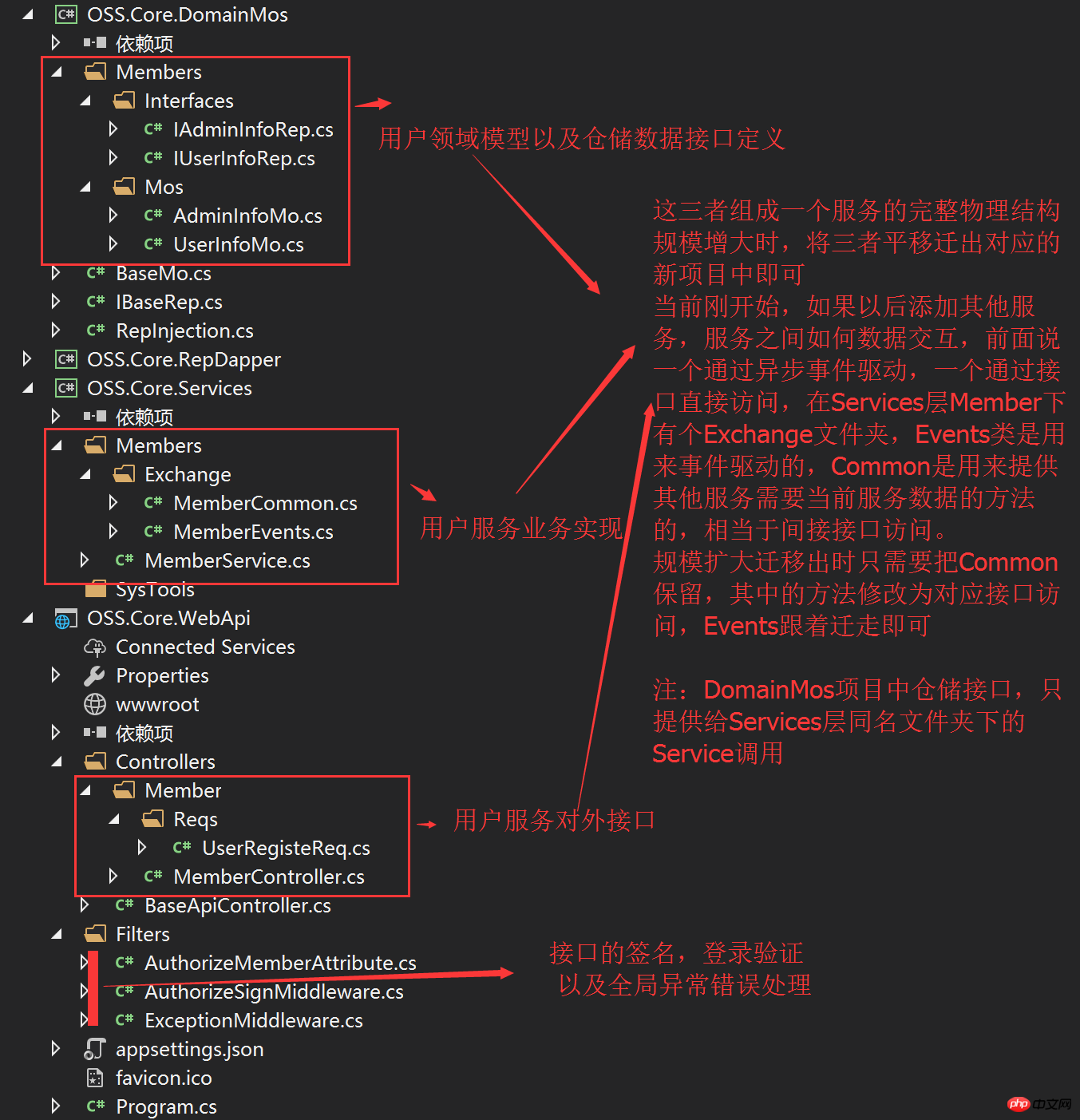
Das obige ist der detaillierte Inhalt vonOSS.Core-Grundideen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- .Net Core-Grafikverifizierungscode
- Laden der .NET Core-Konfigurationsdatei und DI-Injektion von Konfigurationsdaten
- Dokumentation zum .NET Core CLI-Tool dotnet-publish
- asp.net verwendet .net-Steuerelemente, um Dropdown-Navigationsmenüs zu erstellen
- So erhalten Sie den Namen des Controllers in Asp.net MVC