
Heim >Datenbank >MySQL-Tutorial >MySQL-Optimierungsprinzipien
MySQL-Optimierungsprinzipien

- 大家讲道理Original
- 2017-05-28 11:24:141421Durchsuche
Apropos MySQLs Abfrage-Optimierung: Ich glaube, jeder hat eine Menge Fähigkeiten angesammelt: Verwenden Sie kein SELECT *, verwenden Sie keine NULL-Felder , und erstellen Sie eine vernünftige Indizierung , indem Sie den geeigneten Datentyp für das Feld auswählen ... Verstehen Sie diese Optimierungstechniken wirklich? Verstehen Sie, wie es funktioniert? Wird die Leistung in tatsächlichen Szenarien wirklich verbessert? Das glaube ich nicht. Daher ist es besonders wichtig, die Prinzipien hinter diesen Optimierungsvorschlägen zu verstehen. Ich hoffe, dass dieser Artikel es Ihnen ermöglicht, diese Optimierungsvorschläge noch einmal zu prüfen und sie sinnvoll in tatsächlichen Geschäftsszenarien anzuwenden.
MySQL-LogikArchitektur
Wenn Sie sich ein Bild davon machen können, wie die verschiedenen Komponenten von MySQL funktionieren Zusammen hilft das Architekturdiagramm dabei, den MySQL-Server im Detail zu verstehen. Die folgende Abbildung zeigt das logische Architekturdiagramm von MySQL.
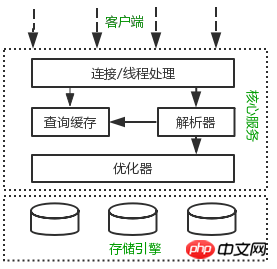
Logische MySQL-Architektur, von: Hochleistungs-MySQL
Die gesamte logische Architektur von MySQL ist in drei Schichten unterteilt. Die oberste Schicht ist die Client-Schicht, die nicht nur für MySQL gilt: Verbindungsverarbeitung, Autorisierungsauthentifizierung, Sicherheit und andere Funktionen werden alle auf dieser Ebene verarbeitet.
Die meisten Kerndienste von MySQL befinden sich in der mittleren Schicht, einschließlich Abfrageparsing, Analyse, Optimierung, Caching, integrierte Funktionen ( wie: Zeit, Mathematik, Verschlüsselung und andere Funktionen). Alle Cross-Storage-Engine-Funktionen sind ebenfalls in dieser Ebene implementiert: gespeicherte Prozeduren, Trigger, Ansichten usw.
Die unterste Ebene ist die Speicher-Engine, die für die Datenspeicherung und den Abruf in MySQL verantwortlich ist. Ähnlich wie das Dateisystem unter Linux hat jede Speicher-Engine ihre Vor- und Nachteile. Die Zwischendienstschicht kommuniziert mit der Speicher-Engine über API. Diese API-Schnittstellen schirmen die Unterschiede zwischen verschiedenen Speicher-Engines ab.
MySQL-Abfrageprozess
Wir hoffen immer, dass MySQL eine höhere Abfrageleistung erzielen kann. Der beste Weg besteht darin, herauszufinden, wie MySQL Abfragen optimiert und ausführt. Sobald Sie dies verstanden haben, werden Sie feststellen, dass ein Großteil der Abfrageoptimierungsarbeit eigentlich nur darin besteht, einige Prinzipien zu befolgen, damit der MySQL-Optimierer wie erwartet und sinnvoll ausgeführt werden kann.
Was genau macht MySQL, wenn eine Anfrage an MySQL gesendet wird?
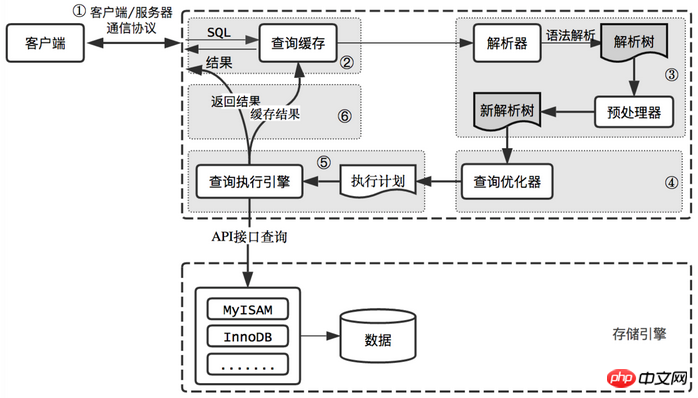
MySQL-Abfrageprozess
Client/Server-Kommunikationsprotokoll
Das MySQL-Client/Server-Kommunikationsprotokoll ist „Halbduplex“: Entweder sendet der Server Daten an den Client oder der Client sendet Daten an den Server. Diese beiden Aktionen können nicht gleichzeitig ausgeführt werden. Sobald ein Ende mit dem Versenden einer Nachricht beginnt, muss das andere Ende die gesamte Nachricht empfangen, bevor es darauf antworten kann. Daher können und müssen wir eine Nachricht nicht in kleine Stücke zerschneiden und sie unabhängig voneinander senden Es gibt keine Möglichkeit, den Fluss zu kontrollieren.
Der Client sendet die Abfrageanforderung in einem separaten Datenpaket an den Server. Wenn die Abfrageanweisung also sehr lang ist, müssen Sie das max_allowed_packet festlegen Parameter. Es ist jedoch zu beachten, dass der Server den Empfang weiterer Daten verweigert und eine Ausnahme auslöst, wenn die Abfrage zu groß ist.
Im Gegenteil antwortet der Server dem Benutzer mit meist vielen Daten, bestehend aus mehreren Datenpaketen. Wenn der Server jedoch auf die Anfrage des Clients antwortet, muss der Client das gesamte zurückgegebene Ergebnis vollständig erhalten, anstatt einfach die ersten paar Ergebnisse zu nehmen und dann den Server aufzufordern, das Senden zu beenden. Daher ist es in der tatsächlichen Entwicklung eine sehr gute Angewohnheit, Abfragen so einfach wie möglich zu halten und nur die erforderlichen Daten zurückzugeben und die Größe und Anzahl der Datenpakete während der Kommunikation zu reduzieren. Dies ist auch der Grund, warum wir versuchen, die Verwendung von SELECT zu vermeiden * und Hinzufügen von LIMIT-Einschränkungen in Abfragen eins.
Abfrage-Cache
Wenn der Abfragecache aktiviert ist, prüft MySQL vor dem Parsen einer Abfrageanweisung, ob die Abfrageanweisung auf die Daten im Abfragecache trifft. Wenn die aktuelle Abfrage zufällig den Abfragecache trifft, werden die Ergebnisse im Cache direkt nach der einmaligen Überprüfung der Benutzerberechtigungen zurückgegeben. In diesem Fall wird die Abfrage nicht analysiert, kein Ausführungsplan generiert und nicht ausgeführt.
MySQL speichert den Cache in einer Referenztabelle (verstehen Sie es nicht als Tabelle, es kann als ähnlich zu Hash betrachtet werden). Map Datenstruktur), indiziert durch einen Hash-Wert, der aus der Abfrage selbst, der aktuell abgefragten Datenbank, der Versionsnummer des Client-Protokolls und anderen Informationen berechnet wird, die sich auf die Ergebnisse auswirken können. Daher führt jeder Unterschied in den Zeichen zwischen den beiden Abfragen (z. B. Leerzeichen, Kommentare ) dazu, dass der Cache fehlt.
Wenn die Abfrage einen Benutzerbenutzerdefinierte Funktion, eine gespeicherte Funktion, einen BenutzerVariable, eine temporäre Tabelle, eine Systemtabelle in der MySQL-Bibliothek usw. enthält Abfrageergebnisse
werden nicht zwischengespeichert. Beispielsweise gibt die Funktion NOW() oder CURRENT_DATE() aufgrund unterschiedlicher Abfragezeiten unterschiedliche Abfrageergebnisse zurück. Ein weiteres Beispiel ist, dass die Abfrageanweisung CURRENT_USER oder CONNECION_ID() enthält. Aufgrund unterschiedlicher Abfragezeiten werden unterschiedliche Ergebnisse für unterschiedliche Benutzer zurückgegeben, und es macht keinen Sinn, solche Abfrageergebnisse zwischenzuspeichern.
Da es sich um einen Cache handelt, läuft er ab. Wann läuft der Abfrage-Cache ab? Das Abfrage-Caching-System von MySQL verfolgt jede an der Abfrage beteiligte Tabelle. Wenn sich diese Tabellen (Daten oder Struktur) ändern, sind alle zwischengespeicherten Daten, die sich auf diese Tabelle beziehen, ungültig. Aus diesem Grund muss MySQL bei jedem Schreibvorgang alle Caches für die entsprechende Tabelle ungültig machen. Wenn der Abfragecache sehr groß oder fragmentiert ist, kann dieser Vorgang zu einer hohen Systemauslastung führen und sogar dazu führen, dass das System für eine Weile einfriert. Darüber hinaus wird der Abfragecache auf dem System nicht nur für Schreibvorgänge, sondern auch für Lesevorgänge zusätzlich beansprucht:
Jede Abfrageanweisung muss vor dem Start überprüft werden, auch diese SQL-Anweisung Der Cache wird niemals erreicht
Wenn die Abfrageergebnisse zwischengespeichert werden können, werden die Ergebnisse nach Abschluss der Ausführung im Cache gespeichert, was ebenfalls zu zusätzlichem Systemverbrauch führt
Auf dieser Grundlage müssen wir wissen, dass das Caching von Abfragen nicht unter allen Umständen zu einer Verbesserung der Systemleistung führt Die von ihm selbst verbrauchten Ressourcen können zu einer Leistungsverbesserung des Systems führen. Es ist jedoch sehr schwierig zu beurteilen, ob das Einschalten des Caches zu Leistungsverbesserungen führen kann, und dies würde den Rahmen dieses Artikels sprengen. Wenn das System tatsächlich Leistungsprobleme hat, können Sie versuchen, den Abfragecache zu aktivieren und einige Optimierungen am Datenbankdesign vorzunehmen, wie zum Beispiel:
Ersetzen Sie eine große Tabelle durch mehrere kleine Tabellen Achten Sie darauf, es nicht zu übertreiben. Entwerfen Sie
Batch-Einfügung anstelle von Schleife Einzeleinfügung
, um das einigermaßen zu kontrollieren Im Allgemeinen ist die Größe auf Mehrere Dutzend Megabyte geeigneter.
Sie können SQL_CACHE und SQL_NO_CACHE verwenden, um zu steuern, ob ein bestimmter Die Abfrageanweisung muss zwischengespeichert werden
Der letzte Ratschlag ist, den Abfragecache nicht einfach einzuschalten, insbesondere bei schreibintensiven Anwendungen. Wenn Sie wirklich nichts dagegen tun können, können Sie query_cache_type auf DEMAND setzen. Zu diesem Zeitpunkt werden nur Abfragen zwischengespeichert, andere Abfragen jedoch nicht. Dadurch können Sie frei steuern, welche Abfragen zwischengespeichert werden müssen.
Natürlich ist das Abfrage-Cache-System selbst sehr komplex, und was hier besprochen wird, ist nur ein kleiner Teil anderer tiefergehender Themen, wie zum Beispiel: Wie nutzt der Cache den Speicher? ? Wie kann die Speicherfragmentierung kontrolliert werden? Leser können die relevanten Informationen über die Auswirkungen von Transaktionen auf den Abfrage-Cache usw. selbst lesen. Dies ist der Ausgangspunkt.
Grammatikanalyse und Vorverarbeitung
MySQL analysiert die SQL-Anweisung anhand von Schlüsselwörtern und generiert einen entsprechenden Analysebaum. Dieser Prozessparser überprüft und analysiert hauptsächlich Grammatikregeln. Zum Beispiel, ob in SQL die falschen Schlüsselwörter verwendet werden oder ob die Reihenfolge der Schlüsselwörter korrekt ist usw. Bei der Vorverarbeitung wird außerdem geprüft, ob der Parse-Baum gemäß den MySQL-Regeln zulässig ist. Überprüfen Sie beispielsweise, ob die abzufragende Datentabelle und Datenspalte vorhanden ist usw.
Abfrageoptimierung
Der durch die vorherigen Schritte generierte Syntaxbaum gilt als zulässig und wird vom Optimierer in einen Abfrageplan umgewandelt. In den meisten Fällen kann eine Abfrage auf viele Arten ausgeführt werden, und alle liefern entsprechende Ergebnisse. Die Rolle des Optimierers besteht darin, unter ihnen den besten Ausführungsplan zu finden.
MySQL verwendet einen kostenbasierten Optimierer, der versucht, die Kosten einer Abfrage anhand eines bestimmten Ausführungsplans vorherzusagen und denjenigen mit den geringsten Kosten auszuwählen. In MySQL können Sie die Kosten für die Berechnung der aktuellen Abfrage ermitteln, indem Sie den Wert von last_query_cost der aktuellen Sitzung abfragen.
Mysql-Code
mysql> select * from t_message limit 10;
-
...Ergebnismenge auslassen
mysql> ------------+-----------+
|. Wert | 🎜 >
+-----------------+-------------+ - |. Last_query_cost |.
- +------------------------- -+
Die Ergebnisse im Beispiel zeigen, dass der Optimierer davon ausgeht, dass etwa 6391 zufällige Suchvorgänge auf Datenseiten erforderlich sind, um die obige Abfrage abzuschließen. Dieses Ergebnis wird auf der Grundlage einiger Spaltenstatistiken berechnet, zu denen Folgendes gehört: die Anzahl der Seiten in jeder Tabelle oder jedem Index, die Kardinalität des Index, die Länge des Index und der Datenzeilen, die Verteilung des Index usw.
Es gibt viele Gründe, warum MySQL möglicherweise den falschen Ausführungsplan wählt, z. B. ungenaue statistische Informationen und die Nichtberücksichtigung von Betriebskosten, die außerhalb seiner Kontrolle liegen (benutzerdefinierte Funktionen, gespeicherte Prozeduren). MySQL denkt, dass es optimal ist, unterscheidet sich von dem, was wir denken (wir möchten, dass die Ausführungszeit so kurz wie möglich ist, aber MySQL wählt den Wert, den es für gering hält, aber kleine Kosten bedeuten nicht eine kurze Ausführungszeit) und so weiter.
Der Abfrageoptimierer von MySQL ist eine sehr komplexe Komponente, die viele Optimierungsstrategien verwendet, um einen optimalen Ausführungsplan zu generieren:
Definieren Sie die Zuordnungsreihenfolge neu von Tabellen (wenn mehrere Tabellen mit Abfragen verknüpft sind, folgen sie nicht unbedingt der in SQL angegebenen Reihenfolge, es gibt jedoch einige Techniken zum Festlegen der Zuordnungsreihenfolge)
- Optimierung MIN() und MAX()-Funktionen (Finden Sie den Minimalwert einer bestimmten Spalte. Wenn die Spalte einen Index hat, müssen Sie nur das äußerste linke Ende des B+Tree-Index finden. Andernfalls können Sie den Maximalwert ermitteln. Einzelheiten finden Sie weiter unten Prinzip)
- Optimieren Sie die Sortierung (wird in älteren Versionen von MySQL verwendet. Sortierung mit zwei Übertragungen bedeutet, dass zuerst der Zeilenzeiger und die zu sortierenden Felder gelesen und im Speicher sortiert werden und dann die Datenzeilen basierend auf den Sortierergebnissen gelesen werden. Das Neue Die Version verwendet eine Einzelübertragungssortierung, bei der alle Datenzeilen nach der angegebenen Spalte sortiert werden. Bei I/O-intensiven Anwendungen ist die Effizienz viel höher.
- Während sich MySQL weiterentwickelt, entwickeln sich auch die Optimierungsstrategien ständig weiter. Hier sind nur einige sehr häufig verwendete und leicht verständliche Optimierungsstrategien. Sie können sie selbst ausprobieren.
Nach Abschluss der Analyse- und Optimierungsphasen generiert MySQL den entsprechenden Ausführungsplan und die Abfrageausführungs-Engine führt die Anweisungen nach und nach entsprechend aus Anweisungen des Ausführungsplans. Erhalten Sie Ergebnisse. Die meisten Vorgänge im gesamten Ausführungsprozess werden durch Aufrufen der von der Speicher-Engine implementierten Schnittstellen abgeschlossen. Diese Schnittstellen werden als han
dlerAPI bezeichnet. Jede Tabelle im Abfrageprozess wird durch eine Handlerinstanz dargestellt. Tatsächlich erstellt MySQL während der Abfrageoptimierungsphase eine Handlerinstanz für jede Tabelle. Der Optimierer kann tabellenbezogene Informationen basierend auf den Schnittstellen dieser Instanzen abrufen, einschließlich aller Spaltennamen der Tabelle, Indexstatistiken usw. Die Speicher-Engine-Schnittstelle bietet sehr umfangreiche Funktionen, aber auf der untersten Ebene gibt es nur Dutzende von Schnittstellen. Diese Schnittstellen sind wie Bausteine, um die meisten Vorgänge einer Abfrage abzuschließen.
Ergebnisse an den Client zurückgeben Der letzte Schritt der Abfrageausführung besteht darin, die Ergebnisse an den Client zurückzugeben. Selbst wenn keine Daten abgefragt werden können, gibt MySQL dennoch relevante Informationen über die Abfrage zurück, z. B. die Anzahl der von der Abfrage betroffenen Zeilen, die Ausführungszeit usw.
Wenn der Abfrage-Cache aktiviert ist und die Abfrage zwischengespeichert werden kann, speichert MySQL auch die Ergebnisse im Cache.
Die Rückgabe des Ergebnissatzes an den Client ist ein inkrementeller und schrittweiser Rückgabeprozess. Es ist möglich, dass MySQL beginnt, die Ergebnismenge nach und nach an den Client zurückzugeben, wenn das erste Ergebnis generiert wird. Auf diese Weise muss der Server nicht zu viele Ergebnisse speichern und nicht zu viel Speicher verbrauchen, und der Client kann die zurückgegebenen Ergebnisse auch so schnell wie möglich erhalten. Es ist zu beachten, dass jede Zeile im Ergebnissatz als Datenpaket gesendet wird, das dem in ① beschriebenen Kommunikationsprotokoll entspricht, und dann über das TCP-Protokoll übertragen wird. Während des Übertragungsprozesses können MySQL-Datenpakete zwischengespeichert und dann gesendet werden Chargen.
Lassen Sie uns zurückgehen und den gesamten Abfrageausführungsprozess von MySQL zusammenfassen. Im Allgemeinen ist er in 6 Schritte unterteilt:
Der Client sendet eine Abfrageanforderung an den MySQL-Server
Der Server überprüft zunächst den Abfragecache und gibt bei Erreichen des Caches sofort die im Cache gespeicherten Ergebnisse zurück. Andernfalls gehen Sie zur nächsten Stufe über
Der Server führt die SQL-Analyse und Vorverarbeitung durch, und dann generiert der Optimierer den entsprechenden Ausführungsplan
MySQL führt den aus Planen Sie entsprechend, rufen Sie die API der Speicher-Engine auf, um die Abfrage auszuführen
und geben Sie die Ergebnisse an den Client zurück, während Sie die Abfrageergebnisse zwischenspeichern
LeistungsoptimierungVorschläge
Nachdem Sie so viel gelesen haben, können Sie einige Optimierungsmethoden erwarten. Ja, im Folgenden werden einige Optimierungsvorschläge aus drei verschiedenen Aspekten gegeben. Aber warten Sie, es gibt noch einen weiteren Ratschlag: Glauben Sie nicht die „absolute Wahrheit“, die Sie über die Optimierung sehen, einschließlich dessen, was in diesem Artikel besprochen wird, sondern überprüfen Sie sie durch Tests in tatsächlichen Geschäftsszenarien und Reaktionszeiten.
Schemadesign und Datentypoptimierung
Befolgen Sie bei der Auswahl der Datentypen einfach das Prinzip „Klein und einfach“. , Speicher und erfordert weniger CPU-Zyklen für die Verarbeitung. Einfachere Datentypen erfordern bei Berechnungen weniger CPU-Zyklen. Beispielsweise sind Ganzzahlen billiger als Zeichenoperationen, daher werden Ganzzahlen zum Speichern von IP-Adressen verwendet, DATETIME wird zum Speichern von Zeit verwendet und anstelle von Zeichenfolge.
Hier sind einige Tipps, die leicht zu verstehen und zu Fehlern führen können:
Im Allgemeinen ist das Ändern einer NULL-Spalte in NOT NULL nicht möglich Wie sehr trägt es zur Leistung bei, außer dass Sie die Spalte auf NOT NULL setzen sollten, wenn Sie vorhaben, einen Index für eine Spalte zu erstellen?
Die Angabe der Breite für den Ganzzahltyp, wie z. B. INT(11), ist nutzlos. INT verwendet 16 als Speicherplatz, daher wurde sein Darstellungsbereich bestimmt, sodass INT(1) und INT(20) für Speicherung und Berechnung gleich sind.
UNSIGNED bedeutet, dass negative Werte nicht zulässig sind, was die Obergrenze positiver Zahlen ungefähr verdoppeln kann. Beispielsweise ist der Speicherbereich von TINYINT im Allgemeinen groß und es besteht keine Notwendigkeit, den Datentyp DECIMAL zu verwenden. Selbst wenn Sie Finanzdaten speichern müssen, können Sie BIGINT weiterhin verwenden. Wenn Sie beispielsweise auf ein Zehntausendstel genau sein müssen, können Sie die Daten mit einer Million multiplizieren und TIMESTAMP verwenden, um 4 Byte Speicherplatz zu verwenden, und DATETIME, um 8 Byte Speicherplatz zu verwenden. Daher kann TIMESTAMP nur 1970–2038 darstellen, was einen viel kleineren Bereich als DATETIME darstellt, und der Wert von TIMESTAMP variiert je nach Zeitzone.
In den meisten Fällen besteht keine Notwendigkeit, Aufzählungstypen zu verwenden. Einer der Nachteile besteht darin, dass die Liste der Aufzählungszeichenfolgen fest ist und das Hinzufügen und Entfernen von Zeichenfolgen (Aufzählungsoptionen) erforderlich ist ) ALTER TABLE muss verwendet werden (wenn Sie nur Elemente an das Ende der Liste anhängen, müssen Sie die Tabelle nicht neu erstellen).
Verfügen Sie nicht über zu viele Schemaspalten. Der Grund dafür ist, dass die Speicher-Engine-API, wenn sie funktioniert, Daten über das Zeilenpufferformat zwischen der Serverschicht und der Speicher-Engine-Schicht kopieren und dann den Pufferinhalt in jede Spalte auf der Serverschicht dekodieren muss Der Prozess ist sehr hoch. Wenn zu viele Spalten vorhanden sind und nur wenige Spalten tatsächlich verwendet werden, kann dies zu einer hohen CPU-Auslastung führen.
ALTER TABLE einer großen Tabelle ist sehr zeitaufwändig. Die Art und Weise, wie MySQL die meisten Ergebnisoperationen Tabelle ändern ausführt, besteht darin, eine leere Tabelle mit einer neuen zu erstellen Struktur und Abfrage aus der alten Tabelle. Fügen Sie alle Daten in die neue Tabelle ein und löschen Sie dann die alte Tabelle. Insbesondere wenn nicht genügend Speicher vorhanden ist, die Tabelle groß ist und große Indizes vorhanden sind, dauert es länger. Natürlich gibt es einige seltsame und obszöne Techniken, die dieses Problem lösen können. Wenn Sie interessiert sind, können Sie sie selbst ausprobieren.
Hochleistungsindizes erstellen
Indizes sind eine wichtige Möglichkeit, die Leistung von MySQL-Abfragen zu verbessern. Zu viele Indizes können jedoch zu einer übermäßigen Festplatten- und Speichernutzung führen Auswirkungen auf die Gesamtleistung der Anwendung haben. Sie sollten versuchen, das nachträgliche Hinzufügen von Indizes zu vermeiden, da Sie anschließend möglicherweise eine große Menge SQL überwachen müssen, um das Problem zu lokalisieren, und die Zeit zum Hinzufügen eines Indexes definitiv viel länger ist als die Zeit, die zum anfänglichen Hinzufügen eines Indexes erforderlich ist Es ist ersichtlich, dass das Hinzufügen eines Index auch sehr technisch ist.
Im Folgenden zeigen wir Ihnen eine Reihe von Strategien zum Erstellen leistungsstarker Indizes und die Arbeitsprinzipien hinter jeder Strategie. Zuvor hilft Ihnen das Verständnis einiger Algorithmen und Datenstrukturen im Zusammenhang mit der Indizierung, den folgenden Inhalt besser zu verstehen.
Indexbezogene Datenstrukturen und Algorithmen
Normalerweise bezieht sich der Index, auf den wir uns beziehen, auf den B-Tree-Index, der derzeit der am häufigsten verwendete und effektivste Index zum Auffinden von Daten in relationalen Datenbanken ist. Die meisten Speicher-Engines unterstützen diesen Index. Der Begriff B-Tree wird verwendet, weil MySQL dieses Schlüsselwort in CREATE TABLE oder anderen -Anweisungen verwendet, aber tatsächlich können verschiedene Speicher-Engines unterschiedliche Datenstrukturen verwenden. Beispielsweise verwendet InnoDB B+ Tree.
Das B in B+Tree bezieht sich auf Gleichgewicht, was Gleichgewicht bedeutet. Es ist zu beachten, dass der B+-Baumindex keine bestimmte Zeile mit einem bestimmten Schlüsselwert finden kann. Er findet nur die Seite, auf der sich die gesuchte Datenzeile befindet. Dann liest die Datenbank die Seite in den Speicher und sucht dann im Speicher , und schließlich Holen Sie sich die Daten, die Sie suchen. Bevor wir B+Tree einführen, wollen wir zunächst den binären Suchbaum verstehen. Der Wert seines linken Teilbaums ist immer kleiner als der Wert des Stammbaums Der Wert des Teilbaums ist immer größer als der Wert der Wurzel, wie in der folgenden Abbildung dargestellt ①. Wenn Sie in diesem Baum einen Datensatz mit einem Wert von 5 finden möchten, ist der allgemeine Vorgang wie folgt: Suchen Sie zuerst die Wurzel, deren Wert 6 ist, was größer als 5 ist. Suchen Sie also im linken Teilbaum nach 3 und 5 ist größer als 3, und dann den richtigen Teilbaum von 3 Baum finden, ich habe ihn insgesamt dreimal gefunden. Wenn Sie nach einem Datensatz mit einem Wert von 8 suchen, müssen Sie auf die gleiche Weise ebenfalls dreimal suchen. Daher beträgt die durchschnittliche Anzahl der Suchvorgänge im binären Suchbaum (3 + 3 + 3 + 2 + 2 + 1) / 6 = 2,3 Mal. Wenn Sie sequentiell suchen, benötigen Sie nur 1 Mal, um den Datensatz mit dem Wert 2 zu finden. Der Suchwert beträgt jedoch 8 Datensätze und erfordert 6 Mal, sodass die durchschnittliche Anzahl der Suchvorgänge für die sequentielle Suche beträgt: (1 + 2 + 3 + 4 + 5 + 6) / 6 = 3,3 Mal, da in den meisten Fällen die durchschnittliche Suchgeschwindigkeit beträgt Der binäre Suchbaum ist eine sequentielle Suche, die schneller ist.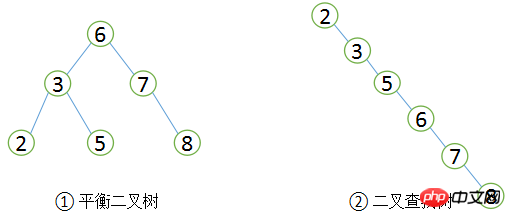
Suchbaum
), während B +Baum Es handelt sich um einen Mehrweg-Suchbaum. Wenn Sie B + Tree verstehen, müssen Sie nur die beiden wichtigsten Funktionen verstehen: Erstens werden alle Schlüsselwörter (die als Daten verstanden werden können) in Blattknoten (Blattseite) gespeichert, und Nicht-Blattknoten (Indexseite) sind nicht vorhanden Es werden reale Daten gespeichert, und alle Datensatzknoten werden in der Reihenfolge ihres Schlüsselwerts auf derselben Schicht von Blattknoten gespeichert. Zweitens sind alle Blattknoten durch Zeiger verbunden. Das Bild unten zeigt einen vereinfachten B+Baum mit einer Höhe von 2. 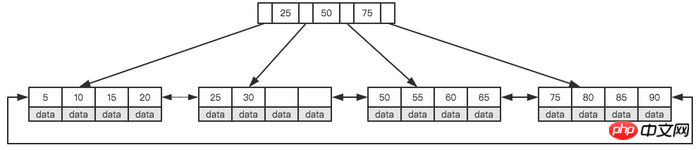
Wie sind diese beiden Merkmale zu verstehen? MySQL legt die Größe jedes Knotens auf ein ganzzahliges Vielfaches einer Seite fest (die Gründe werden weiter unten erläutert). Wenn also die Größe des Knotenraums sicher ist, kann jeder Knoten mehr interne Knoten speichern, sodass jeder Knoten dies tun kann Der Bereich von Der Index ist größer und präziser. Der Vorteil der Verwendung von Zeigerlinks für alle Blattknoten besteht darin, dass ein Intervallzugriff möglich ist. Wenn Sie beispielsweise in der Abbildung oben nach Datensätzen suchen, die größer als 20 und kleiner als 30 sind, müssen Sie nur Knoten 20 finden, und das ist möglich Durchlaufen Sie die Zeiger, um nacheinander 25 und 30 zu finden. Wenn kein Linkzeiger vorhanden ist, kann die Intervallsuche nicht durchgeführt werden. Dies ist auch ein wichtiger Grund, warum MySQL B+Tree als Indexspeicherstruktur verwendet.
Warum MySQL die Knotengröße auf ein ganzzahliges Vielfaches der Seite festlegt, erfordert ein Verständnis des Speicherprinzips der Festplatte. Die Zugriffsgeschwindigkeit der Festplatte selbst ist viel langsamer als die des Hauptspeichers. Zusätzlich zum mechanischen Bewegungsverlust (insbesondere bei herkömmlichen mechanischen Festplatten) beträgt die Zugriffsgeschwindigkeit der Festplatte häufig ein Millionstel der des Hauptspeichers Um die Festplatten-E/A zu minimieren, wird die Festplatte häufig nicht ausschließlich bei Bedarf gelesen, sondern jedes Mal im Voraus. Selbst wenn nur ein Byte benötigt wird, beginnt die Festplatte an dieser Position und liest nacheinander eine bestimmte Datenlänge rückwärts und legen Sie es in den Speicher. Die Länge des Vorlesevorgangs ist im Allgemeinen ein ganzzahliges Vielfaches der Seiten.
Zitat
Eine Seite ist ein logischer Block computerverwalteten Speichers. Hardware und Betriebssystem unterteilen häufig Hauptspeicher- und Festplattenspeicherbereiche in aufeinanderfolgende gleich große Blöcke . (In vielen Betriebssystemen beträgt die Seitengröße normalerweise 4 KB). Hauptspeicher und Festplatte tauschen Daten in Seiteneinheiten aus. Wenn sich die vom Programm zu lesenden Daten nicht im Hauptspeicher befinden, wird eine Seitenfehlerausnahme ausgelöst. Zu diesem Zeitpunkt sendet das System ein Lesesignal an die Festplatte und die Festplatte findet die Startposition der Daten und eine oder mehrere Seiten rückwärts lesen, dann abnormal zurückkehren und das Programm weiter ausführen.
MySQL nutzt geschickt das Prinzip des Disk-Read-Ahead, um die Größe eines Knotens auf eine Seite festzulegen, sodass jeder Knoten nur eine E/A benötigt, um vollständig geladen zu werden. Um dieses Ziel zu erreichen, wird bei jeder Erstellung eines neuen Knotens direkt eine Seite Speicherplatz beantragt. Dadurch wird sichergestellt, dass ein Knoten physisch auf einer Seite gespeichert wird Das Lesen eines Knotens ist nur ein I/O erforderlich. Unter der Annahme, dass die Höhe von B+Baum h ist, erfordert ein Abruf höchstens h-1 I/O (Wurzelknoten-residenter Speicher) und die Komplexität $O(h) = O(log_{M}N)$. In tatsächlichen Anwendungsszenarien ist M normalerweise groß und überschreitet häufig 100, sodass die Höhe des Baums im Allgemeinen klein ist und normalerweise nicht mehr als 3 beträgt.
Lassen Sie uns abschließend kurz die Funktionsweise des B+Tree-Knotens verstehen und ein allgemeines Verständnis für die Wartung des Index erlangen. Obwohl der Index die Abfrageeffizienz erheblich verbessern kann, ist er dennoch hilfreich Die Wartung des Index kostet Geld. Die Kosten sind sehr hoch, daher ist es besonders wichtig, Indizes vernünftig zu erstellen.
Nehmen wir immer noch den obigen Baum als Beispiel und gehen davon aus, dass jeder Knoten nur 4 interne Knoten speichern kann. Fügen Sie zunächst den ersten Knoten 28 ein, wie in der Abbildung unten gezeigt.
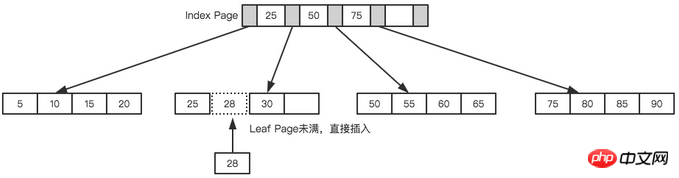
Weder die Blattseite noch die Indexseite ist voll
Dann Fügen Sie den nächsten ein. Für einen Knoten 70 haben wir nach der Abfrage auf der Indexseite erfahren, dass er in einen Blattknoten zwischen 50 und 70 eingefügt werden sollte, der Blattknoten jedoch voll ist. Zu diesem Zeitpunkt müssen wir eine Teilungsoperation durchführen. Der aktuelle Startpunkt des Blattknotens ist 50, daher wird der Zwischenwert zum Teilen der Blattknoten verwendet, wie in der folgenden Abbildung dargestellt.
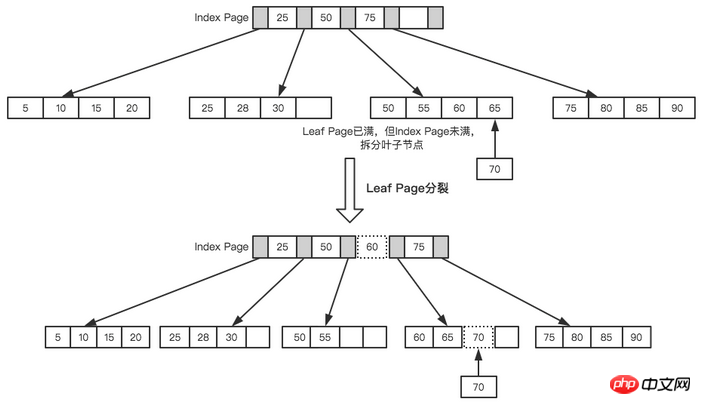
Blattseitenaufteilung
Schließlich einen Knoten 95 einfügen, dieses Mal Da sowohl die Indexseite als auch die Blattseite voll sind, sind zwei Teilungen erforderlich, wie in der folgenden Abbildung dargestellt.
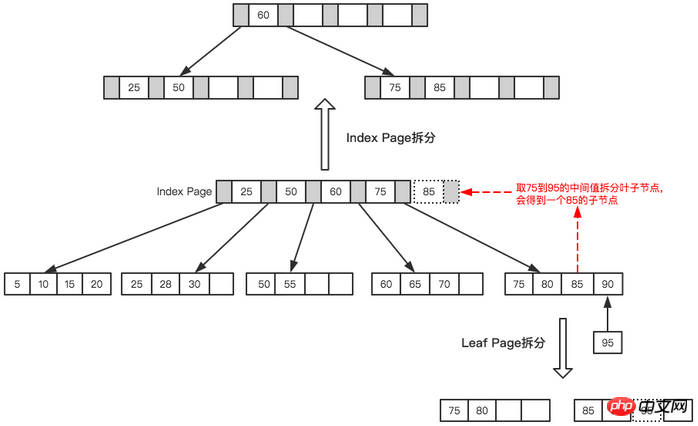
Blattseite und Indexseite geteilt
Endgültig nach Teilung So ein Baum entsteht.
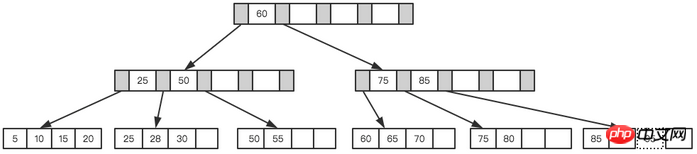
Endgültiger Baum
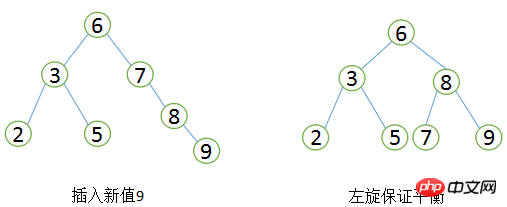
B+Baum Um das Gleichgewicht aufrechtzuerhalten, Für die neuen eingefügten Werte ist eine große Anzahl von Aufteilungs-Paging--Vorgängen erforderlich, und die Seitenaufteilung erfordert E/A-Vorgänge. Um die Seitenaufteilungsvorgänge so weit wie möglich zu reduzieren, bietet B+Tree auch eine ausgewogene Binärbaum. Rotationsfunktion. Wenn LeafPage voll ist, seine linken und rechten Geschwisterknoten jedoch nicht voll sind, möchte B+Tree den Teilungsvorgang nicht durchführen, sondern verschiebt den Datensatz auf die Geschwisterknoten der aktuellen Seite. Normalerweise wird zuerst das linke Geschwisterelement auf Rotationsvorgänge überprüft. Im zweiten Beispiel oben wird beispielsweise beim Einfügen von 70 keine Seitenteilung durchgeführt, sondern eine Linksdrehung.
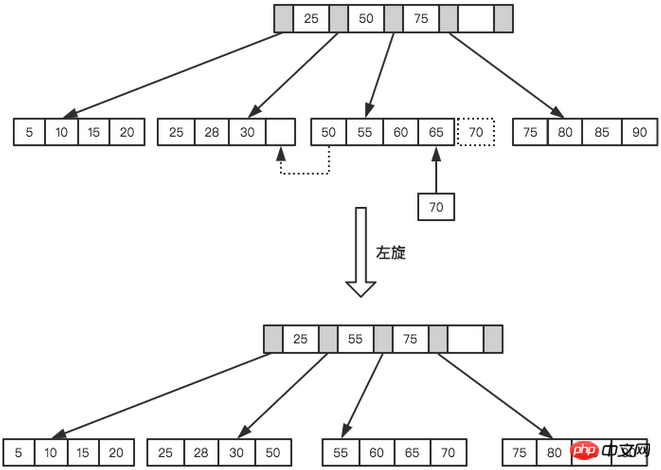
Linksdrehvorgang
Der Drehvorgang kann die Anzahl minimieren Die Anzahl der Seiten wird aufgeteilt, wodurch die Festplatten-E/A-Vorgänge während der Indexwartung reduziert und die Effizienz der Indexwartung verbessert werden. Es ist zu beachten, dass das Löschen von Knoten und das Einfügen von Knotentypen weiterhin Rotations- und Teilungsvorgänge erfordern, die hier nicht erläutert werden.
Hochleistungsstrategie
Durch das oben Gesagte glaube ich, dass Sie bereits ein allgemeines Verständnis der Datenstruktur von B+Tree haben, aber wie organisiert der Index in MySQL die Datenspeicherung? Zur Veranschaulichung anhand eines einfachen Beispiels: Wenn es die folgende Datentabelle gibt:
MySQL-Code
CREATE TABLE People(
Nachname varchar(50) nicht null,
Vorname varchar(50) nicht null,
Geburtsdatum nicht null,
gender enum(`m`,`f`) not null,
-
key(last_name,first_name,dob)
);
Für jede Datenzeile in der Tabelle enthält der Index die Werte von last_name, Spalten „first_name“ und „dob“ wie folgt. Das Diagramm zeigt, wie Indizes die Datenspeicherung organisieren.

Wie Indizes die Datenspeicherung organisieren, von: High Performance MySQL
Wie Sie sehen, wird der Index zunächst nach dem ersten Feld sortiert. Bei gleichen Namen erfolgt die Sortierung nach dem dritten Feld, dem Geburtsdatum. Aus diesem Grund gilt das „ganz links“-Prinzip. des Index festgelegt ist.
1. MySQL verwendet keine Indizes: nicht unabhängige Spalten
„Unabhängige Spalten“ bedeutet, dass Indexspalten kein Teil von Ausdrücken sein können kann es der Parameter der Funktion sein? Zum Beispiel:
MySQL-Code
wählen Sie * aus, wobei ID + 1 = 5
us Es ist leicht zu erkennen, dass es id = 4 entspricht, aber MySQL kann diesen Ausdruck nicht automatisch analysieren. Die Verwendung der Funktion ist der gleiche Grund.
2. Präfixindex
Wenn die Spalte sehr lang ist, können Sie normalerweise einige der Zeichen am Anfang indizieren, was effektiv Indexplatz sparen und die Indizierung verbessern kann Effizienz.
3. Mehrspaltige Indizes und Indexreihenfolge
In den meisten Fällen verbessert die Einrichtung unabhängiger Indizes für mehrere Spalten die Abfrageleistung nicht. Der Grund ist ganz einfach. MySQL weiß nicht, welchen Index es für eine bessere Abfrageeffizienz wählen soll. In älteren Versionen, z. B. vor MySQL 5.0, wählte es daher zufällig einen Index für eine Spalte aus, während neue Versionen eine Strategie für zusammengeführte Indizes verwenden. Um ein einfaches Beispiel zu geben: In einer Filmbesetzungsliste werden unabhängige Indizes für die Spalten „actor_id“ und „film_id“ erstellt, und dann gibt es die folgende Abfrage:
Mysql-Code
Wählen Sie film_id,actor_id aus film_actor aus, wobei Actor_id = 1 oder film_id = 1 ist
Die alte Version von MySQL wählt zufällig einen Index aus, die neue Version jedoch Folgende Optimierung:
Mysql-Code
select film_id,actor_id from film_actor where crime_id = 1
Union alle
wählen Sie film_id,actor_id aus film_actor, wobei film_id = 1 und academic_id <> 1
Wenn sich mehrere Indizes überschneiden (mehrere UND-Bedingungen), ist im Allgemeinen ein Index, der alle zugehörigen Spalten enthält, besser als mehrere unabhängige Indizes.
Wenn mehrere Indizes für gemeinsame Operationen (mehrere ODER-Bedingungen) verwendet werden, erfordern Vorgänge wie das Zusammenführen und Sortieren der Ergebnismenge eine große Menge an CPU- und Speicherressourcen, insbesondere wenn einige Indizes vorhanden sind Es ist nicht sehr selektiv, und wenn eine große Datenmenge zurückgegeben und zusammengeführt werden muss, sind die Abfragekosten höher. In diesem Fall ist es daher besser, einen vollständigen Tabellenscan durchzuführen.
Wenn Sie daher bei der Erklärung feststellen, dass eine Indexzusammenführung vorliegt (Verwendung von Union erscheint im Feld „Extra“), sollten Sie prüfen, ob die Abfrage und die Tabellenstruktur bereits optimal sind Sowohl die Abfrage als auch die Tabelle stellen ein Problem dar. Dies zeigt nur, dass der Index sehr schlecht aufgebaut ist. Sie sollten sorgfältig prüfen, ob der Index geeignet ist. Möglicherweise ist ein mehrspaltiger Index, der alle relevanten Spalten enthält, besser geeignet.
Wir haben bereits erwähnt, wie Indizes die Datenspeicherung organisieren. Wie Sie der Abbildung entnehmen können, ist die Reihenfolge des Index für die Abfrage von entscheidender Bedeutung Es ist offensichtlich, dass dies der Fall sein sollte. Die selektiveren Felder werden am Anfang des Index platziert, sodass die meisten Daten, die die Bedingungen nicht erfüllen, durch das erste Feld herausgefiltert werden können.
Zitat
Indexselektivität bezieht sich auf das Verhältnis eindeutiger Indexwerte zur Gesamtzahl der Datensätze in der Datentabelle. Je höher die Selektivität, desto höher die Abfrageeffizienz, denn je höher die Selektivität des Index, desto selektiver Index kann es MySQL ermöglichen, bei der Abfrage mehr Daten herauszufiltern. Die Selektivität des eindeutigen Index beträgt 1. Zu diesem Zeitpunkt ist die Indexselektivität am besten und die Leistung am besten.
Nachdem Sie das Konzept der Indexselektivität verstanden haben, ist es nicht schwer zu bestimmen, welches Feld die höhere Selektivität aufweist, indem Sie beispielsweise Folgendes überprüfen:
MySQL-Code
SELECT * FROM payment wobei staff_id = 2 und customer_id = 584
sein sollte erstellt Sollte der Index von (staff_id, customer_id) umgekehrt werden? Führen Sie die folgende Abfrage aus. Das Feld, dessen Selektivität näher bei 1 liegt, wird zuerst indiziert.
MySQL-Code
select count(distinct staff_id)/count(*) as staff_id_selectivity,
count(distinct customer_id)/count(*) as customer_id_selectivity,
count(*) from payment
In den meisten Fällen spricht nichts gegen die Anwendung dieses Prinzips, aber achten Sie dennoch darauf, ob es in Ihren Daten Sonderfälle gibt. Um ein einfaches Beispiel zu geben: Wenn Sie die Informationen von Benutzern abfragen möchten, die unter einer bestimmten Benutzergruppe gehandelt haben:
MySQL-Code
wählen Sie user_id aus dem Handel, wobei user_group_id = 1 und trade_amount > 0
MySQL hat den Index (user_group_id, trade_amount) für diese Abfrage ausgewählt, dies scheint nicht der Fall zu sein Es gibt keine Probleme, aber tatsächlich ist die Situation so, dass die meisten Daten in dieser Tabelle aus dem alten System migriert wurden. Da die Daten des neuen und des alten Systems nicht kompatibel sind, wird den aus dem alten System migrierten Daten eine Standardbenutzergruppe zugewiesen System. In diesem Fall ist die Anzahl der über den Index gescannten Zeilen grundsätzlich dieselbe wie beim vollständigen Tabellenscan, und der Index spielt keine Rolle.
Im Allgemeinen sind Faustregeln und Schlussfolgerungen in den meisten Fällen nützlich und können unsere Entwicklung und unser Design leiten, aber die tatsächliche Situation ist oft komplexer. Einige besondere Umstände können Ihr gesamtes Design zerstören .
4. Vermeiden Sie Mehrfachbereichsbedingungen
In der tatsächlichen Entwicklung verwenden wir häufig Mehrfachbereichsbedingungen, beispielsweise wenn wir Benutzer abfragen möchten, die sich innerhalb eines angemeldet haben Bestimmter Zeitraum:
Mys-Code
Benutzer auswählen, wobei Anmeldezeit > und Alter zwischen 18 und 30; >
- Die Der Index wird in der Reihenfolge der Spaltenwerte gespeichert, was besser ist, als jede Datenzeile zufällig von der Festplatte zu lesen. Die E/A ist viel geringer 6. Verwenden Sie den Index-Scan zum Sortieren. MySQL bietet zwei Möglichkeiten, geordnete Ergebnismengen zu erzeugen. Die zweite besteht darin, die durch Scannen erhaltenen Ergebnisse entsprechend der Indexreihenfolge durchzuführen sind natürlich geordnet. Wenn der Wert der Typspalte im EXPLAIN-Ergebnis index ist, bedeutet dies, dass zum Sortieren ein Indexscan verwendet wird.
- Das Scannen des Index selbst geht schnell, da Sie nur von einem Indexdatensatz zum nächsten benachbarten Datensatz wechseln müssen. Wenn der Index selbst jedoch nicht alle abzufragenden Spalten abdecken kann, müssen Sie jedes Mal, wenn Sie einen Indexdatensatz scannen, zur Tabelle zurückkehren, um die entsprechende Zeile abzufragen. Bei diesem Lesevorgang handelt es sich grundsätzlich um zufällige E/A-Vorgänge, daher ist das Lesen von Daten in Indexreihenfolge normalerweise langsamer als ein sequenzieller vollständiger Tabellenscan.
Nur wenn die Spaltenreihenfolge des Index vollständig mit der Reihenfolge der ORDER BY-Klausel übereinstimmt und auch die Sortierrichtung aller Spalten gleich ist, kann der Index zum Sortieren verwendet werden Ergebnisse. Wenn die Abfrage mehrere Tabellen verknüpfen muss, kann der Index nur dann zum Sortieren verwendet werden, wenn alle Felder, auf die in der ORDER BY-Klausel verwiesen wird, aus der ersten Tabelle stammen. Die Einschränkungen der ORDER BY-Klausel und der Abfrage sind dieselben und müssen die Anforderungen des Präfixes ganz links erfüllen (es gibt eine Ausnahme, dh die Spalte ganz links wird als Konstante angegeben. Das Folgende ist ein einfaches Beispiel). In anderen Fällen müssen Sortiervorgänge ausgeführt werden und die Indexsortierung kann nicht verwendet werden.
MySQL-Code
// Die Spalte ganz links ist eine Konstante, Index: (Datum, Personal-ID, Kunden-ID)
Wählen Sie „staff_id,customer_id“ aus der Demo aus, wobei Datum = „2015-06-01“ ist. Reihenfolge: „staff_id,customer_id“
7. Redundante und doppelte Indizes
Redundante Indizes beziehen sich auf Indizes desselben Typs, die für dieselben Spalten in derselben Reihenfolge erstellt wurden. Solche Indizes sollten so weit wie möglich vermieden und sofort nach der Entdeckung gelöscht werden. Wenn beispielsweise ein Index (A, B) vorhanden ist, ist die Erstellung des Index (A) ein redundanter Index. Redundante Indizes treten häufig auf, wenn einer Tabelle neue Indizes hinzugefügt werden. Beispielsweise erstellt jemand einen neuen Index (A, B), dieser Index erweitert jedoch nicht den vorhandenen Index (A).
In den meisten Fällen sollten Sie versuchen, bestehende Indizes zu erweitern, anstatt neue zu erstellen. Es gibt jedoch seltene Fälle, in denen Leistungserwägungen redundante Indizes erfordern, z. B. die Erweiterung eines vorhandenen Index, sodass dieser zu groß wird, was sich auf andere Abfragen auswirkt, die den Index verwenden.
8. Löschen Sie Indizes, die längere Zeit nicht verwendet wurden.
Es ist eine sehr gute Angewohnheit, regelmäßig einige Indizes zu löschen, die längere Zeit nicht verwendet wurden Zeit.
Ich werde hier beim Thema Indizierung aufhören. Abschließend möchte ich sagen, dass die Indizierung nicht immer das beste Werkzeug ist Der Nutzen überwiegt die Folgen. Indizes sind nur dann wirksam, wenn sie zusätzliche Arbeit erfordern. Bei sehr kleinen Tabellen ist ein einfacher vollständiger Tabellenscan effizienter. Für mittlere bis große Tabellen sind Indizes sehr effektiv. Bei sehr großen Tabellen steigen die Kosten für die Erstellung und Verwaltung von Indizes, und andere Techniken können effektiver sein, beispielsweise partitionierte Tabellen. Schließlich ist es eine Tugend, dies vor der Prüfung zu erklären.
Spezifische Typabfrageoptimierung
Optimierung der COUNT()-Abfrage
COUNT() ist möglicherweise die am meisten missverstandene Funktion. Es gibt zwei verschiedene Funktionen. Eine besteht darin, die Anzahl der Werte in einer bestimmten Spalte zu zählen, die andere darin, die Anzahl der Zeilen zu zählen. Beim Zählen von Spaltenwerten darf der Spaltenwert nicht leer sein und zählt nicht NULL. Wenn Sie bestätigen, dass der Ausdruck in Klammern nicht leer sein darf, zählen Sie tatsächlich die Anzahl der Zeilen. Das einfachste ist, dass bei Verwendung von COUNT(*) nicht alle Spalten erweitert werden, wie wir es uns vorgestellt haben. Tatsächlich werden alle Spalten ignoriert und alle Zeilen direkt gezählt.
Dies ist unser häufigstes Missverständnis. Wir geben eine Spalte in Klammern an, erwarten aber, dass das statistische Ergebnis die Anzahl der Zeilen ist. Wir glauben auch oft fälschlicherweise, dass die Leistung der ersteren sein wird besser. Dies ist jedoch nicht der Fall. Wenn Sie die Anzahl der Zeilen zählen möchten, verwenden Sie COUNT(*) direkt, was eine klare Bedeutung und eine bessere Leistung hat.
Manchmal erfordern einige Geschäftsszenarien keinen vollständig genauen COUNT-Wert und können durch einen ungefähren Wert ersetzt werden. Die Anzahl der durch EXPLAIN erhaltenen Zeilen ist eine gute Näherung und ist nicht erforderlich um EXPLAIN auszuführen. Führen Sie die Abfrage tatsächlich aus, daher sind die Kosten sehr gering. Im Allgemeinen erfordert die Ausführung von COUNT() das Scannen einer großen Anzahl von Zeilen, um genaue Daten zu erhalten. Daher ist eine Optimierung schwierig. Auf MySQL-Ebene kann nur der Index abgedeckt werden. Wenn das Problem nicht gelöst werden kann, kann es nur auf Architekturebene gelöst werden, z. B. durch Hinzufügen einer Übersichtstabelle oder Verwendung eines externen Cache-Systems wie redis.
Zugehörige Abfragen optimieren
In Big-Data-Szenarien werden Tabellen über ein redundantes Feld verknüpft, was eine bessere Leistung bietet als die direkte Verwendung von JOIN. Wenn Sie wirklich verwandte Abfragen verwenden müssen, müssen Sie besonders auf Folgendes achten:
Stellen Sie sicher, dass Indizes für die Spalten in den ON- und USING-Klauseln vorhanden sind. Bei der Erstellung von Indizes muss die Reihenfolge der Assoziationen berücksichtigt werden. Wenn Tabelle A und Tabelle B mithilfe von Spalte c verknüpft sind und die Zuordnungsreihenfolge des Optimierers A, B lautet, muss kein Index für die entsprechende Spalte von Tabelle A erstellt werden. Nicht verwendete Indizes bringen zusätzliche Belastungen mit sich, sofern keine anderen Gründe vorliegen. Sie müssen nur einen Index für die entsprechende Spalte der zweiten Tabelle in der Zuordnungssequenz erstellen (die spezifischen Gründe werden unten analysiert).
Stellen Sie sicher, dass alle Ausdrücke in GROUP BY und ORDER BY nur Spalten in einer Tabelle betreffen, damit MySQL Indizes zur Optimierung verwenden kann.
Um den ersten Tipp zur Optimierung verwandter Abfragen zu verstehen, müssen Sie verstehen, wie MySQL verwandte Abfragen durchführt. Die aktuelle Strategie zur Ausführung von MySQL-Assoziationen ist sehr einfach. Sie führt Assoziationsoperationen mit verschachtelten Schleifen für jede Assoziation aus, d usw., bis in allen Tabellen ein passendes -Verhalten gefunden wird. Anschließend werden basierend auf den übereinstimmenden Zeilen jeder Tabelle die in der Abfrage erforderlichen Spalten zurückgegeben.
Zu abstrakt? Nehmen Sie das obige Beispiel zur Veranschaulichung. Es gibt beispielsweise eine solche Abfrage:
Mysql-Code
SELECT A.xx,B.yy
FROM A INNER JOIN B USING(c)
WHERE A.xx IN (5,6)
Angenommen, MySQL führt Assoziationsoperationen gemäß der Assoziationsreihenfolge A und B in der Abfrage aus, dann kann der folgende Pseudocode verwendet werden, um darzustellen, wie MySQL diese Abfrage abschließt:
MySQL-Code
-
outer_iterator = SELECT A.xx,A.c FROM A WHERE A.xx IN (5,6);
outer_row = äußerer_iterator.next ;
while(outer_row) {
inner_iterator = SELECT B.yy FROM B WHERE B.c = äußere_row.c;
inner_row = inner_iterator.next;
while(inner_row) {
Ausgabe[inner_row.yy ,outer_row.xx];
inner_row = inner_iterator.next; 🎜>
- }
- Wie Sie sehen können, basiert die äußerste Abfrage auf der A.xx-Spalte, die zur Abfrage verwendet wird. Wenn ein Index für A.c vorhanden ist, wird nicht die gesamte zugehörige Abfrage verwendet. Wenn man sich die innere Abfrage ansieht, ist es offensichtlich, dass die Abfrage beschleunigt werden kann, wenn ein Index für B.c vorhanden ist, sodass nur ein Index für die entsprechende Spalte der zweiten Tabelle in der Assoziationssequenz erstellt werden muss.
- Limit-Paging optimieren
002
0 Datensätze abfragen und dann Es werden nur 20 Datensätze zurückgegeben und die ersten 10.000 Datensätze werden verworfen. Diese Kosten sind sehr hoch. Eine der einfachsten Möglichkeiten, diese Art von Abfrage zu optimieren, besteht darin, möglichst umfassende Indexscans zu verwenden, anstatt alle Spalten abzufragen. Führen Sie dann nach Bedarf eine entsprechende Abfrage durch und geben Sie alle Spalten zurück. Wenn der Versatz groß ist, wird die Effizienz erheblich verbessert. Betrachten Sie die folgende Abfrage: Mysql-CodeSELECT film_id,description FROM film ORDER BY title LIMIT 50,5; Wenn diese Tabelle sehr groß ist, dann wird diese Abfrage am besten wie folgt geändert:- Mysql-Code
- SELECT film_id FROM film ORDER BY title LIMIT 50,5
- ) AS tmp USING(film_id);
- Die verzögerte Zuordnung hier wird die Abfrageeffizienz erheblich verbessern, sodass MySQL so wenig Seiten wie möglich scannen kann. Nachdem Sie die Datensätze erhalten haben, auf die zugegriffen werden muss, geben Sie die erforderlichen Spalten entsprechend den zugehörigen Spalten in die Originaltabelle zurück.
- Wenn Sie manchmal ein Lesezeichen verwenden können, um den Ort aufzuzeichnen, an dem die Daten zuletzt abgerufen wurden, können Sie beim nächsten Mal direkt mit dem Scannen an dem vom Lesezeichen aufgezeichneten Ort beginnen, um dies zu vermeiden mit OFF SET
- SELECT id FROM t WHERE id >
-
Andere Optimierungsmethoden umfassen die Verwendung vorberechneter Übersichtstabellen oder die Verknüpfung mit einer redundanten Tabelle, die nur die Primärschlüsselspalten und die Spalten enthält, die sortiert werden müssen.
UNION optimieren
MySQLs Strategie zur Verarbeitung von UNION besteht darin, zunächst eine temporäre Tabelle zu erstellen, dann jedes Abfrageergebnis in die temporäre Tabelle einzufügen und schließlich die Abfrage auszuführen. Daher funktionieren viele Optimierungsstrategien in der UNION-Abfrage nicht gut. Es ist oft notwendig, WHERE-, LIMIT-, ORDER BY- und andere Klauseln manuell in jede Unterabfrage zu „schieben“, damit der Optimierer diese Bedingungen vollständig nutzen kann, um zuerst zu optimieren.
Sofern Sie den Server nicht unbedingt deduplizieren müssen, müssen Sie UNION ALL verwenden. Wenn kein ALL-Schlüsselwort vorhanden ist, fügt MySQL die DISTINCT-Option zur temporären Tabelle hinzu, was dazu führt, dass der gesamte Server dedupliziert wird Die zu deduplizierende temporäre Tabelle wird auf Eindeutigkeit überprüft, was sehr aufwendig ist. Selbst wenn das Schlüsselwort ALL verwendet wird, legt MySQL die Ergebnisse natürlich immer in einer temporären Tabelle ab, liest sie dann aus und gibt sie dann an den Client zurück. Obwohl dies beispielsweise in vielen Fällen nicht erforderlich ist, können manchmal die Ergebnisse jeder Unterabfrage direkt an den Client zurückgegeben werden.
Fazit
Zu verstehen, wie Abfragen ausgeführt werden und wo Zeit aufgewendet wird, gepaart mit etwas Wissen über den Optimierungsprozess, kann jedem helfen, die Prinzipien dahinter besser zu verstehen Gängige Optimierungstechniken. Ich hoffe, dass die Prinzipien und Beispiele in diesem Artikel Ihnen helfen können, Theorie und Praxis besser zu verbinden und mehr theoretisches Wissen in die Praxis umzusetzen.
Es gibt nicht viel mehr zu sagen. Ich lasse Sie mit zwei Fragen zurück, über die Sie nachdenken können. Das ist etwas, worüber jeder oft spricht. aber selten. Fragt sich jemand, warum?
Viele Programmierer werden diesen Standpunkt teilen: Versuchen Sie, keine gespeicherten Prozeduren zu verwenden sollte auf der Client-Seite platziert werden. Warum brauchen wir gespeicherte Prozeduren, da der Client diese Dinge tun kann?
JOIN selbst ist auch sehr praktisch. Fragen Sie es einfach direkt ab.
Referenzen
[1] Verfasst von Jiang Chengyao; MySQL Technology Insider-InnoDB Storage Engine; , 2013
[2] Baron Scbwartz et al. Übersetzt von Ninghai Yuanzhou Zhenxing und anderen; Electronic Industry Press, 2013[3] MySQL-Index aus B-/B+-Baumstruktur anzeigen
Das obige ist der detaillierte Inhalt vonMySQL-Optimierungsprinzipien. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!